 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMCOMET: A Large-Scale Multimodal Commonsense Knowledge Graph for Contextual Reasoning
Mar 01, 2026We present MMCOMET, the first multimodal commonsense knowledge graph (MMKG) that integrates physical, social, and eventive knowledge. MMCOMET extends the ATOMIC2020 knowledge graph to include a visual dimension, through an efficient image retrieval process, resulting in over 900K multimodal triples. This new resource addresses a major limitation of existing MMKGs in supporting complex reasoning tasks like image captioning and storytelling. Through a standard visual storytelling experiment, we show that our holistic approach enables the generation of richer, coherent, and contextually grounded stories than those produced using text-only knowledge. This resource establishes a new foundation for multimodal commonsense reasoning and narrative generation.
SoTCKGE:Continual Knowledge Graph Embedding Based on Spatial Offset Transformation
Mar 11, 2025Current Continual Knowledge Graph Embedding (CKGE) methods primarily rely on translation-based embedding methods, leveraging previously acquired knowledge to initialize new facts. To enhance learning efficiency, these methods often integrate fine-tuning or continual learning strategies. However, this compromises the model's prediction accuracy and the translation-based methods lack support for complex relational structures (multi-hop relations). To tackle this challenge, we propose a novel CKGE framework SoTCKGE grounded in Spatial Offset Transformation. Within this framework, entity positions are defined as being jointly determined by base position vectors and offset vectors. This not only enhances the model's ability to represent complex relational structures but also allows for the embedding update of both new and old knowledge through simple spatial offset transformations, without the need for continuous learning methods. Furthermore, we introduce a hierarchical update strategy and a balanced embedding method to refine the parameter update process, effectively minimizing training costs and augmenting model accuracy. To comprehensively assess the performance of our model, we have conducted extensive experimlents on four publicly accessible datasets and a new dataset constructed by us. Experimental results demonstrate the advantage of our model in enhancing multi-hop relationship learning and further improving prediction accuracy.
TacoERE: Cluster-aware Compression for Event Relation Extraction
May 11, 2024
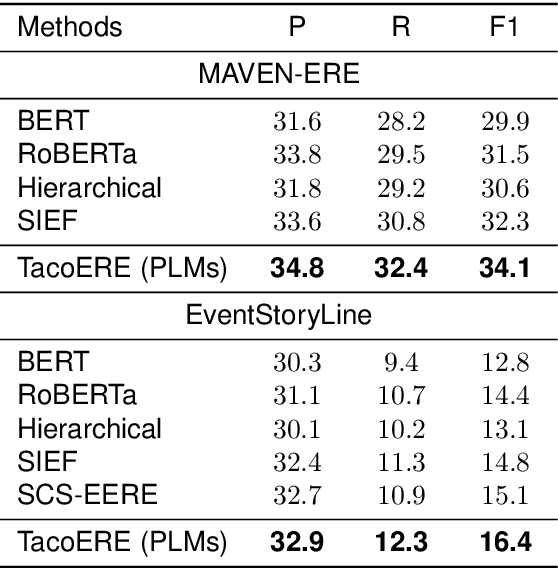
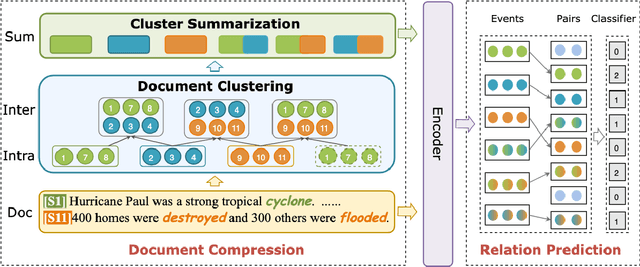
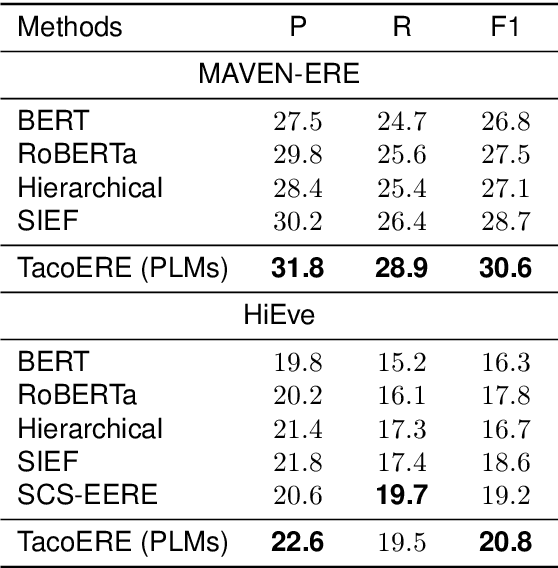
Event relation extraction (ERE) is a critical and fundamental challenge for natural language processing. Existing work mainly focuses on directly modeling the entire document, which cannot effectively handle long-range dependencies and information redundancy. To address these issues, we propose a cluster-aware compression method for improving event relation extraction (TacoERE), which explores a compression-then-extraction paradigm. Specifically, we first introduce document clustering for modeling event dependencies. It splits the document into intra- and inter-clusters, where intra-clusters aim to enhance the relations within the same cluster, while inter-clusters attempt to model the related events at arbitrary distances. Secondly, we utilize cluster summarization to simplify and highlight important text content of clusters for mitigating information redundancy and event distance. We have conducted extensive experiments on both pre-trained language models, such as RoBERTa, and large language models, such as ChatGPT and GPT-4, on three ERE datasets, i.e., MAVEN-ERE, EventStoryLine and HiEve. Experimental results demonstrate that TacoERE is an effective method for ERE.
LaKo: Knowledge-driven Visual Question Answering via Late Knowledge-to-Text Injection
Jul 26, 2022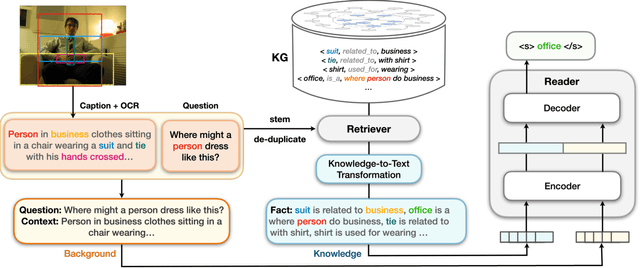

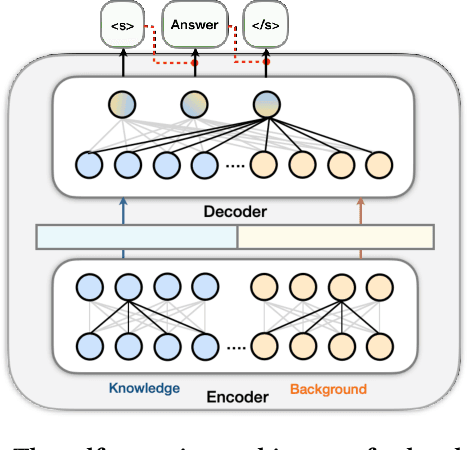

Visual question answering (VQA) often requires an understanding of visual concepts and language semantics, which relies on external knowledge. Most existing methods exploit pre-trained language models or/and unstructured text, but the knowledge in these resources are often incomplete and noisy. Some methods prefer to use knowledge graphs (KGs) which often have intensive structured knowledge, but the research is still quite preliminary. In this paper, we propose LaKo, a knowledge-driven VQA method via Late Knowledge-to-text Injection. To effectively incorporate an external KG, we transfer triples into text and propose a late injection mechanism. Finally we address VQA as a text generation task with an effective encoder-decoder paradigm. In the evaluation with OKVQA datasets, our method achieves state-of-the-art results.
Learning from Ontology Streams with Semantic Concept Drift
Apr 24, 2017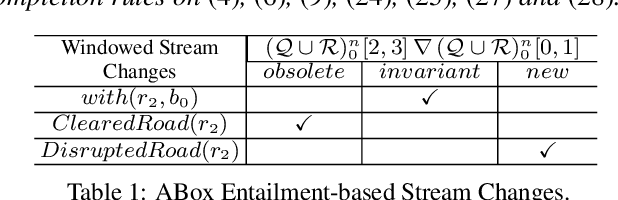



Data stream learning has been largely studied for extracting knowledge structures from continuous and rapid data records. In the semantic Web, data is interpreted in ontologies and its ordered sequence is represented as an ontology stream. Our work exploits the semantics of such streams to tackle the problem of concept drift i.e., unexpected changes in data distribution, causing most of models to be less accurate as time passes. To this end we revisited (i) semantic inference in the context of supervised stream learning, and (ii) models with semantic embeddings. The experiments show accurate prediction with data from Dublin and Beijing.