 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Deep Embedding for Zero-Shot Learning
Aug 30, 2018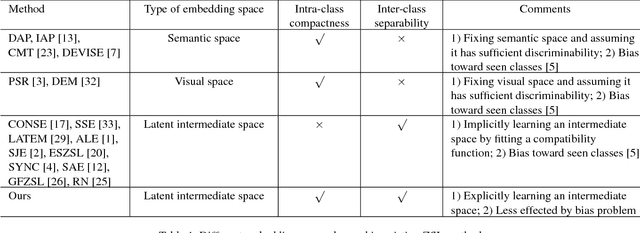
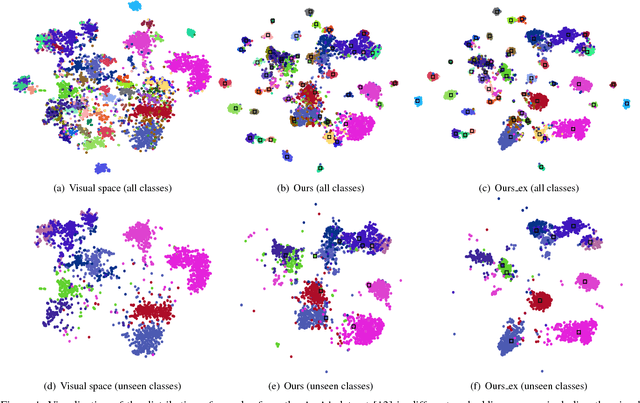

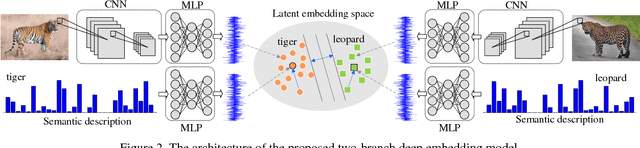
Zero-shot learning (ZSL) attempts to recognize visual samples of unseen classes by virtue of the semantic descriptions of those classes. We posit that the key to ZSL is to exploit an effective embedding space where 1) visual samples can be tightly centred around the semantic descriptions of classes that they belong to; 2) visual samples of different classes are separated from each other with a large enough margin. Towards this goal, we present a simple but surprisingly effective deep embedding model. In our model, we separately embed visual samples and semantic descriptions into a latent intermediate space such that visual samples not only coincide with associated semantic descriptions, but also can be correctly discriminated by a trainable linear classifier. By doing this, visual samples can be tightly centred around associated semantic descriptions and more importantly, they can be separated from other semantic descriptions with a large margin, thus leading to a new state-of-the-art for ZSL. Furthermore, due to lacking training samples, the generalization capacity of the learned embedding space to unseen classes can be further improved. To this end, we propose to upgrade our model with a refining strategy which progressively calibrates the embedding space based upon some test samples chosen from unseen classes with high-confidence pseudo labels, and ultimately improves the generalization capacity greatly. Experimental results on five benchmarks demonstrate the great advantage of our model over current state-of-the-art competitors. For example, on AwA1 dataset, our model improves the recognition accuracy on unseen classes by 16.9% in conventional ZSL setting and even by 38.6% in the generalized ZSL setting.