 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Student Knows All Experts Know: From Sparse to Dense
Paper and Code
Jan 26, 2022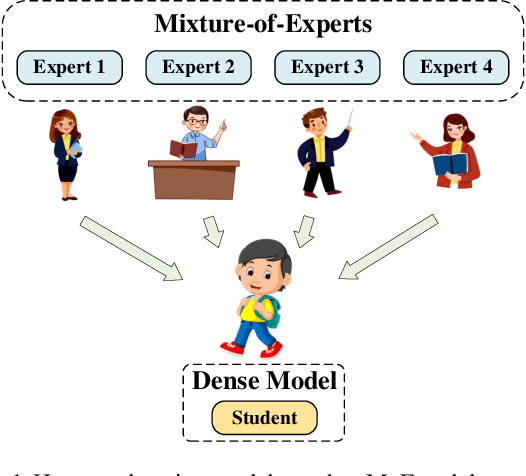
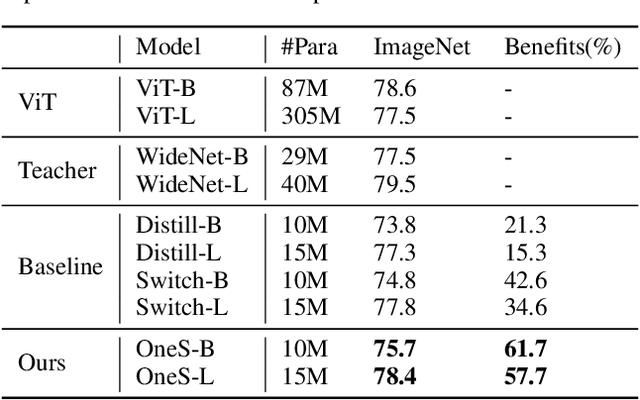
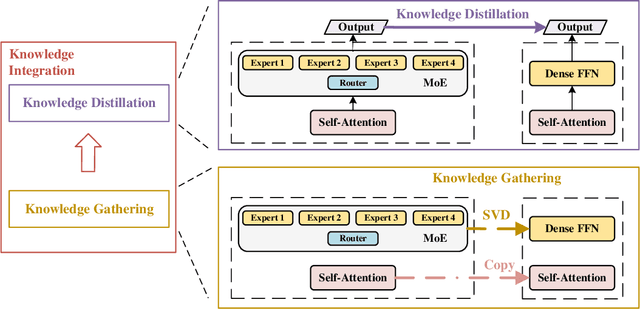
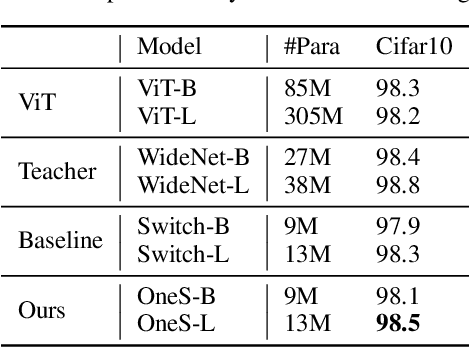
Human education system trains one student by multiple experts. Mixture-of-experts (MoE) is a powerful sparse architecture including multiple experts. However, sparse MoE model is hard to implement, easy to overfit, and not hardware-friendly. In this work, inspired by human education model, we propose a novel task, knowledge integration, to obtain a dense student model (OneS) as knowledgeable as one sparse MoE. We investigate this task by proposing a general training framework including knowledge gathering and knowledge distillation. Specifically, we first propose Singular Value Decomposition Knowledge Gathering (SVD-KG) to gather key knowledge from different pretrained experts. We then refine the dense student model by knowledge distillation to offset the noise from gathering. On ImageNet, our OneS preserves $61.7\%$ benefits from MoE. OneS can achieve $78.4\%$ top-1 accuracy with only $15$M parameters. On four natural language processing datasets, OneS obtains $88.2\%$ MoE benefits and outperforms SoTA by $51.7\%$ using the same architecture and training data. In addition, compared with the MoE counterpart, OneS can achieve $3.7 \times$ inference speedup due to the hardware-friendly architecture.