 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePulseMind: A Multi-Modal Medical Model for Real-World Clinical Diagnosis
Jan 12, 2026Recent advances in medical multi-modal models focus on specialized image analysis like dermatology, pathology, or radiology. However, they do not fully capture the complexity of real-world clinical diagnostics, which involve heterogeneous inputs and require ongoing contextual understanding during patient-physician interactions. To bridge this gap, we introduce PulseMind, a new family of multi-modal diagnostic models that integrates a systematically curated dataset, a comprehensive evaluation benchmark, and a tailored training framework. Specifically, we first construct a diagnostic dataset, MediScope, which comprises 98,000 real-world multi-turn consultations and 601,500 medical images, spanning over 10 major clinical departments and more than 200 sub-specialties. Then, to better reflect the requirements of real-world clinical diagnosis, we develop the PulseMind Benchmark, a multi-turn diagnostic consultation benchmark with a four-dimensional evaluation protocol comprising proactiveness, accuracy, usefulness, and language quality. Finally, we design a training framework tailored for multi-modal clinical diagnostics, centered around a core component named Comparison-based Reinforcement Policy Optimization (CRPO). Compared to absolute score rewards, CRPO uses relative preference signals from multi-dimensional com-parisons to provide stable and human-aligned training guidance. Extensive experiments demonstrate that PulseMind achieves competitive performance on both the diagnostic consultation benchmark and public medical benchmarks.
RJUA-MedDQA: A Multimodal Benchmark for Medical Document Question Answering and Clinical Reasoning
Feb 19, 2024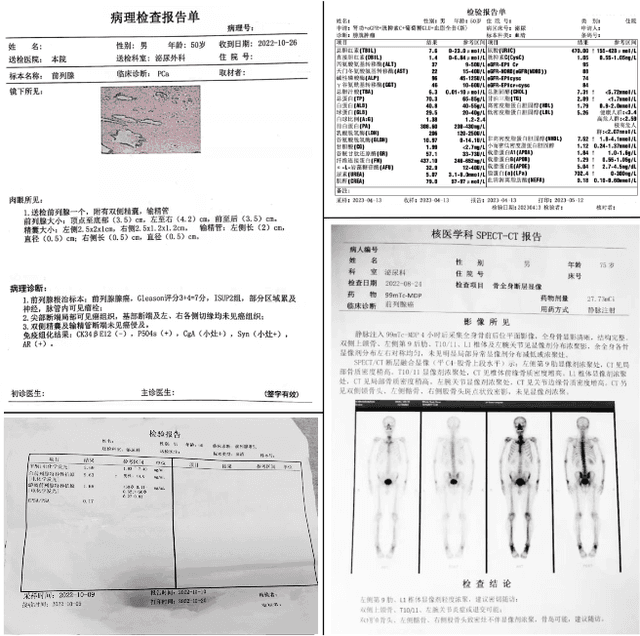
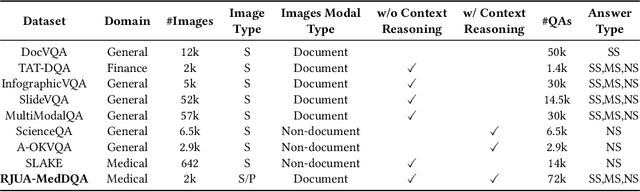
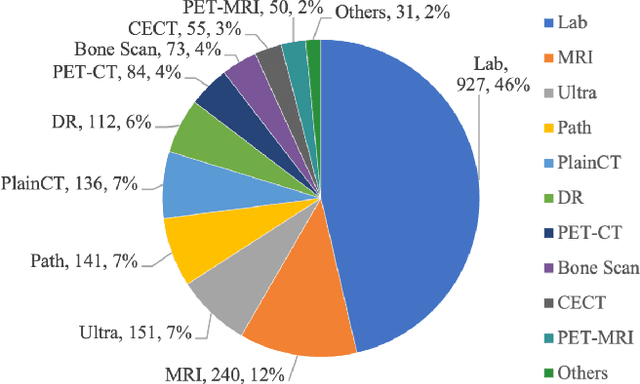

Recent advancements in Large Language Models (LLMs) and Large Multi-modal Models (LMMs) have shown potential in various medical applications, such as Intelligent Medical Diagnosis. Although impressive results have been achieved, we find that existing benchmarks do not reflect the complexity of real medical reports and specialized in-depth reasoning capabilities. In this work, we introduced RJUA-MedDQA, a comprehensive benchmark in the field of medical specialization, which poses several challenges: comprehensively interpreting imgage content across diverse challenging layouts, possessing numerical reasoning ability to identify abnormal indicators and demonstrating clinical reasoning ability to provide statements of disease diagnosis, status and advice based on medical contexts. We carefully design the data generation pipeline and proposed the Efficient Structural Restoration Annotation (ESRA) Method, aimed at restoring textual and tabular content in medical report images. This method substantially enhances annotation efficiency, doubling the productivity of each annotator, and yields a 26.8% improvement in accuracy. We conduct extensive evaluations, including few-shot assessments of 5 LMMs which are capable of solving Chinese medical QA tasks. To further investigate the limitations and potential of current LMMs, we conduct comparative experiments on a set of strong LLMs by using image-text generated by ESRA method. We report the performance of baselines and offer several observations: (1) The overall performance of existing LMMs is still limited; however LMMs more robust to low-quality and diverse-structured images compared to LLMs. (3) Reasoning across context and image content present significant challenges. We hope this benchmark helps the community make progress on these challenging tasks in multi-modal medical document understanding and facilitate its application in healthcare.
GACE: Learning Graph-Based Cross-Page Ads Embedding For Click-Through Rate Prediction
Jan 15, 2024Predicting click-through rate (CTR) is the core task of many ads online recommendation systems, which helps improve user experience and increase platform revenue. In this type of recommendation system, we often encounter two main problems: the joint usage of multi-page historical advertising data and the cold start of new ads. In this paper, we proposed GACE, a graph-based cross-page ads embedding generation method. It can warm up and generate the representation embedding of cold-start and existing ads across various pages. Specifically, we carefully build linkages and a weighted undirected graph model considering semantic and page-type attributes to guide the direction of feature fusion and generation. We designed a variational auto-encoding task as pre-training module and generated embedding representations for new and old ads based on this task. The results evaluated in the public dataset AliEC from RecBole and the real-world industry dataset from Alipay show that our GACE method is significantly superior to the SOTA method. In the online A/B test, the click-through rate on three real-world pages from Alipay has increased by 3.6%, 2.13%, and 3.02%, respectively. Especially in the cold-start task, the CTR increased by 9.96%, 7.51%, and 8.97%, respectively.