 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacoERE: Cluster-aware Compression for Event Relation Extraction
Paper and Code
May 11, 2024
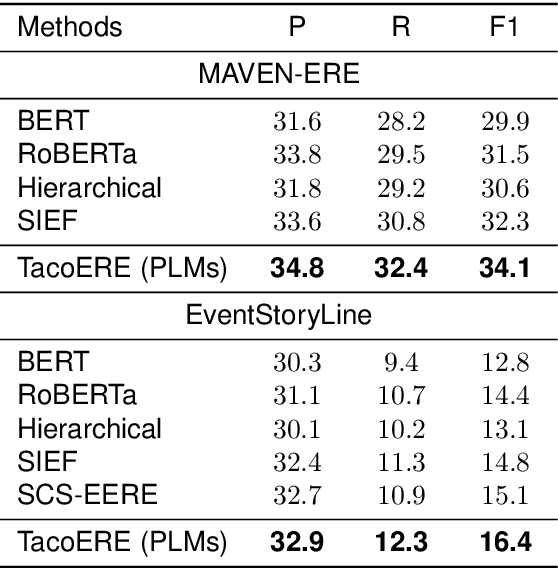
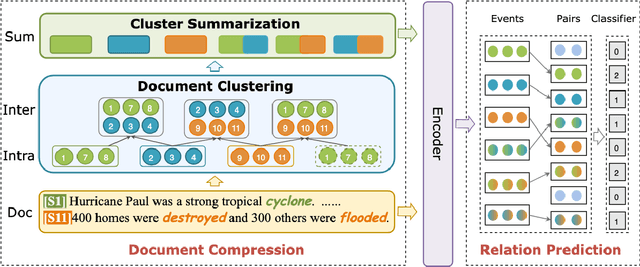
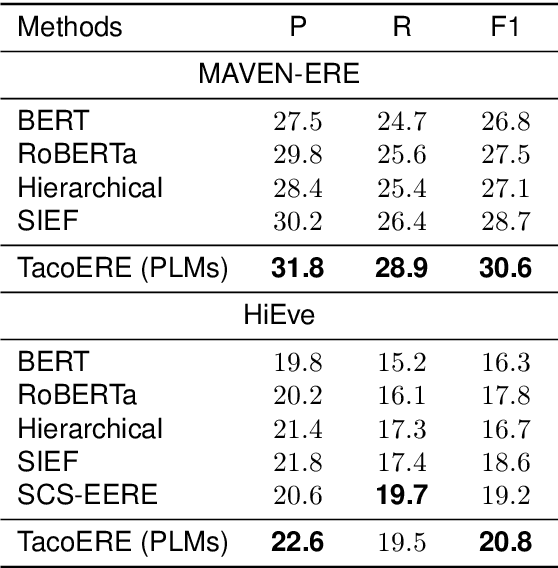
Event relation extraction (ERE) is a critical and fundamental challenge for natural language processing. Existing work mainly focuses on directly modeling the entire document, which cannot effectively handle long-range dependencies and information redundancy. To address these issues, we propose a cluster-aware compression method for improving event relation extraction (TacoERE), which explores a compression-then-extraction paradigm. Specifically, we first introduce document clustering for modeling event dependencies. It splits the document into intra- and inter-clusters, where intra-clusters aim to enhance the relations within the same cluster, while inter-clusters attempt to model the related events at arbitrary distances. Secondly, we utilize cluster summarization to simplify and highlight important text content of clusters for mitigating information redundancy and event distance. We have conducted extensive experiments on both pre-trained language models, such as RoBERTa, and large language models, such as ChatGPT and GPT-4, on three ERE datasets, i.e., MAVEN-ERE, EventStoryLine and HiEve. Experimental results demonstrate that TacoERE is an effective method for ERE.