 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over Vision and Language: Exploring the Benefits of Supplemental Knowledge
Paper and Code
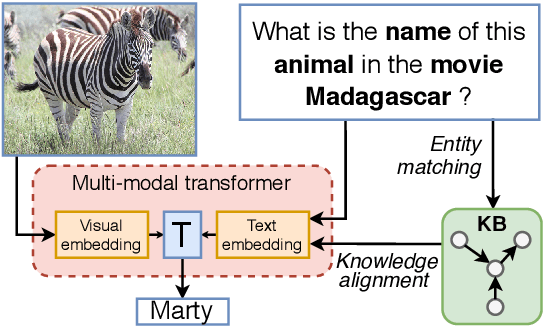
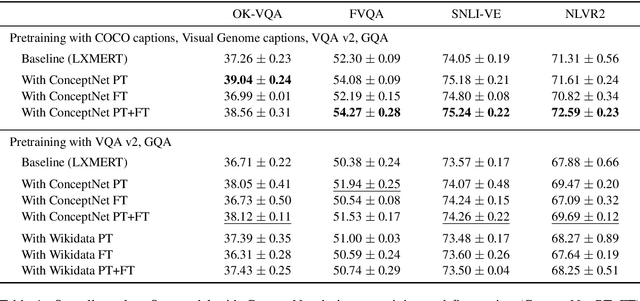
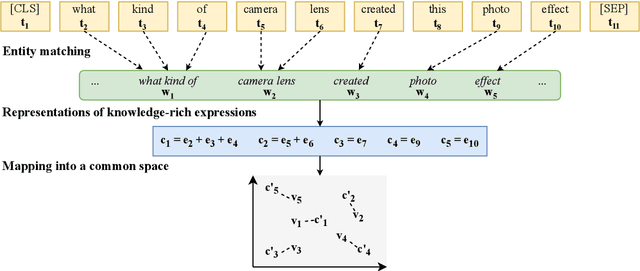
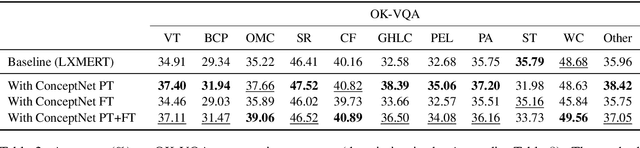
The limits of applicability of vision-and-language models are defined by the coverage of their training data. Tasks like vision question answering (VQA) often require commonsense and factual information beyond what can be learned from task-specific datasets. This paper investigates the injection of knowledge from general-purpose knowledge bases (KBs) into vision-and-language transformers. We use an auxiliary training objective that encourages the learned representations to align with graph embeddings of matching entities in a KB. We empirically study the relevance of various KBs to multiple tasks and benchmarks. The technique brings clear benefits to knowledge-demanding question answering tasks (OK-VQA, FVQA) by capturing semantic and relational knowledge absent from existing models. More surprisingly, the technique also benefits visual reasoning tasks (NLVR2, SNLI-VE). We perform probing experiments and show that the injection of additional knowledge regularizes the space of embeddings, which improves the representation of lexical and semantic similarities. The technique is model-agnostic and can expand the applicability of any vision-and-language transformer with minimal computational overhead.