 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntoProtein: Protein Pretraining With Gene Ontology Embedding
Paper and Code
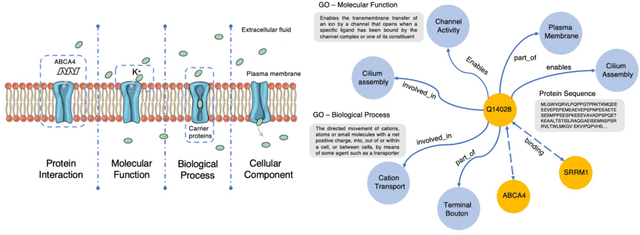
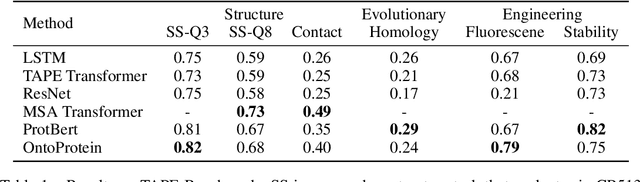
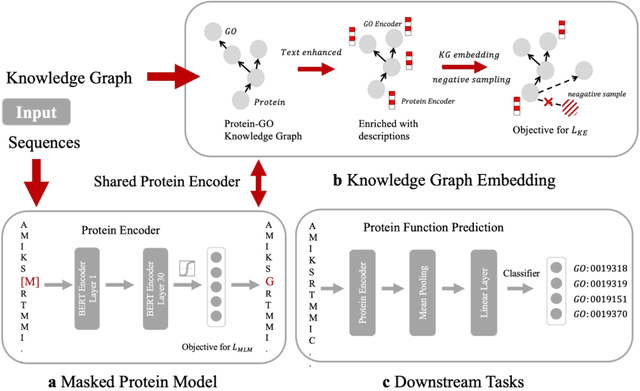
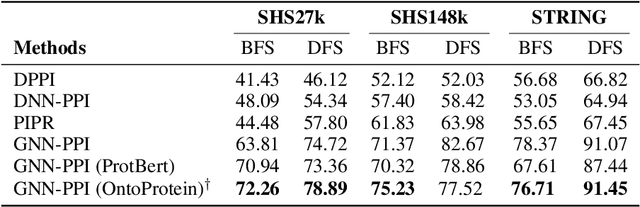
Self-supervised protein language models have proved their effectiveness in learning the proteins representations. With the increasing computational power, current protein language models pre-trained with millions of diverse sequences can advance the parameter scale from million-level to billion-level and achieve remarkable improvement. However, those prevailing approaches rarely consider incorporating knowledge graphs (KGs), which can provide rich structured knowledge facts for better protein representations. We argue that informative biology knowledge in KGs can enhance protein representation with external knowledge. In this work, we propose OntoProtein, the first general framework that makes use of structure in GO (Gene Ontology) into protein pre-training models. We construct a novel large-scale knowledge graph that consists of GO and its related proteins, and gene annotation texts or protein sequences describe all nodes in the graph. We propose novel contrastive learning with knowledge-aware negative sampling to jointly optimize the knowledge graph and protein embedding during pre-training. Experimental results show that OntoProtein can surpass state-of-the-art methods with pre-trained protein language models in TAPE benchmark and yield better performance compared with baselines in protein-protein interaction and protein function prediction. Code and datasets are available in https://github.com/zjunlp/OntoProtein.