 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemp-R1: A Unified Autonomous Agent for Complex Temporal KGQA via Reverse Curriculum Reinforcement Learning
Jan 26, 2026Temporal Knowledge Graph Question Answering (TKGQA) is inherently challenging, as it requires sophisticated reasoning over dynamic facts with multi-hop dependencies and complex temporal constraints. Existing methods rely on fixed workflows and expensive closed-source APIs, limiting flexibility and scalability. We propose Temp-R1, the first autonomous end-to-end agent for TKGQA trained through reinforcement learning. To address cognitive overload in single-action reasoning, we expand the action space with specialized internal actions alongside external action. To prevent shortcut learning on simple questions, we introduce reverse curriculum learning that trains on difficult questions first, forcing the development of sophisticated reasoning before transferring to easier cases. Our 8B-parameter Temp-R1 achieves state-of-the-art performance on MultiTQ and TimelineKGQA, improving 19.8% over strong baselines on complex questions. Our work establishes a new paradigm for autonomous temporal reasoning agents. Our code will be publicly available soon at https://github.com/zjukg/Temp-R1.
Illusions of Confidence? Diagnosing LLM Truthfulness via Neighborhood Consistency
Jan 09, 2026As Large Language Models (LLMs) are increasingly deployed in real-world settings, correctness alone is insufficient. Reliable deployment requires maintaining truthful beliefs under contextual perturbations. Existing evaluations largely rely on point-wise confidence like Self-Consistency, which can mask brittle belief. We show that even facts answered with perfect self-consistency can rapidly collapse under mild contextual interference. To address this gap, we propose Neighbor-Consistency Belief (NCB), a structural measure of belief robustness that evaluates response coherence across a conceptual neighborhood. To validate the efficiency of NCB, we introduce a new cognitive stress-testing protocol that probes outputs stability under contextual interference. Experiments across multiple LLMs show that the performance of high-NCB data is relatively more resistant to interference. Finally, we present Structure-Aware Training (SAT), which optimizes context-invariant belief structure and reduces long-tail knowledge brittleness by approximately 30%. Code will be available at https://github.com/zjunlp/belief.
LightMem: Lightweight and Efficient Memory-Augmented Generation
Oct 21, 2025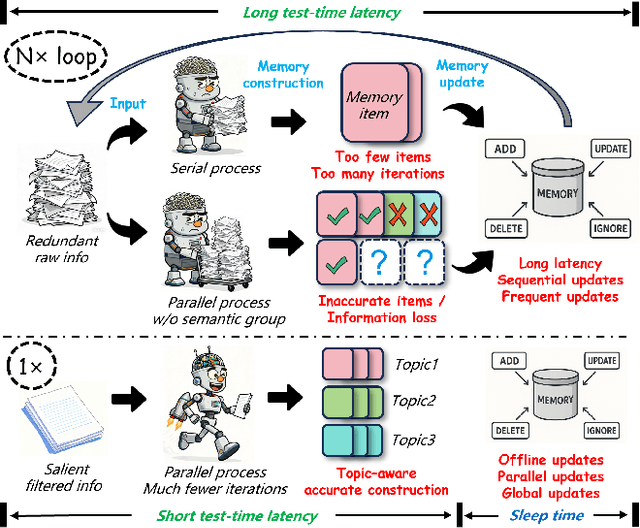
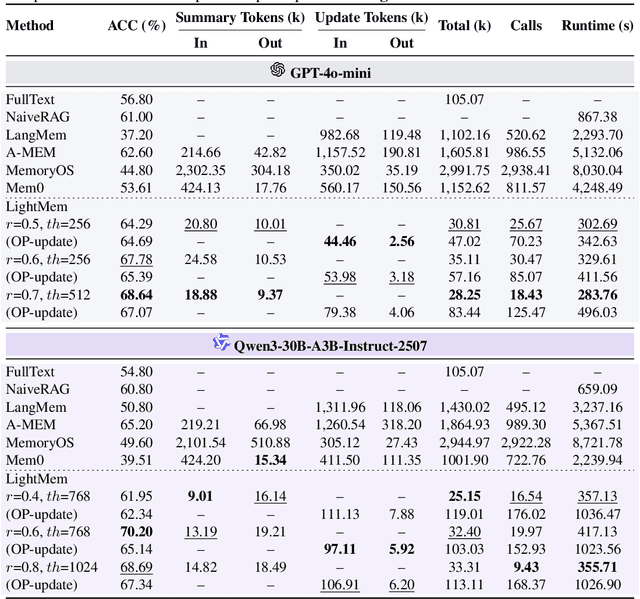
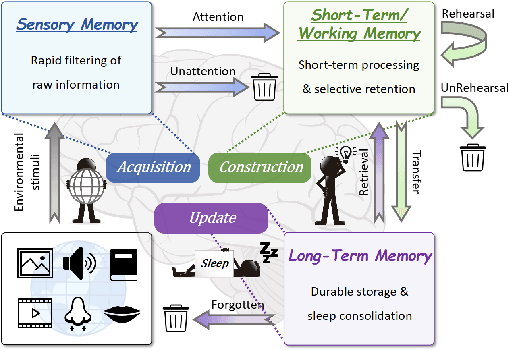
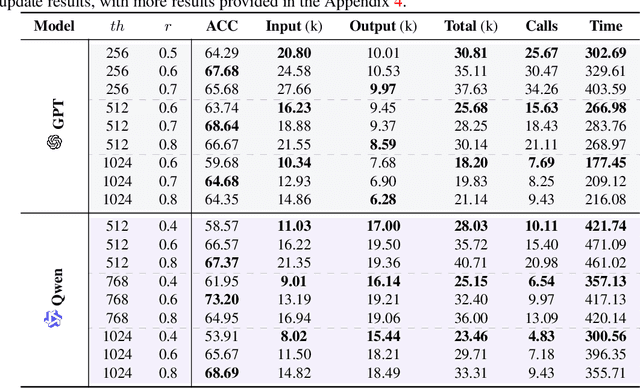
Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. Experiments on LongMemEval with GPT and Qwen backbones show that LightMem outperforms strong baselines in accuracy (up to 10.9% gains) while reducing token usage by up to 117x, API calls by up to 159x, and runtime by over 12x. The code is available at https://github.com/zjunlp/LightMem.
EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models
Apr 21, 2025



In this paper, we introduce EasyEdit2, a framework designed to enable plug-and-play adjustability for controlling Large Language Model (LLM) behaviors. EasyEdit2 supports a wide range of test-time interventions, including safety, sentiment, personality, reasoning patterns, factuality, and language features. Unlike its predecessor, EasyEdit2 features a new architecture specifically designed for seamless model steering. It comprises key modules such as the steering vector generator and the steering vector applier, which enable automatic generation and application of steering vectors to influence the model's behavior without modifying its parameters. One of the main advantages of EasyEdit2 is its ease of use-users do not need extensive technical knowledge. With just a single example, they can effectively guide and adjust the model's responses, making precise control both accessible and efficient. Empirically, we report model steering performance across different LLMs, demonstrating the effectiveness of these techniques. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit along with a demonstration notebook. In addition, we provide a demo video at https://zjunlp.github.io/project/EasyEdit2/video for a quick introduction.
A Multi-Modal AI Copilot for Single-Cell Analysis with Instruction Following
Jan 15, 2025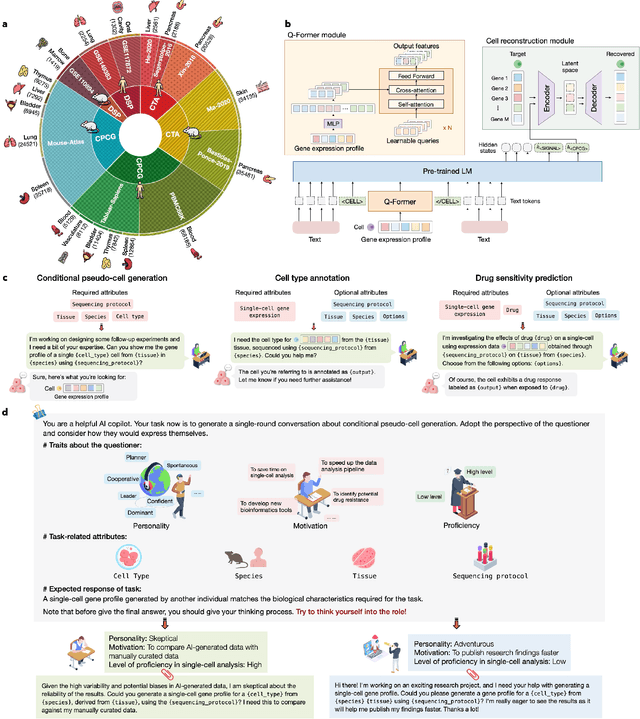
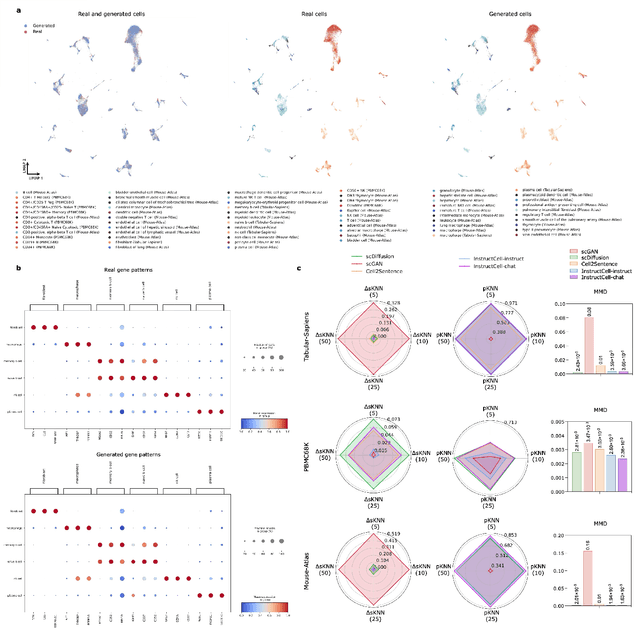
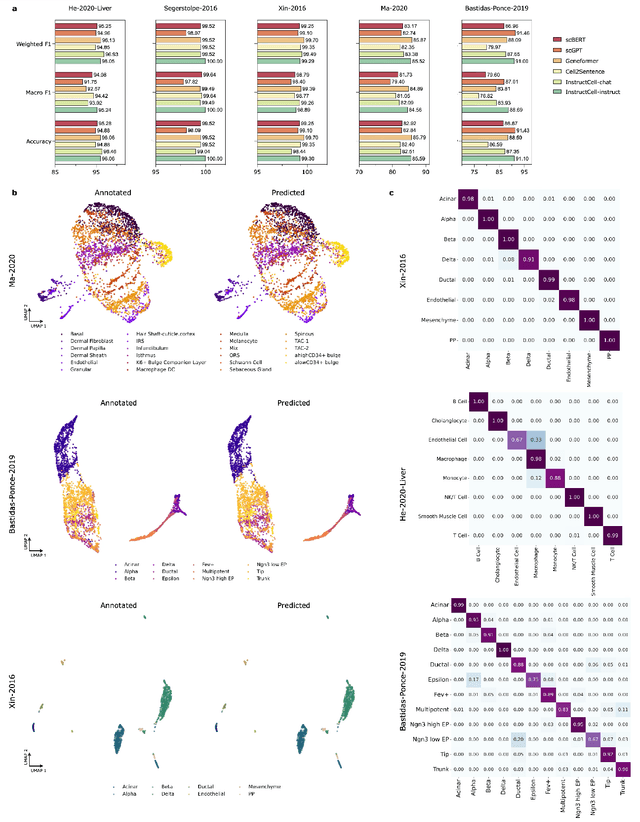
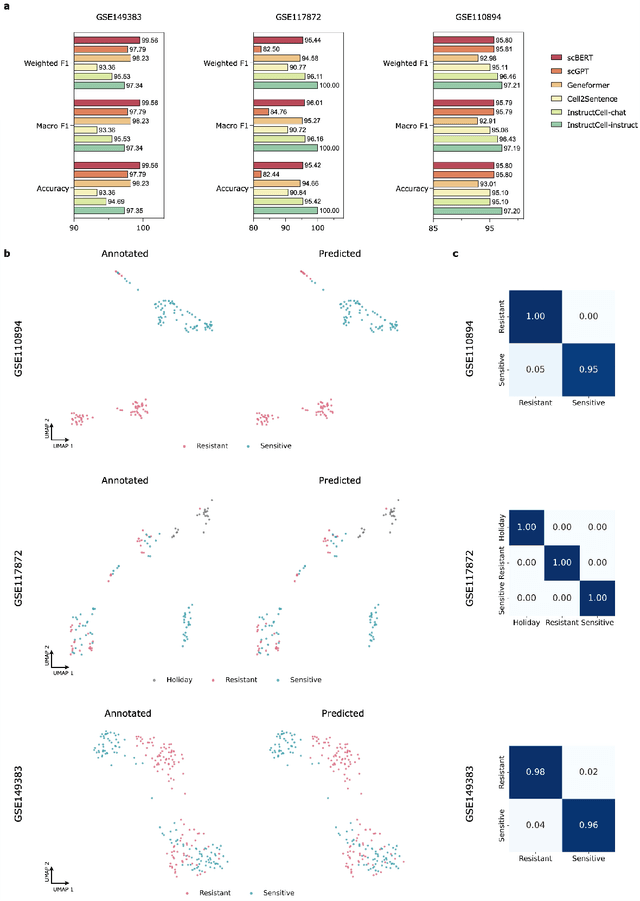
Large language models excel at interpreting complex natural language instructions, enabling them to perform a wide range of tasks. In the life sciences, single-cell RNA sequencing (scRNA-seq) data serves as the "language of cellular biology", capturing intricate gene expression patterns at the single-cell level. However, interacting with this "language" through conventional tools is often inefficient and unintuitive, posing challenges for researchers. To address these limitations, we present InstructCell, a multi-modal AI copilot that leverages natural language as a medium for more direct and flexible single-cell analysis. We construct a comprehensive multi-modal instruction dataset that pairs text-based instructions with scRNA-seq profiles from diverse tissues and species. Building on this, we develop a multi-modal cell language architecture capable of simultaneously interpreting and processing both modalities. InstructCell empowers researchers to accomplish critical tasks-such as cell type annotation, conditional pseudo-cell generation, and drug sensitivity prediction-using straightforward natural language commands. Extensive evaluations demonstrate that InstructCell consistently meets or exceeds the performance of existing single-cell foundation models, while adapting to diverse experimental conditions. More importantly, InstructCell provides an accessible and intuitive tool for exploring complex single-cell data, lowering technical barriers and enabling deeper biological insights.
ChatCell: Facilitating Single-Cell Analysis with Natural Language
Feb 20, 2024



As Large Language Models (LLMs) rapidly evolve, their influence in science is becoming increasingly prominent. The emerging capabilities of LLMs in task generalization and free-form dialogue can significantly advance fields like chemistry and biology. However, the field of single-cell biology, which forms the foundational building blocks of living organisms, still faces several challenges. High knowledge barriers and limited scalability in current methods restrict the full exploitation of LLMs in mastering single-cell data, impeding direct accessibility and rapid iteration. To this end, we introduce ChatCell, which signifies a paradigm shift by facilitating single-cell analysis with natural language. Leveraging vocabulary adaptation and unified sequence generation, ChatCell has acquired profound expertise in single-cell biology and the capability to accommodate a diverse range of analysis tasks. Extensive experiments further demonstrate ChatCell's robust performance and potential to deepen single-cell insights, paving the way for more accessible and intuitive exploration in this pivotal field. Our project homepage is available at https://zjunlp.github.io/project/ChatCell.
Weaver: Foundation Models for Creative Writing
Jan 30, 2024

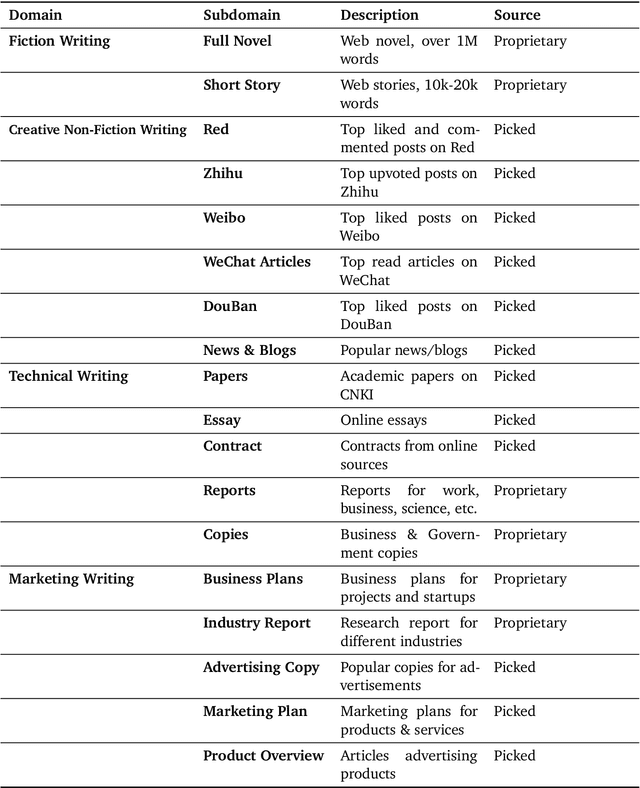

This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.