 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Training Data Search for Object Re-identification
Paper and Code
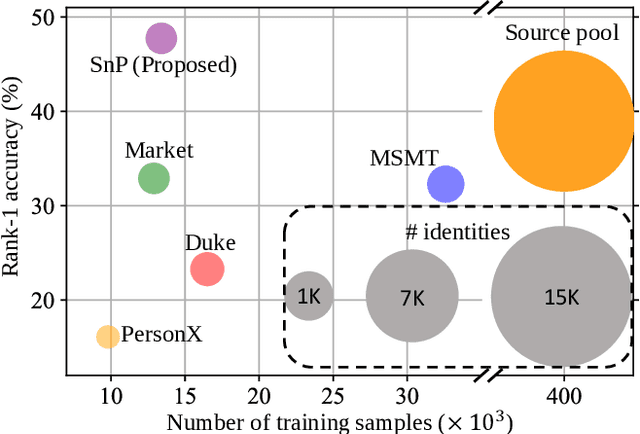
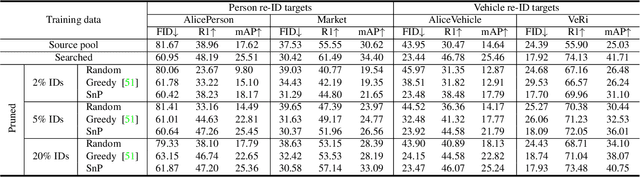
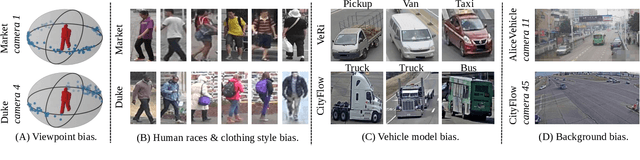
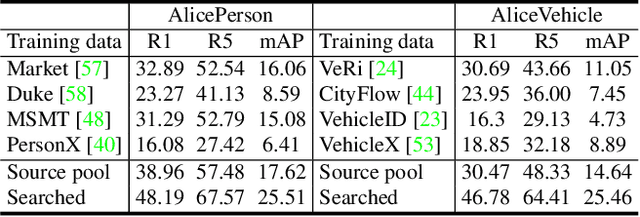
We consider a scenario where we have access to the target domain, but cannot afford on-the-fly training data annotation, and instead would like to construct an alternative training set from a large-scale data pool such that a competitive model can be obtained. We propose a search and pruning (SnP) solution to this training data search problem, tailored to object re-identification (re-ID), an application aiming to match the same object captured by different cameras. Specifically, the search stage identifies and merges clusters of source identities which exhibit similar distributions with the target domain. The second stage, subject to a budget, then selects identities and their images from the Stage I output, to control the size of the resulting training set for efficient training. The two steps provide us with training sets 80\% smaller than the source pool while achieving a similar or even higher re-ID accuracy. These training sets are also shown to be superior to a few existing search methods such as random sampling and greedy sampling under the same budget on training data size. If we release the budget, training sets resulting from the first stage alone allow even higher re-ID accuracy. We provide interesting discussions on the specificity of our method to the re-ID problem and particularly its role in bridging the re-ID domain gap. The code is available at https://github.com/yorkeyao/SnP.