 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayout and Task Aware Instruction Prompt for Zero-shot Document Image Question Answering
Paper and Code
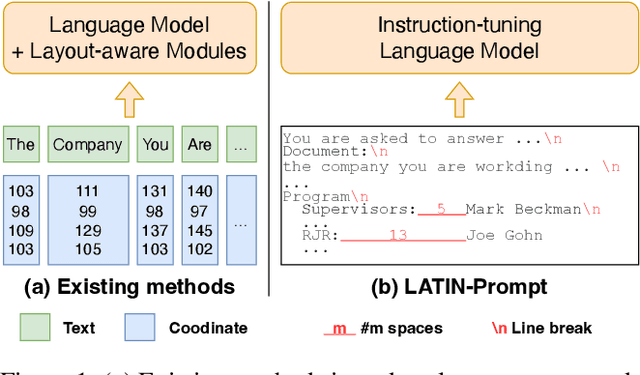

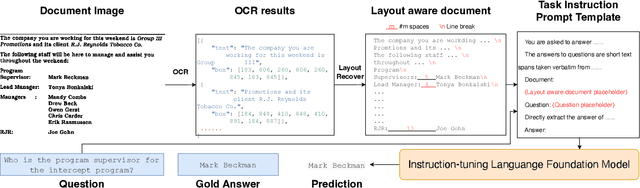
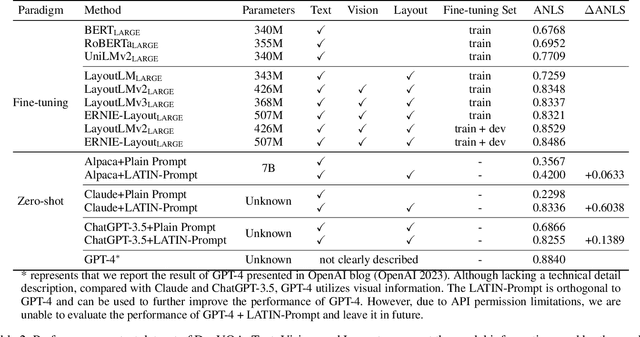
The pre-training-fine-tuning paradigm based on layout-aware multimodal pre-trained models has achieved significant progress on document image question answering. However, domain pre-training and task fine-tuning for additional visual, layout, and task modules prevent them from directly utilizing off-the-shelf instruction-tuning language foundation models, which have recently shown promising potential in zero-shot learning. Contrary to aligning language models to the domain of document image question answering, we align document image question answering to off-the-shell instruction-tuning language foundation models to utilize their zero-shot capability. Specifically, we propose layout and task aware instruction prompt called LATIN-Prompt, which consists of layout-aware document content and task-aware descriptions. The former recovers the layout information among text segments from OCR tools by appropriate spaces and line breaks. The latter ensures that the model generates answers that meet the requirements, especially format requirements, through a detailed description of task. Experimental results on three benchmarks show that LATIN-Prompt can improve the zero-shot performance of instruction-tuning language foundation models on document image question answering and help them achieve comparable levels to SOTAs based on the pre-training-fine-tuning paradigm. Quantitative analysis and qualitative analysis demonstrate the effectiveness of LATIN-Prompt. We provide the code in supplementary and will release the code to facilitate future research.