 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven construction of a generalized kinetic collision operator from molecular dynamics
Mar 31, 2025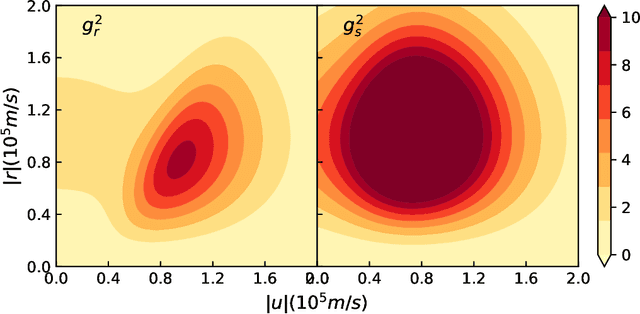
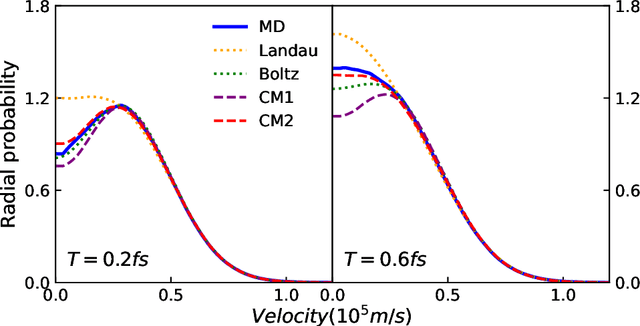
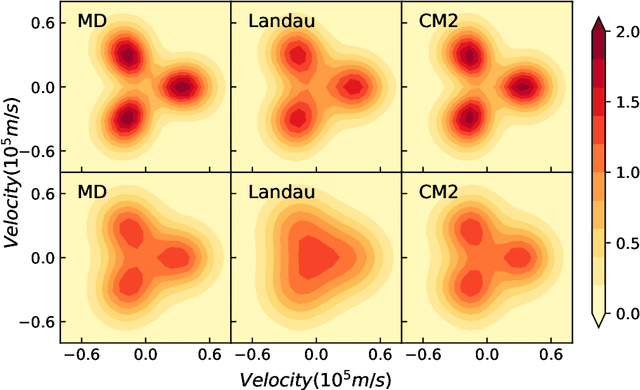
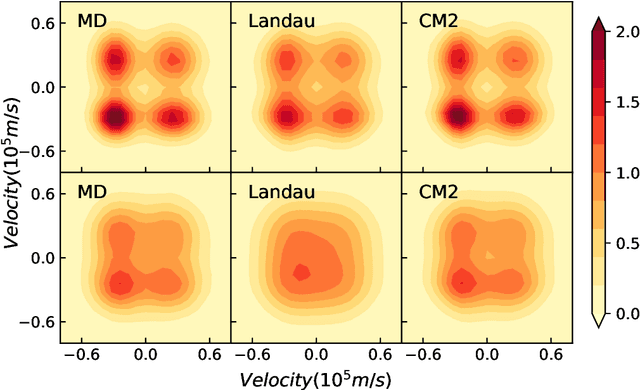
We introduce a data-driven approach to learn a generalized kinetic collision operator directly from molecular dynamics. Unlike the conventional (e.g., Landau) models, the present operator takes an anisotropic form that accounts for a second energy transfer arising from the collective interactions between the pair of collision particles and the environment. Numerical results show that preserving the broadly overlooked anisotropic nature of the collision energy transfer is crucial for predicting the plasma kinetics with non-negligible correlations, where the Landau model shows limitations.
OffsetOPT: Explicit Surface Reconstruction without Normals
Mar 20, 2025



Neural surface reconstruction has been dominated by implicit representations with marching cubes for explicit surface extraction. However, those methods typically require high-quality normals for accurate reconstruction. We propose OffsetOPT, a method that reconstructs explicit surfaces directly from 3D point clouds and eliminates the need for point normals. The approach comprises two stages: first, we train a neural network to predict surface triangles based on local point geometry, given uniformly distributed training point clouds. Next, we apply the frozen network to reconstruct surfaces from unseen point clouds by optimizing a per-point offset to maximize the accuracy of triangle predictions. Compared to state-of-the-art methods, OffsetOPT not only excels at reconstructing overall surfaces but also significantly preserves sharp surface features. We demonstrate its accuracy on popular benchmarks, including small-scale shapes and large-scale open surfaces.
Level-Set Parameters: Novel Representation for 3D Shape Analysis
Dec 18, 2024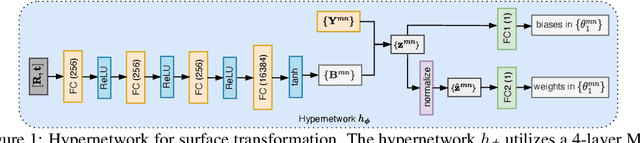

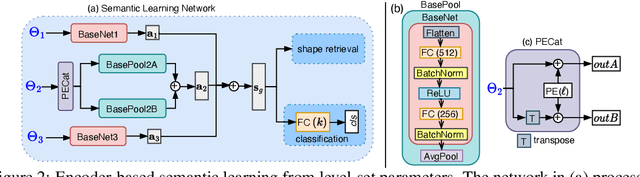
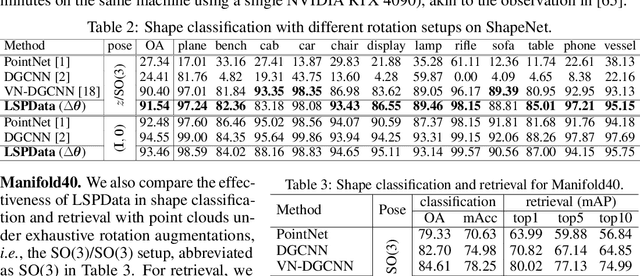
3D shape analysis has been largely focused on traditional 3D representations of point clouds and meshes, but the discrete nature of these data makes the analysis susceptible to variations in input resolutions. Recent development of neural fields brings in level-set parameters from signed distance functions as a novel, continuous, and numerical representation of 3D shapes, where the shape surfaces are defined as zero-level-sets of those functions. This motivates us to extend shape analysis from the traditional 3D data to these novel parameter data. Since the level-set parameters are not Euclidean like point clouds, we establish correlations across different shapes by formulating them as a pseudo-normal distribution, and learn the distribution prior from the respective dataset. To further explore the level-set parameters with shape transformations, we propose to condition a subset of these parameters on rotations and translations, and generate them with a hypernetwork. This simplifies the pose-related shape analysis compared to using traditional data. We demonstrate the promise of the novel representations through applications in shape classification (arbitrary poses), retrieval, and 6D object pose estimation. Code and data in this research are provided at https://github.com/EnyaHermite/LevelSetParamData.
On the generalization ability of coarse-grained molecular dynamics models for non-equilibrium processes
Sep 17, 2024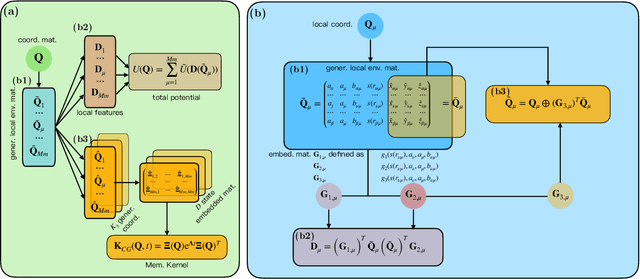
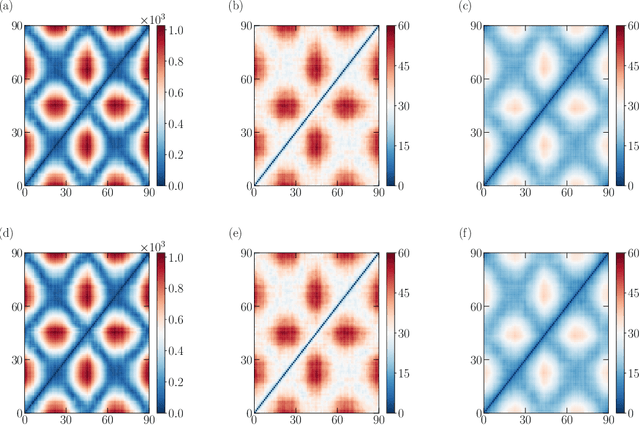
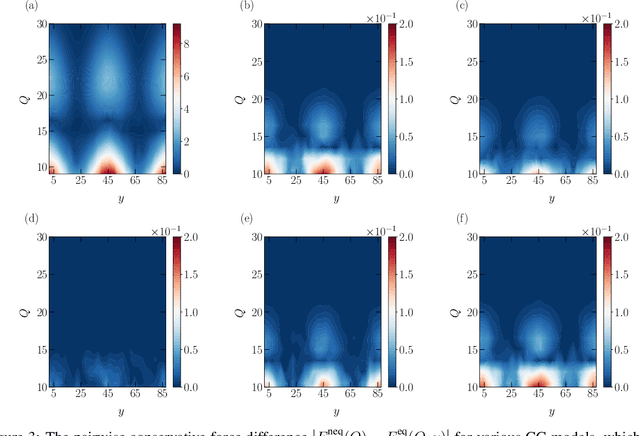
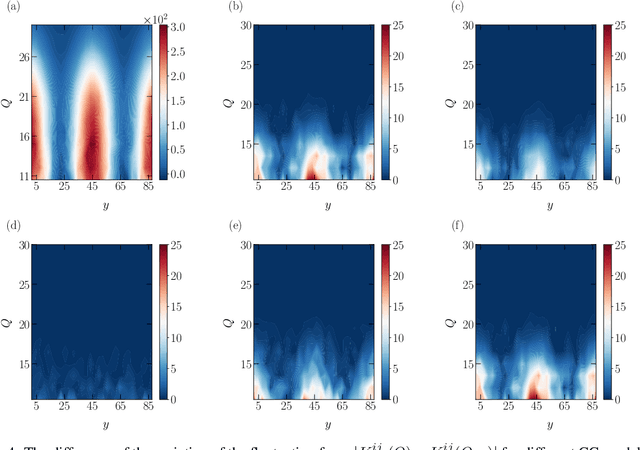
One essential goal of constructing coarse-grained molecular dynamics (CGMD) models is to accurately predict non-equilibrium processes beyond the atomistic scale. While a CG model can be constructed by projecting the full dynamics onto a set of resolved variables, the dynamics of the CG variables can recover the full dynamics only when the conditional distribution of the unresolved variables is close to the one associated with the particular projection operator. In particular, the model's applicability to various non-equilibrium processes is generally unwarranted due to the inconsistency in the conditional distribution. Here, we present a data-driven approach for constructing CGMD models that retain certain generalization ability for non-equilibrium processes. Unlike the conventional CG models based on pre-selected CG variables (e.g., the center of mass), the present CG model seeks a set of auxiliary CG variables based on the time-lagged independent component analysis to minimize the entropy contribution of the unresolved variables. This ensures the distribution of the unresolved variables under a broad range of non-equilibrium conditions approaches the one under equilibrium. Numerical results of a polymer melt system demonstrate the significance of this broadly-overlooked metric for the model's generalization ability, and the effectiveness of the present CG model for predicting the complex viscoelastic responses under various non-equilibrium flows.
AlphaDou: High-Performance End-to-End Doudizhu AI Integrating Bidding
Jul 14, 2024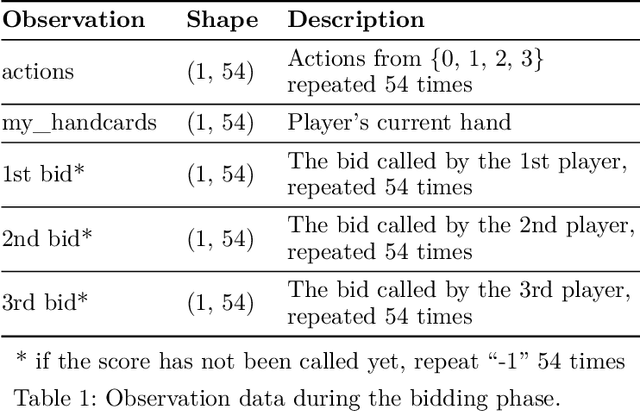
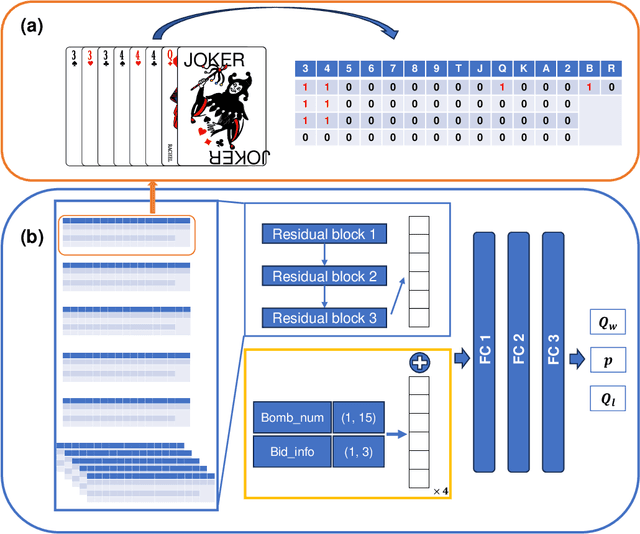
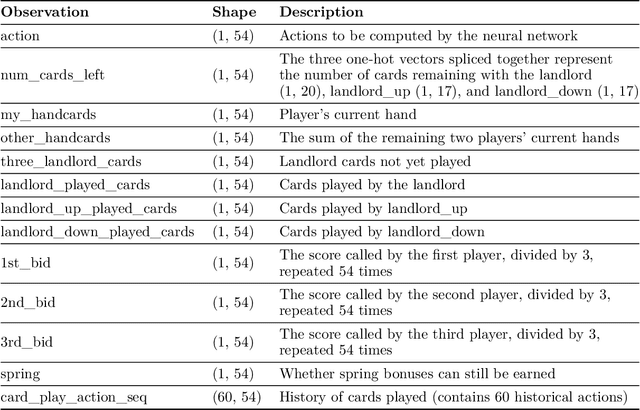
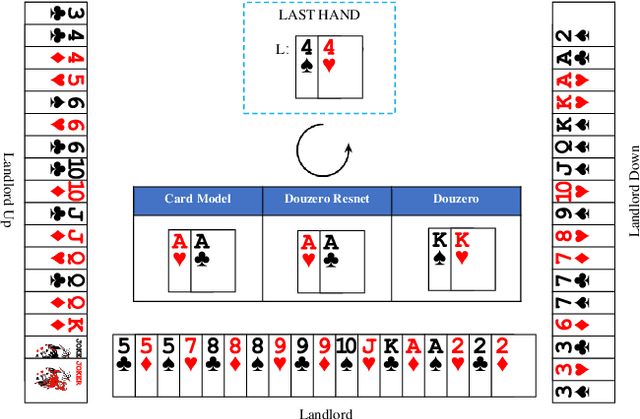
Artificial intelligence for card games has long been a popular topic in AI research. In recent years, complex card games like Mahjong and Texas Hold'em have been solved, with corresponding AI programs reaching the level of human experts. However, the game of Dou Di Zhu presents significant challenges due to its vast state/action space and unique characteristics involving reasoning about competition and cooperation, making the game extremely difficult to solve.The RL model DouZero, trained using the Deep Monte Carlo algorithm framework, has shown excellent performance in DouDiZhu. However, there are differences between its simplified game environment and the actual Dou Di Zhu environment, and its performance is still a considerable distance from that of human experts. This paper modifies the Deep Monte Carlo algorithm framework by using reinforcement learning to obtain a neural network that simultaneously estimates win rates and expectations. The action space is pruned using expectations, and strategies are generated based on win rates. This RL model is trained in a realistic DouDiZhu environment and achieves a state-of-the-art level among publicly available models.
Consensus-based construction of high-dimensional free energy surface
Nov 30, 2023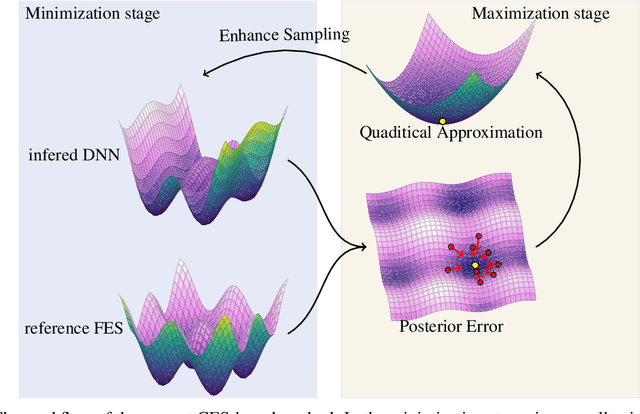
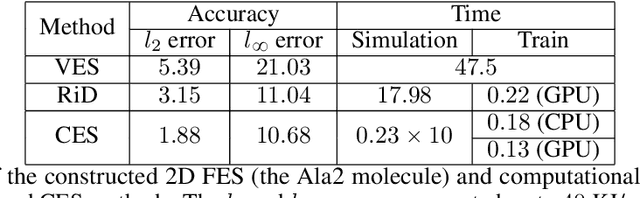
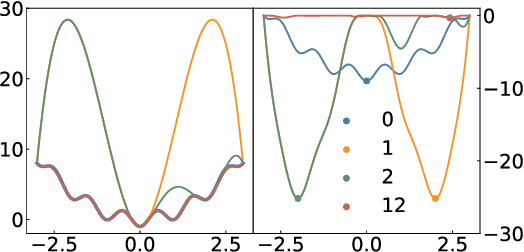
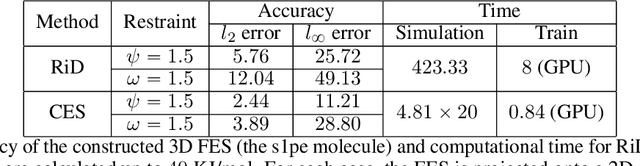
One essential problem in quantifying the collective behaviors of molecular systems lies in the accurate construction of free energy surfaces (FESs). The main challenges arise from the prevalence of energy barriers and the high dimensionality. Existing approaches are often based on sophisticated enhanced sampling methods to establish efficient exploration of the full-phase space. On the other hand, the collection of optimal sample points for the numerical approximation of FESs remains largely under-explored, where the discretization error could become dominant for systems with a large number of collective variables (CVs). We propose a consensus sampling-based approach by reformulating the construction as a minimax problem which simultaneously optimizes the function representation and the training set. In particular, the maximization step establishes a stochastic interacting particle system to achieve the adaptive sampling of the max-residue regime by modulating the exploitation of the Laplace approximation of the current loss function and the exploration of the uncharted phase space; the minimization step updates the FES approximation with the new training set. By iteratively solving the minimax problem, the present method essentially achieves an adversarial learning of the FESs with unified tasks for both phase space exploration and posterior error-enhanced sampling. We demonstrate the method by constructing the FESs of molecular systems with a number of CVs up to 30.
Training with Product Digital Twins for AutoRetail Checkout
Aug 18, 2023



Automating the checkout process is important in smart retail, where users effortlessly pass products by hand through a camera, triggering automatic product detection, tracking, and counting. In this emerging area, due to the lack of annotated training data, we introduce a dataset comprised of product 3D models, which allows for fast, flexible, and large-scale training data generation through graphic engine rendering. Within this context, we discern an intriguing facet, because of the user "hands-on" approach, bias in user behavior leads to distinct patterns in the real checkout process. The existence of such patterns would compromise training effectiveness if training data fail to reflect the same. To address this user bias problem, we propose a training data optimization framework, i.e., training with digital twins (DtTrain). Specifically, we leverage the product 3D models and optimize their rendering viewpoint and illumination to generate "digital twins" that visually resemble representative user images. These digital twins, inherit product labels and, when augmented, form the Digital Twin training set (DT set). Because the digital twins individually mimic user bias, the resulting DT training set better reflects the characteristics of the target scenario and allows us to train more effective product detection and tracking models. In our experiment, we show that DT set outperforms training sets created by existing dataset synthesis methods in terms of counting accuracy. Moreover, by combining DT set with pseudo-labeled real checkout data, further improvement is observed. The code is available at https://github.com/yorkeyao/Automated-Retail-Checkout.
Large-scale Training Data Search for Object Re-identification
Mar 28, 2023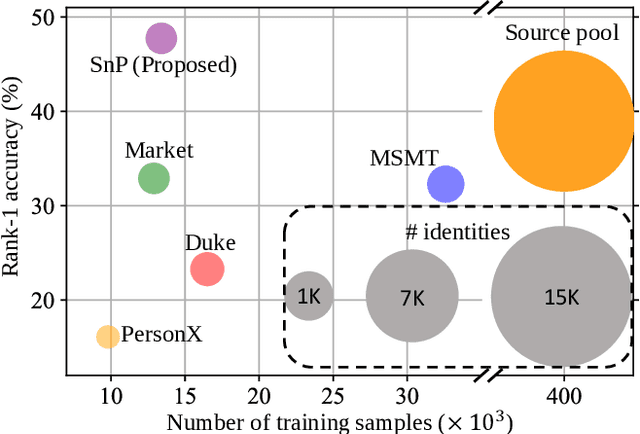
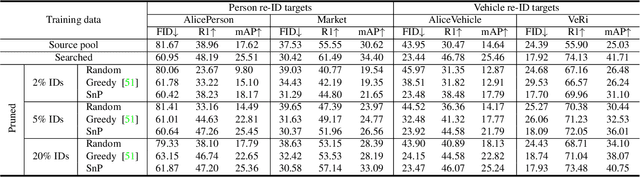
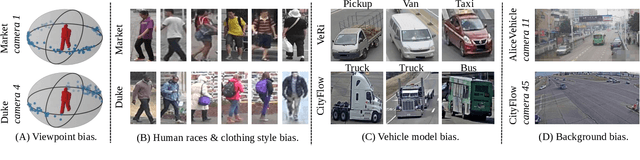
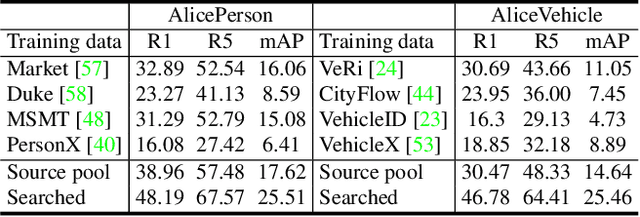
We consider a scenario where we have access to the target domain, but cannot afford on-the-fly training data annotation, and instead would like to construct an alternative training set from a large-scale data pool such that a competitive model can be obtained. We propose a search and pruning (SnP) solution to this training data search problem, tailored to object re-identification (re-ID), an application aiming to match the same object captured by different cameras. Specifically, the search stage identifies and merges clusters of source identities which exhibit similar distributions with the target domain. The second stage, subject to a budget, then selects identities and their images from the Stage I output, to control the size of the resulting training set for efficient training. The two steps provide us with training sets 80\% smaller than the source pool while achieving a similar or even higher re-ID accuracy. These training sets are also shown to be superior to a few existing search methods such as random sampling and greedy sampling under the same budget on training data size. If we release the budget, training sets resulting from the first stage alone allow even higher re-ID accuracy. We provide interesting discussions on the specificity of our method to the re-ID problem and particularly its role in bridging the re-ID domain gap. The code is available at https://github.com/yorkeyao/SnP.
CircNet: Meshing 3D Point Clouds with Circumcenter Detection
Jan 23, 2023Reconstructing 3D point clouds into triangle meshes is a key problem in computational geometry and surface reconstruction. Point cloud triangulation solves this problem by providing edge information to the input points. Since no vertex interpolation is involved, it is beneficial to preserve sharp details on the surface. Taking advantage of learning-based techniques in triangulation, existing methods enumerate the complete combinations of candidate triangles, which is both complex and inefficient. In this paper, we leverage the duality between a triangle and its circumcenter, and introduce a deep neural network that detects the circumcenters to achieve point cloud triangulation. Specifically, we introduce multiple anchor priors to divide the neighborhood space of each point. The neural network then learns to predict the presences and locations of circumcenters under the guidance of those anchors. We extract the triangles dual to the detected circumcenters to form a primitive mesh, from which an edge-manifold mesh is produced via simple post-processing. Unlike existing learning-based triangulation methods, the proposed method bypasses an exhaustive enumeration of triangle combinations and local surface parameterization. We validate the efficiency, generalization, and robustness of our method on prominent datasets of both watertight and open surfaces. The code and trained models are provided at https://github.com/Ruitao-L/CircNet.
DeePN$^2$: A deep learning-based non-Newtonian hydrodynamic model
Dec 29, 2021
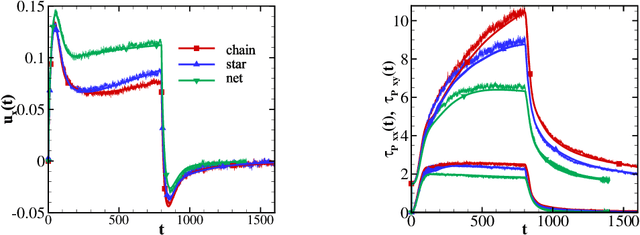
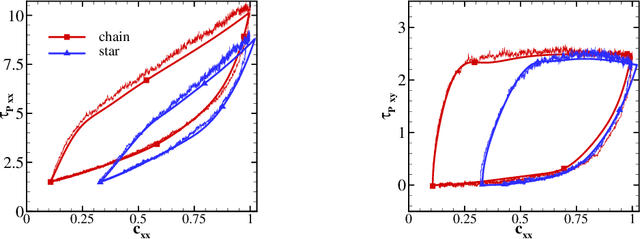
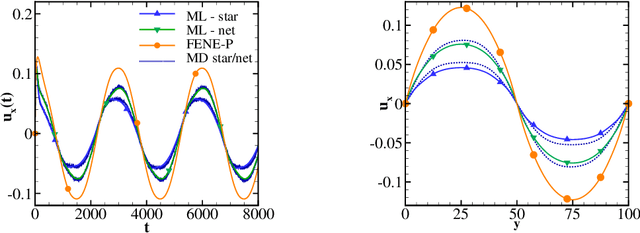
A long standing problem in the modeling of non-Newtonian hydrodynamics is the availability of reliable and interpretable hydrodynamic models that faithfully encode the underlying micro-scale polymer dynamics. The main complication arises from the long polymer relaxation time, the complex molecular structure, and heterogeneous interaction. DeePN$^2$, a deep learning-based non-Newtonian hydrodynamic model, has been proposed and has shown some success in systematically passing the micro-scale structural mechanics information to the macro-scale hydrodynamics for suspensions with simple polymer conformation and bond potential. The model retains a multi-scaled nature by mapping the polymer configurations into a set of symmetry-preserving macro-scale features. The extended constitutive laws for these macro-scale features can be directly learned from the kinetics of their micro-scale counterparts. In this paper, we carry out further study of DeePN$^2$ using more complex micro-structural models. We show that DeePN$^2$ can faithfully capture the broadly overlooked viscoelastic differences arising from the specific molecular structural mechanics without human intervention.