 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnextractable Protocol Models: Collaborative Training and Inference without Weight Materialization
May 22, 2026We consider a decentralized setup in which the participants collaboratively train and serve a large neural network, and where each participant only processes a subset of the model. In this setup, we explore the possibility of unmaterializable weights, where a full weight set is never available to any one participant. We introduce Unextractable Protocol Models (UPMs): a training and inference framework that leverages the sharded model setup to ensure model shards (i.e., subsets) held by participants are incompatible at different time steps. UPMs periodically inject time-varying, random, invertible transforms at participant boundaries; preserving the overall network function yet rendering cross-time assemblies incoherent. On Qwen-2.5-0.5B and Llama-3.2-1B, 10,000 transforms leave FP32 perplexity unchanged ($Δ$PPL $< 0.01$; Jensen-Shannon drift $< 4 \times 10^{-5}$), and we show how to control growth for lower precision datatypes. Applying a transform every 30s adds 3% latency, 0.1% bandwidth, and 10% GPU-memory overhead at inference, while training overhead falls to 1.6% time and $< 1$% memory. We consider several attacks, showing that the requirements of direct attacks are impractical and easy to defend against, and that gradient-based fine-tuning of stitched partitions consumes $\geq 60$% of the tokens required to train from scratch. By enabling models to be collaboratively trained yet not extracted, UPMs make it practical to embed programmatic incentive mechanisms in community-driven decentralized training.
* Accepted at NeurIPS 2025. 34 pages, 6 figures (5 in main body, 1 in appendix). Alexander Long and Chamin Hewa Koneputugodage contributed equally
NuMuon: Nuclear-Norm-Constrained Muon for Compressible LLM Training
Mar 04, 2026The rapid progress of large language models (LLMs) is increasingly constrained by memory and deployment costs, motivating compression methods for practical deployment. Many state-of-the-art compression pipelines leverage the low-rank structure of trained weight matrices, a phenomenon often associated with the properties of popular optimizers such as Adam. In this context, Muon is a recently proposed optimizer that improves LLM pretraining via full-rank update steps, but its induced weight-space structure has not been characterized yet. In this work, we report a surprising empirical finding: despite imposing full-rank updates, Muon-trained models exhibit pronounced low-rank structure in their weight matrices and are readily compressible under standard pipelines. Motivated by this insight, we propose NuMuon, which augments Muon with a nuclear-norm constraint on the update direction, further constraining the learned weights toward low-rank structure. Across billion-parameter-scale models, we show that NuMuon increases weight compressibility and improves post-compression model quality under state-of-the-art LLM compression pipelines while retaining Muon's favorable convergence behavior.
SENTINEL: Stagewise Integrity Verification for Pipeline Parallel Decentralized Training
Mar 03, 2026Decentralized training introduces critical security risks when executed across untrusted, geographically distributed nodes. While existing Byzantine-tolerant literature addresses data parallel (DP) training through robust aggregation methods, pipeline parallelism (PP) presents fundamentally distinct challenges. In PP, model layers are distributed across workers where the activations and their gradients flow between stages rather than being aggregated, making traditional DP approaches inapplicable. We propose SENTINEL, a verification mechanism for PP training without computation duplication. SENTINEL employs lightweight momentum-based monitoring using exponential moving averages (EMAs) to detect corrupted inter-stage communication. Unlike existing Byzantine-tolerant approaches for DP that aggregate parameter gradients across replicas, our approach verifies sequential activation/gradient transmission between layers. We provide theoretical convergence guarantees for this new setting that recovers classical convergence rates when relaxed to standard training. Experiments demonstrate successful training of up to 4B-parameter LLMs across untrusted distributed environments with up to 176 workers while maintaining model convergence and performance.
AsyncMesh: Fully Asynchronous Optimization for Data and Pipeline Parallelism
Jan 30, 2026Data and pipeline parallelism are key strategies for scaling neural network training across distributed devices, but their high communication cost necessitates co-located computing clusters with fast interconnects, limiting their scalability. We address this communication bottleneck by introducing asynchronous updates across both parallelism axes, relaxing the co-location requirement at the expense of introducing staleness between pipeline stages and data parallel replicas. To mitigate staleness, for pipeline parallelism, we adopt a weight look-ahead approach, and for data parallelism, we introduce an asynchronous sparse averaging method equipped with an exponential moving average based correction mechanism. We provide convergence guarantees for both sparse averaging and asynchronous updates. Experiments on large-scale language models (up to \em 1B parameters) demonstrate that our approach matches the performance of the fully synchronous baseline, while significantly reducing communication overhead.
Nesterov Method for Asynchronous Pipeline Parallel Optimization
May 02, 2025Pipeline Parallelism (PP) enables large neural network training on small, interconnected devices by splitting the model into multiple stages. To maximize pipeline utilization, asynchronous optimization is appealing as it offers 100% pipeline utilization by construction. However, it is inherently challenging as the weights and gradients are no longer synchronized, leading to stale (or delayed) gradients. To alleviate this, we introduce a variant of Nesterov Accelerated Gradient (NAG) for asynchronous optimization in PP. Specifically, we modify the look-ahead step in NAG to effectively address the staleness in gradients. We theoretically prove that our approach converges at a sublinear rate in the presence of fixed delay in gradients. Our experiments on large-scale language modelling tasks using decoder-only architectures with up to 1B parameters, demonstrate that our approach significantly outperforms existing asynchronous methods, even surpassing the synchronous baseline.
Protocol Learning, Decentralized Frontier Risk and the No-Off Problem
Dec 10, 2024Frontier models are currently developed and distributed primarily through two channels: centralized proprietary APIs or open-sourcing of pre-trained weights. We identify a third paradigm - Protocol Learning - where models are trained across decentralized networks of incentivized participants. This approach has the potential to aggregate orders of magnitude more computational resources than any single centralized entity, enabling unprecedented model scales and capabilities. However, it also introduces novel challenges: heterogeneous and unreliable nodes, malicious participants, the need for unextractable models to preserve incentives, and complex governance dynamics. To date, no systematic analysis has been conducted to assess the feasibility of Protocol Learning or the associated risks, particularly the 'No-Off Problem' arising from the inability to unilaterally halt a collectively trained model. We survey recent technical advances that suggest decentralized training may be feasible - covering emerging communication-efficient strategies and fault-tolerant methods - while highlighting critical open problems that remain. Contrary to the notion that decentralization inherently amplifies frontier risks, we argue that Protocol Learning's transparency, distributed governance, and democratized access ultimately reduce these risks compared to today's centralized regimes.
A Sampling Theory Perspective on Activations for Implicit Neural Representations
Feb 08, 2024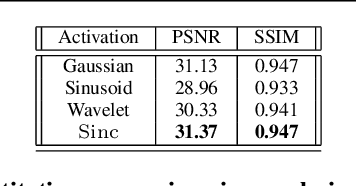
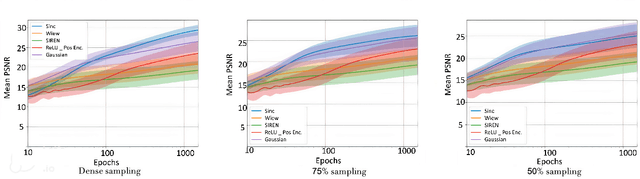

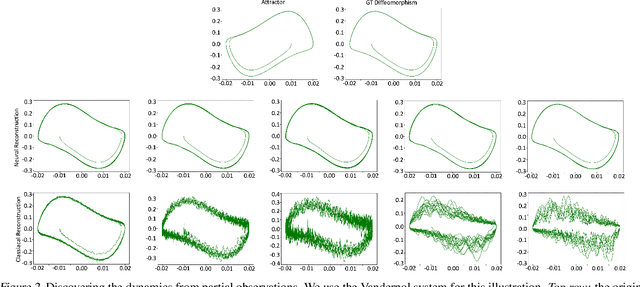
Implicit Neural Representations (INRs) have gained popularity for encoding signals as compact, differentiable entities. While commonly using techniques like Fourier positional encodings or non-traditional activation functions (e.g., Gaussian, sinusoid, or wavelets) to capture high-frequency content, their properties lack exploration within a unified theoretical framework. Addressing this gap, we conduct a comprehensive analysis of these activations from a sampling theory perspective. Our investigation reveals that sinc activations, previously unused in conjunction with INRs, are theoretically optimal for signal encoding. Additionally, we establish a connection between dynamical systems and INRs, leveraging sampling theory to bridge these two paradigms.
Fast and Data Efficient Reinforcement Learning from Pixels via Non-Parametric Value Approximation
Mar 07, 2022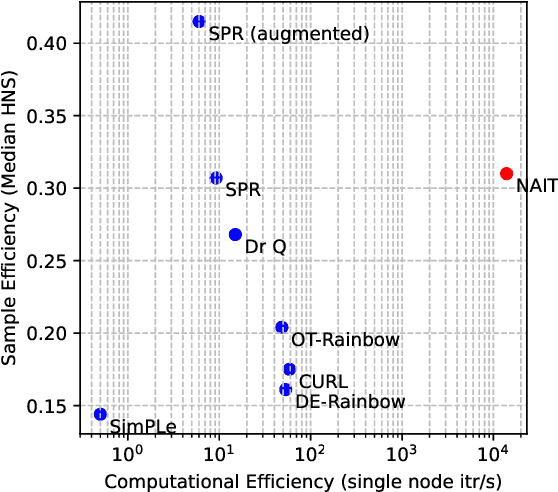
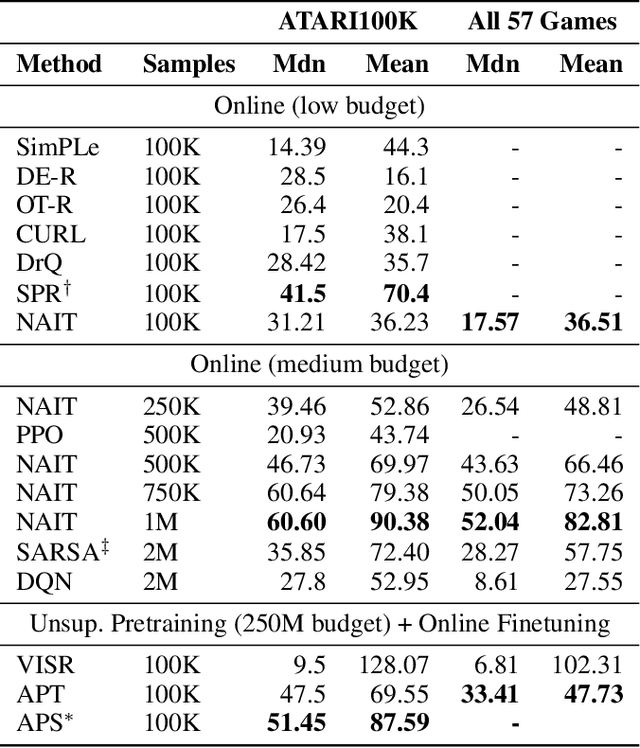
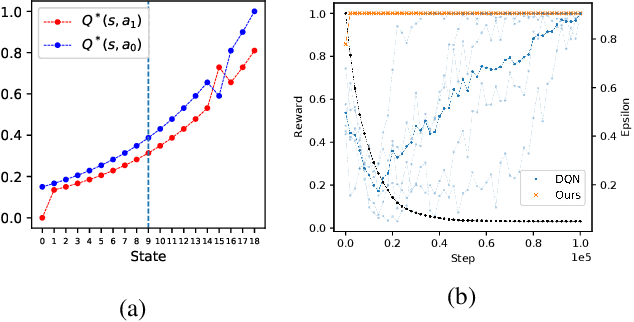
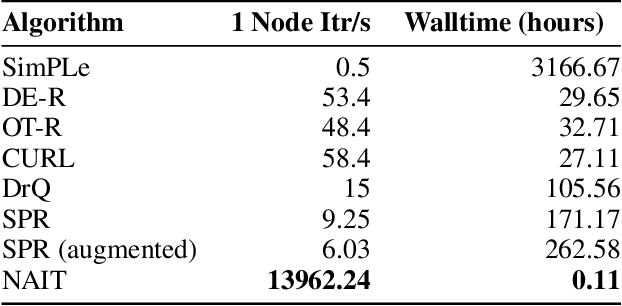
We present Nonparametric Approximation of Inter-Trace returns (NAIT), a Reinforcement Learning algorithm for discrete action, pixel-based environments that is both highly sample and computation efficient. NAIT is a lazy-learning approach with an update that is equivalent to episodic Monte-Carlo on episode completion, but that allows the stable incorporation of rewards while an episode is ongoing. We make use of a fixed domain-agnostic representation, simple distance based exploration and a proximity graph-based lookup to facilitate extremely fast execution. We empirically evaluate NAIT on both the 26 and 57 game variants of ATARI100k where, despite its simplicity, it achieves competitive performance in the online setting with greater than 100x speedup in wall-time.
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022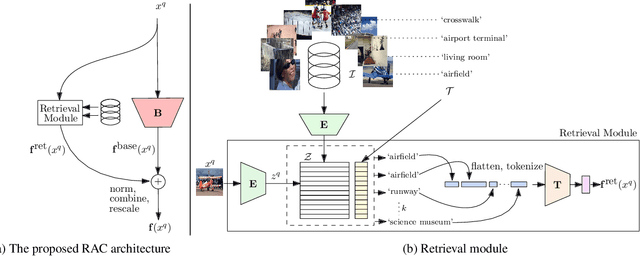
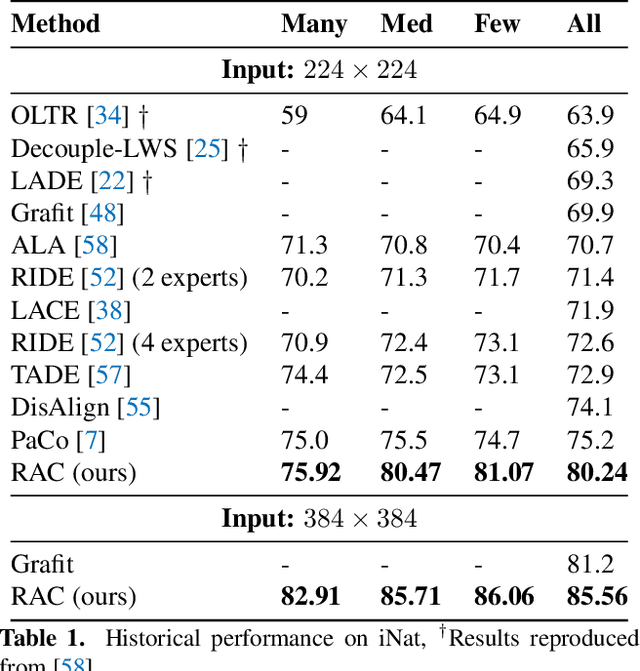
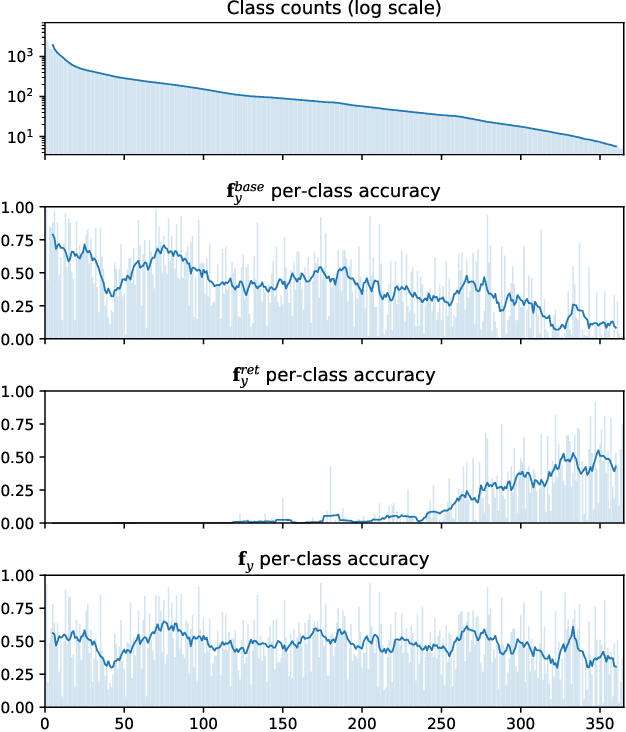
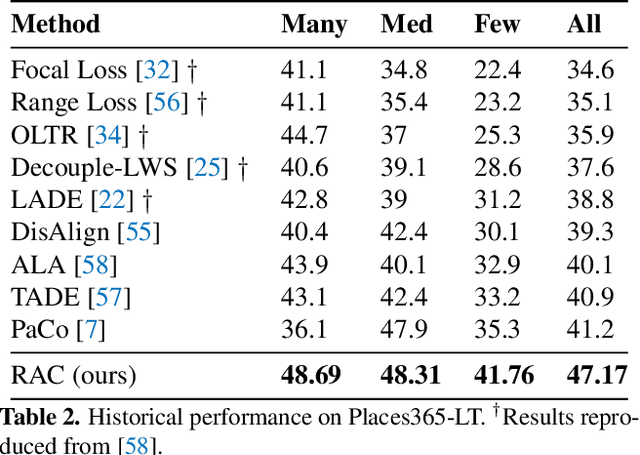
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.