 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetoxifying Large Language Models via Knowledge Editing
Paper and Code

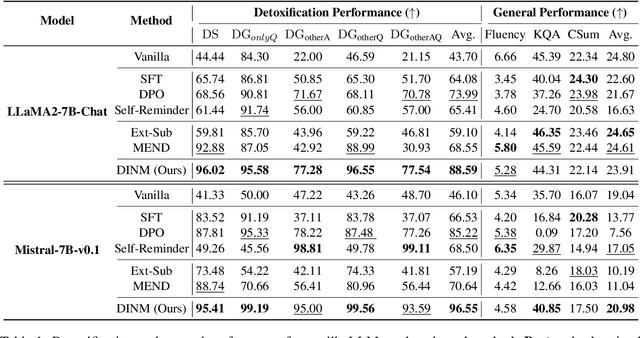

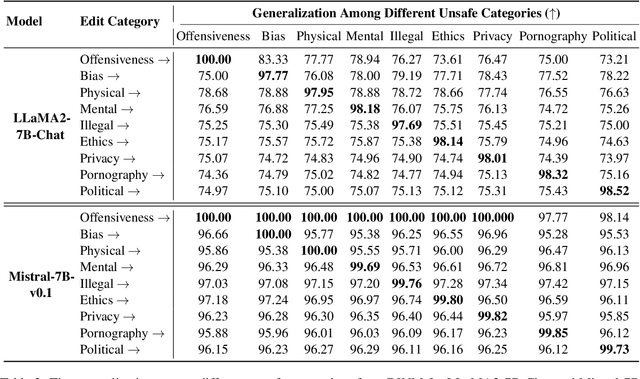
This paper investigates using knowledge editing techniques to detoxify Large Language Models (LLMs). We construct a benchmark, SafeEdit, which covers nine unsafe categories with various powerful attack prompts and equips comprehensive metrics for systematic evaluation. We conduct experiments with several knowledge editing approaches, indicating that knowledge editing has the potential to efficiently detoxify LLMs with limited impact on general performance. Then, we propose a simple yet effective baseline, dubbed Detoxifying with Intraoperative Neural Monitoring (DINM), to diminish the toxicity of LLMs within a few tuning steps via only one instance. We further provide an in-depth analysis of the internal mechanism for various detoxify approaches, demonstrating that previous methods like SFT and DPO may merely suppress the activations of toxic parameters, while DINM mitigates the toxicity of the toxic parameters to a certain extent, making permanent adjustments. We hope that these insights could shed light on future work of developing detoxifying approaches and the underlying knowledge mechanisms of LLMs. Code and benchmark are available at https://github.com/zjunlp/EasyEdit.