 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinAlign: Scaling Healthcare Alignment from Clinician Preference
Feb 11, 2026Although large language models (LLMs) demonstrate expert-level medical knowledge, aligning their open-ended outputs with fine-grained clinician preferences remains challenging. Existing methods often rely on coarse objectives or unreliable automated judges that are weakly grounded in professional guidelines. We propose a two-stage framework to address this gap. First, we introduce HealthRubrics, a dataset of 7,034 physician-verified preference examples in which clinicians refine LLM-drafted rubrics to meet rigorous medical standards. Second, we distill these rubrics into HealthPrinciples: 119 broadly reusable, clinically grounded principles organized by clinical dimensions, enabling scalable supervision beyond manual annotation. We use HealthPrinciples for (1) offline alignment by synthesizing rubrics for unlabeled queries and (2) an inference-time tool for guided self-revision. A 30B-A3B model trained with our framework achieves 33.4% on HealthBench-Hard, outperforming much larger models including Deepseek-R1 and o3, establishing a resource-efficient baseline for clinical alignment.
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
Mar 05, 2024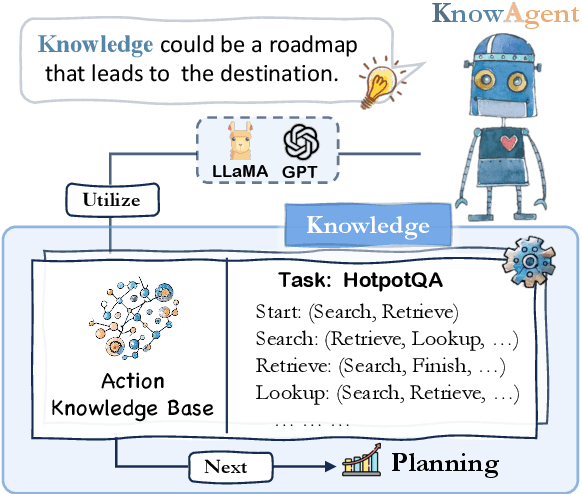
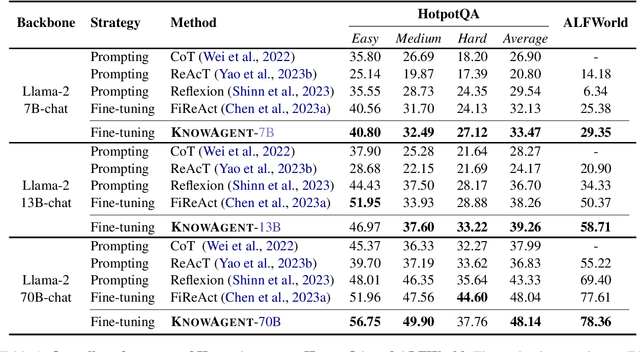
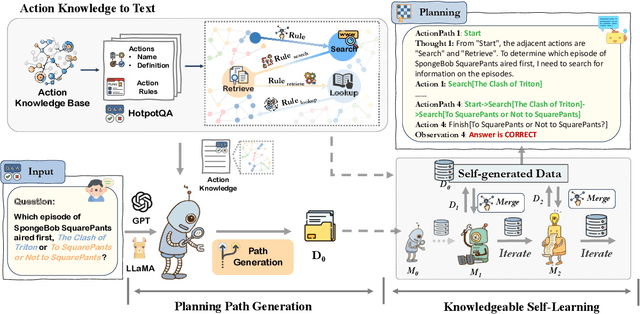

Large Language Models (LLMs) have demonstrated great potential in complex reasoning tasks, yet they fall short when tackling more sophisticated challenges, especially when interacting with environments through generating executable actions. This inadequacy primarily stems from the lack of built-in action knowledge in language agents, which fails to effectively guide the planning trajectories during task solving and results in planning hallucination. To address this issue, we introduce KnowAgent, a novel approach designed to enhance the planning capabilities of LLMs by incorporating explicit action knowledge. Specifically, KnowAgent employs an action knowledge base and a knowledgeable self-learning strategy to constrain the action path during planning, enabling more reasonable trajectory synthesis, and thereby enhancing the planning performance of language agents. Experimental results on HotpotQA and ALFWorld based on various backbone models demonstrate that KnowAgent can achieve comparable or superior performance to existing baselines. Further analysis indicates the effectiveness of KnowAgent in terms of planning hallucinations mitigation. Code is available in https://github.com/zjunlp/KnowAgent.
RJUA-QA: A Comprehensive QA Dataset for Urology
Dec 28, 2023



We introduce RJUA-QA, a novel medical dataset for question answering (QA) and reasoning with clinical evidence, contributing to bridge the gap between general large language models (LLMs) and medical-specific LLM applications. RJUA-QA is derived from realistic clinical scenarios and aims to facilitate LLMs in generating reliable diagnostic and advice. The dataset contains 2,132 curated Question-Context-Answer pairs, corresponding about 25,000 diagnostic records and clinical cases. The dataset covers 67 common urological disease categories, where the disease coverage exceeds 97.6\% of the population seeking medical services in urology. Each data instance in RJUA-QA comprises: (1) a question mirroring real patient to inquiry about clinical symptoms and medical conditions, (2) a context including comprehensive expert knowledge, serving as a reference for medical examination and diagnosis, (3) a doctor response offering the diagnostic conclusion and suggested examination guidance, (4) a diagnosed clinical disease as the recommended diagnostic outcome, and (5) clinical advice providing recommendations for medical examination. RJUA-QA is the first medical QA dataset for clinical reasoning over the patient inquiries, where expert-level knowledge and experience are required for yielding diagnostic conclusions and medical examination advice. A comprehensive evaluation is conducted to evaluate the performance of both medical-specific and general LLMs on the RJUA-QA dataset. Our data is are publicly available at \url{https://github.com/alipay/RJU_Ant_QA}.
Multiple Instance Learning for Uplift Modeling
Dec 15, 2023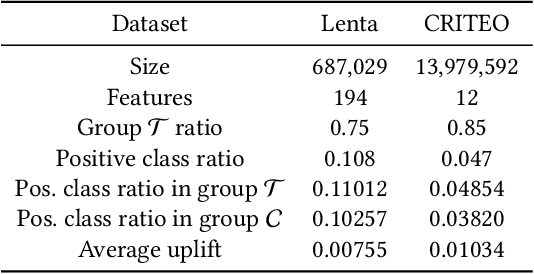
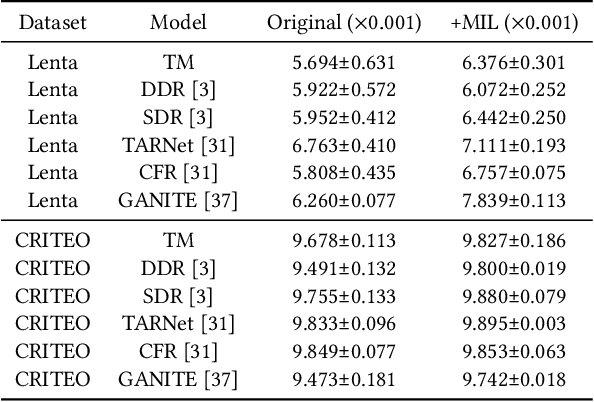
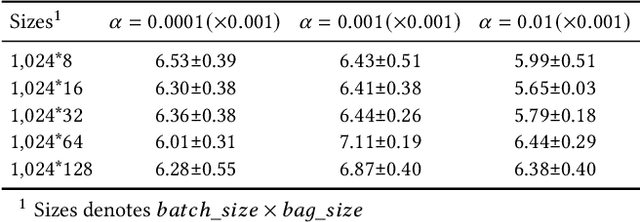

Uplift modeling is widely used in performance marketing to estimate effects of promotion campaigns (e.g., increase of customer retention rate). Since it is impossible to observe outcomes of a recipient in treatment (e.g., receiving a certain promotion) and control (e.g., without promotion) groups simultaneously (i.e., counter-factual), uplift models are mainly trained on instances of treatment and control groups separately to form two models respectively, and uplifts are predicted by the difference of predictions from these two models (i.e., two-model method). When responses are noisy and the treatment effect is fractional, induced individual uplift predictions will be inaccurate, resulting in targeting undesirable customers. Though it is impossible to obtain the ideal ground-truth individual uplifts, known as Individual Treatment Effects (ITEs), alternatively, an average uplift of a group of users, called Average Treatment Effect (ATE), can be observed from experimental deliveries. Upon this, similar to Multiple Instance Learning (MIL) in which each training sample is a bag of instances, our framework sums up individual user uplift predictions for each bag of users as its bag-wise ATE prediction, and regularizes it to its ATE label, thus learning more accurate individual uplifts. Additionally, to amplify the fractional treatment effect, bags are composed of instances with adjacent individual uplift predictions, instead of random instances. Experiments conducted on two datasets show the effectiveness and universality of the proposed framework.
* short paper of CIKM22(full version)
Graph Neural Network Based VC Investment Success Prediction
May 25, 2021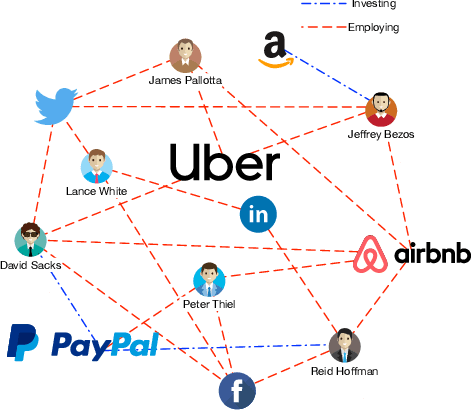
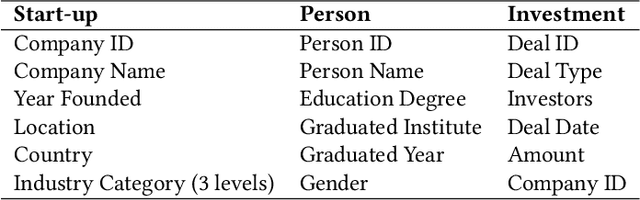
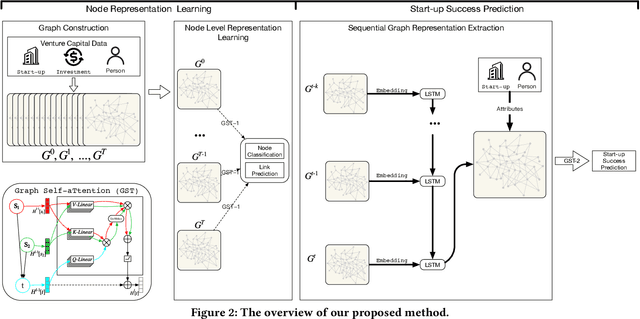
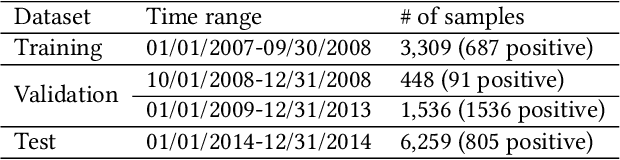
Predicting the start-ups that will eventually succeed is essentially important for the venture capital business and worldwide policy makers, especially at an early stage such that rewards can possibly be exponential. Though various empirical studies and data-driven modeling work have been done, the predictive power of the complex networks of stakeholders including venture capital investors, start-ups, and start-ups' managing members has not been thoroughly explored. We design an incremental representation learning mechanism and a sequential learning model, utilizing the network structure together with the rich attributes of the nodes. In general, our method achieves the state-of-the-art prediction performance on a comprehensive dataset of global venture capital investments and surpasses human investors by large margins. Specifically, it excels at predicting the outcomes for start-ups in industries such as healthcare and IT. Meanwhile, we shed light on impacts on start-up success from observable factors including gender, education, and networking, which can be of value for practitioners as well as policy makers when they screen ventures of high growth potentials.