 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFVQA: Fact-based Visual Question Answering
Paper and Code
Aug 08, 2017
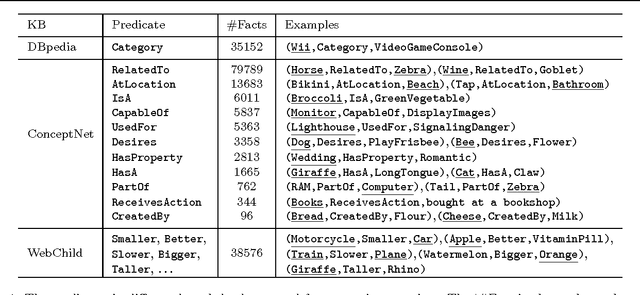
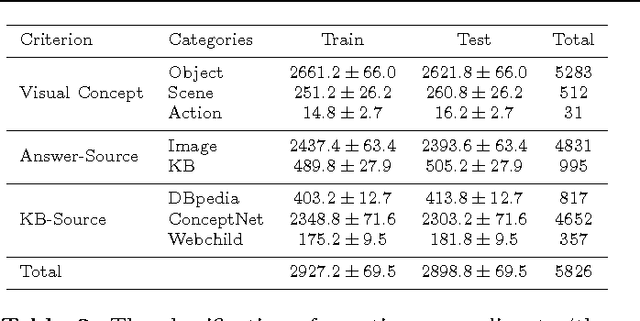
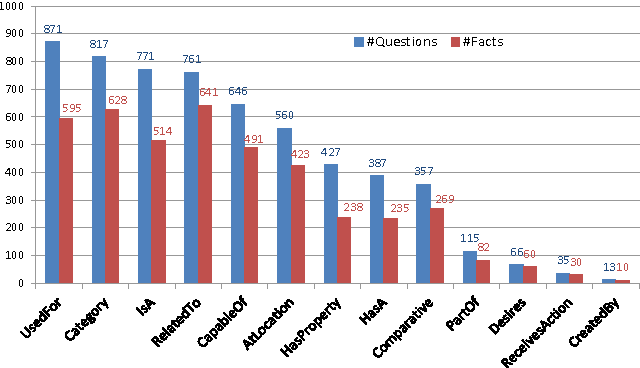
Visual Question Answering (VQA) has attracted a lot of attention in both Computer Vision and Natural Language Processing communities, not least because it offers insight into the relationships between two important sources of information. Current datasets, and the models built upon them, have focused on questions which are answerable by direct analysis of the question and image alone. The set of such questions that require no external information to answer is interesting, but very limited. It excludes questions which require common sense, or basic factual knowledge to answer, for example. Here we introduce FVQA, a VQA dataset which requires, and supports, much deeper reasoning. FVQA only contains questions which require external information to answer. We thus extend a conventional visual question answering dataset, which contains image-question-answerg triplets, through additional image-question-answer-supporting fact tuples. The supporting fact is represented as a structural triplet, such as <Cat,CapableOf,ClimbingTrees>. We evaluate several baseline models on the FVQA dataset, and describe a novel model which is capable of reasoning about an image on the basis of supporting facts.