 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Evaluation for LLMs' Clinical Capabilities: Metric, Data, and Algorithm
Mar 25, 2024



Large language models (LLMs) are gaining increasing interests to improve clinical efficiency for medical diagnosis, owing to their unprecedented performance in modelling natural language. Ensuring the safe and reliable clinical applications, the evaluation of LLMs indeed becomes critical for better mitigating the potential risks, e.g., hallucinations. However, current evaluation methods heavily rely on labor-intensive human participation to achieve human-preferred judgements. To overcome this challenge, we propose an automatic evaluation paradigm tailored to assess the LLMs' capabilities in delivering clinical services, e.g., disease diagnosis and treatment. The evaluation paradigm contains three basic elements: metric, data, and algorithm. Specifically, inspired by professional clinical practice pathways, we formulate a LLM-specific clinical pathway (LCP) to define the clinical capabilities that a doctor agent should possess. Then, Standardized Patients (SPs) from the medical education are introduced as the guideline for collecting medical data for evaluation, which can well ensure the completeness of the evaluation procedure. Leveraging these steps, we develop a multi-agent framework to simulate the interactive environment between SPs and a doctor agent, which is equipped with a Retrieval-Augmented Evaluation (RAE) to determine whether the behaviors of a doctor agent are in accordance with LCP. The above paradigm can be extended to any similar clinical scenarios to automatically evaluate the LLMs' medical capabilities. Applying such paradigm, we construct an evaluation benchmark in the field of urology, including a LCP, a SPs dataset, and an automated RAE. Extensive experiments are conducted to demonstrate the effectiveness of the proposed approach, providing more insights for LLMs' safe and reliable deployments in clinical practice.
RJUA-MedDQA: A Multimodal Benchmark for Medical Document Question Answering and Clinical Reasoning
Feb 19, 2024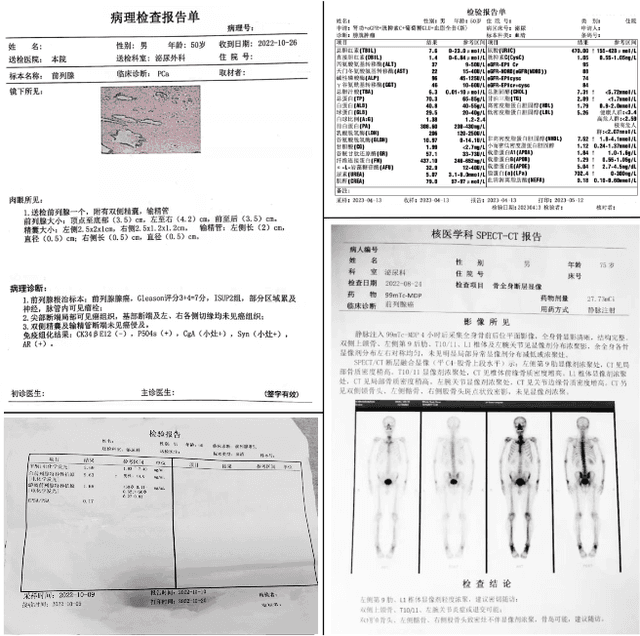
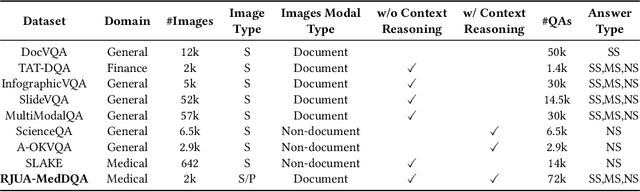
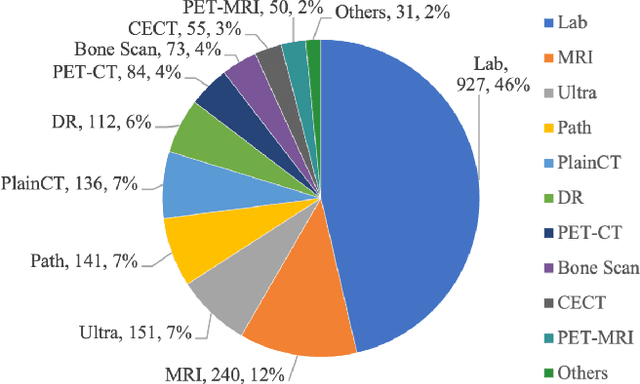

Recent advancements in Large Language Models (LLMs) and Large Multi-modal Models (LMMs) have shown potential in various medical applications, such as Intelligent Medical Diagnosis. Although impressive results have been achieved, we find that existing benchmarks do not reflect the complexity of real medical reports and specialized in-depth reasoning capabilities. In this work, we introduced RJUA-MedDQA, a comprehensive benchmark in the field of medical specialization, which poses several challenges: comprehensively interpreting imgage content across diverse challenging layouts, possessing numerical reasoning ability to identify abnormal indicators and demonstrating clinical reasoning ability to provide statements of disease diagnosis, status and advice based on medical contexts. We carefully design the data generation pipeline and proposed the Efficient Structural Restoration Annotation (ESRA) Method, aimed at restoring textual and tabular content in medical report images. This method substantially enhances annotation efficiency, doubling the productivity of each annotator, and yields a 26.8% improvement in accuracy. We conduct extensive evaluations, including few-shot assessments of 5 LMMs which are capable of solving Chinese medical QA tasks. To further investigate the limitations and potential of current LMMs, we conduct comparative experiments on a set of strong LLMs by using image-text generated by ESRA method. We report the performance of baselines and offer several observations: (1) The overall performance of existing LMMs is still limited; however LMMs more robust to low-quality and diverse-structured images compared to LLMs. (3) Reasoning across context and image content present significant challenges. We hope this benchmark helps the community make progress on these challenging tasks in multi-modal medical document understanding and facilitate its application in healthcare.
RJUA-QA: A Comprehensive QA Dataset for Urology
Dec 28, 2023



We introduce RJUA-QA, a novel medical dataset for question answering (QA) and reasoning with clinical evidence, contributing to bridge the gap between general large language models (LLMs) and medical-specific LLM applications. RJUA-QA is derived from realistic clinical scenarios and aims to facilitate LLMs in generating reliable diagnostic and advice. The dataset contains 2,132 curated Question-Context-Answer pairs, corresponding about 25,000 diagnostic records and clinical cases. The dataset covers 67 common urological disease categories, where the disease coverage exceeds 97.6\% of the population seeking medical services in urology. Each data instance in RJUA-QA comprises: (1) a question mirroring real patient to inquiry about clinical symptoms and medical conditions, (2) a context including comprehensive expert knowledge, serving as a reference for medical examination and diagnosis, (3) a doctor response offering the diagnostic conclusion and suggested examination guidance, (4) a diagnosed clinical disease as the recommended diagnostic outcome, and (5) clinical advice providing recommendations for medical examination. RJUA-QA is the first medical QA dataset for clinical reasoning over the patient inquiries, where expert-level knowledge and experience are required for yielding diagnostic conclusions and medical examination advice. A comprehensive evaluation is conducted to evaluate the performance of both medical-specific and general LLMs on the RJUA-QA dataset. Our data is are publicly available at \url{https://github.com/alipay/RJU_Ant_QA}.