 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompliance Moral Hazard and the Backfiring Mandate
Apr 23, 2026Competing firms that serve shared customer populations face a fundamental information aggregation problem: each firm holds fragmented signals about risky customers, but individual incentives impede efficient collective detection. We develop a mechanism design framework for decentralized risk analytics, grounded in anti-money laundering in banking networks. Three strategic frictions distinguish our setting: compliance moral hazard, adversarial adaptation, and information destruction through intervention. A temporal value assignment (TVA) mechanism, which credits institutions using a strictly proper scoring rule on discounted verified outcomes, implements truthful reporting as a Bayes--Nash equilibrium (uniquely optimal at each edge) in large federations. Embedding TVA in a banking competition model, we show competitive pressure amplifies compliance moral hazard and poorly designed mandates can reduce welfare below autarky, a ``backfiring'' result with direct policy implications. In simulation using a synthetic AML benchmark, TVA achieves substantially higher welfare than autarky or mandated sharing without incentive design.
TSAQA: Time Series Analysis Question And Answering Benchmark
Jan 30, 2026Time series data are integral to critical applications across domains such as finance, healthcare, transportation, and environmental science. While recent work has begun to explore multi-task time series question answering (QA), current benchmarks remain limited to forecasting and anomaly detection tasks. We introduce TSAQA, a novel unified benchmark designed to broaden task coverage and evaluate diverse temporal analysis capabilities. TSAQA integrates six diverse tasks under a single framework ranging from conventional analysis, including anomaly detection and classification, to advanced analysis, such as characterization, comparison, data transformation, and temporal relationship analysis. Spanning 210k samples across 13 domains, the dataset employs diverse formats, including true-or-false (TF), multiple-choice (MC), and a novel puzzling (PZ), to comprehensively assess time series analysis. Zero-shot evaluation demonstrates that these tasks are challenging for current Large Language Models (LLMs): the best-performing commercial LLM, Gemini-2.5-Flash, achieves an average score of only 65.08. Although instruction tuning boosts open-source performance: the best-performing open-source model, LLaMA-3.1-8B, shows significant room for improvement, highlighting the complexity of temporal analysis for LLMs.
OWLEYE: Zero-Shot Learner for Cross-Domain Graph Data Anomaly Detection
Jan 27, 2026Graph data is informative to represent complex relationships such as transactions between accounts, communications between devices, and dependencies among machines or processes. Correspondingly, graph anomaly detection (GAD) plays a critical role in identifying anomalies across various domains, including finance, cybersecurity, manufacturing, etc. Facing the large-volume and multi-domain graph data, nascent efforts attempt to develop foundational generalist models capable of detecting anomalies in unseen graphs without retraining. To the best of our knowledge, the different feature semantics and dimensions of cross-domain graph data heavily hinder the development of the graph foundation model, leaving further in-depth continual learning and inference capabilities a quite open problem. Hence, we propose OWLEYE, a novel zero-shot GAD framework that learns transferable patterns of normal behavior from multiple graphs, with a threefold contribution. First, OWLEYE proposes a cross-domain feature alignment module to harmonize feature distributions, which preserves domain-specific semantics during alignment. Second, with aligned features, to enable continuous learning capabilities, OWLEYE designs the multi-domain multi-pattern dictionary learning to encode shared structural and attribute-based patterns. Third, for achieving the in-context learning ability, OWLEYE develops a truncated attention-based reconstruction module to robustly detect anomalies without requiring labeled data for unseen graph-structured data. Extensive experiments on real-world datasets demonstrate that OWLEYE achieves superior performance and generalizability compared to state-of-the-art baselines, establishing a strong foundation for scalable and label-efficient anomaly detection.
Data Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025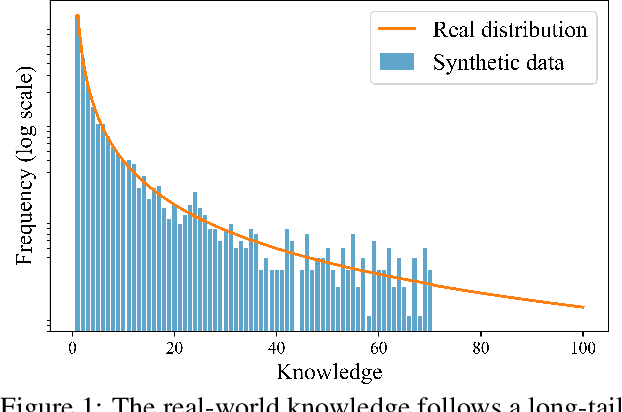
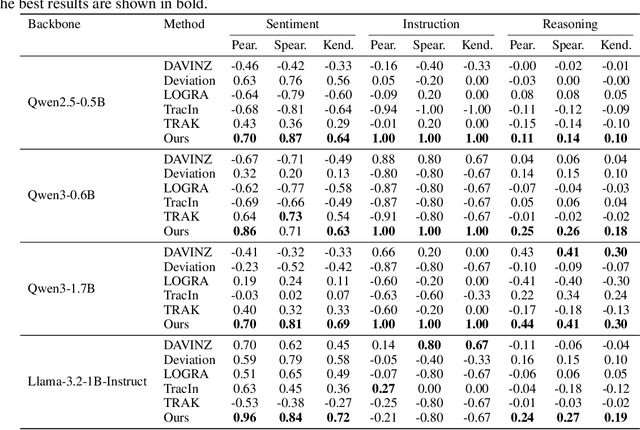
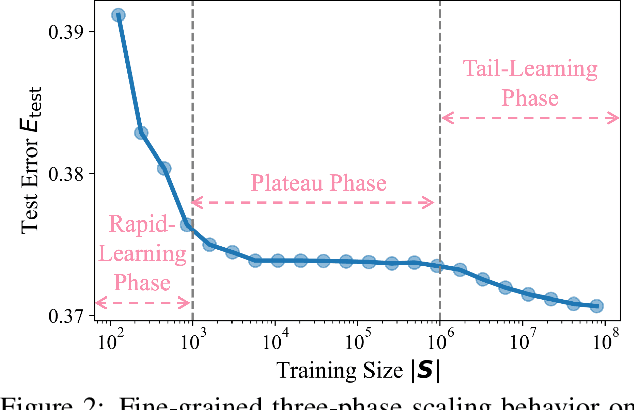
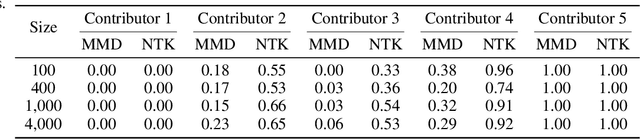
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
ClimateBench-M: A Multi-Modal Climate Data Benchmark with a Simple Generative Method
Apr 10, 2025Climate science studies the structure and dynamics of Earth's climate system and seeks to understand how climate changes over time, where the data is usually stored in the format of time series, recording the climate features, geolocation, time attributes, etc. Recently, much research attention has been paid to the climate benchmarks. In addition to the most common task of weather forecasting, several pioneering benchmark works are proposed for extending the modality, such as domain-specific applications like tropical cyclone intensity prediction and flash flood damage estimation, or climate statement and confidence level in the format of natural language. To further motivate the artificial general intelligence development for climate science, in this paper, we first contribute a multi-modal climate benchmark, i.e., ClimateBench-M, which aligns (1) the time series climate data from ERA5, (2) extreme weather events data from NOAA, and (3) satellite image data from NASA HLS based on a unified spatial-temporal granularity. Second, under each data modality, we also propose a simple but strong generative method that could produce competitive performance in weather forecasting, thunderstorm alerts, and crop segmentation tasks in the proposed ClimateBench-M. The data and code of ClimateBench-M are publicly available at https://github.com/iDEA-iSAIL-Lab-UIUC/ClimateBench-M.
Language in the Flow of Time: Time-Series-Paired Texts Weaved into a Unified Temporal Narrative
Feb 13, 2025While many advances in time series models focus exclusively on numerical data, research on multimodal time series, particularly those involving contextual textual information commonly encountered in real-world scenarios, remains in its infancy. Consequently, effectively integrating the text modality remains challenging. In this work, we highlight an intuitive yet significant observation that has been overlooked by existing works: time-series-paired texts exhibit periodic properties that closely mirror those of the original time series. Building on this insight, we propose a novel framework, Texts as Time Series (TaTS), which considers the time-series-paired texts to be auxiliary variables of the time series. TaTS can be plugged into any existing numerical-only time series models and enable them to handle time series data with paired texts effectively. Through extensive experiments on both multimodal time series forecasting and imputation tasks across benchmark datasets with various existing time series models, we demonstrate that TaTS can enhance predictive performance and achieve outperformance without modifying model architectures.
PyG-SSL: A Graph Self-Supervised Learning Toolkit
Dec 30, 2024



Graph Self-Supervised Learning (SSL) has emerged as a pivotal area of research in recent years. By engaging in pretext tasks to learn the intricate topological structures and properties of graphs using unlabeled data, these graph SSL models achieve enhanced performance, improved generalization, and heightened robustness. Despite the remarkable achievements of these graph SSL methods, their current implementation poses significant challenges for beginners and practitioners due to the complex nature of graph structures, inconsistent evaluation metrics, and concerns regarding reproducibility hinder further progress in this field. Recognizing the growing interest within the research community, there is an urgent need for a comprehensive, beginner-friendly, and accessible toolkit consisting of the most representative graph SSL algorithms. To address these challenges, we present a Graph SSL toolkit named PyG-SSL, which is built upon PyTorch and is compatible with various deep learning and scientific computing backends. Within the toolkit, we offer a unified framework encompassing dataset loading, hyper-parameter configuration, model training, and comprehensive performance evaluation for diverse downstream tasks. Moreover, we provide beginner-friendly tutorials and the best hyper-parameters of each graph SSL algorithm on different graph datasets, facilitating the reproduction of results. The GitHub repository of the library is https://github.com/iDEA-iSAIL-Lab-UIUC/pyg-ssl.
Can Graph Neural Networks Learn Language with Extremely Weak Text Supervision?
Dec 11, 2024



While great success has been achieved in building vision models with Contrastive Language-Image Pre-training (CLIP) over Internet-scale image-text pairs, building transferable Graph Neural Networks (GNNs) with CLIP pipeline is challenging because of three fundamental issues: the scarcity of labeled data and text supervision, different levels of downstream tasks, and the conceptual gaps between domains. In this work, to address these issues, we leverage multi-modal prompt learning to effectively adapt pre-trained GNN to downstream tasks and data, given only a few semantically labeled samples, each with extremely weak text supervision. Our new paradigm embeds the graphs directly in the same space as the Large Language Models (LLMs) by learning both graph prompts and text prompts simultaneously. To accomplish this, we improve state-of-the-art graph prompt method, and then propose the first graph-language multi-modal prompt learning approach for exploiting the knowledge in pre-trained models. Notably, due to the insufficient supervision for fine-tuning, in our paradigm, the pre-trained GNN and the LLM are kept frozen, so the learnable parameters are much fewer than fine-tuning any pre-trained model. Through extensive experiments on real-world datasets, we demonstrate the superior performance of our paradigm in few-shot, multi-task-level, and cross-domain settings. Moreover, we build the first CLIP-style zero-shot classification prototype that can generalize GNNs to unseen classes with extremely weak text supervision.
Multi-label Sequential Sentence Classification via Large Language Model
Nov 23, 2024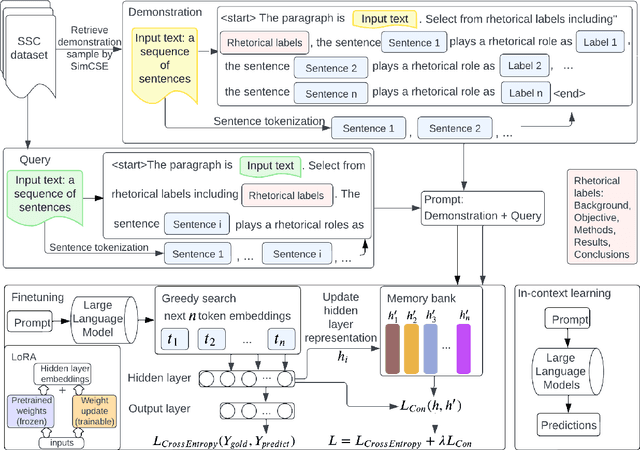
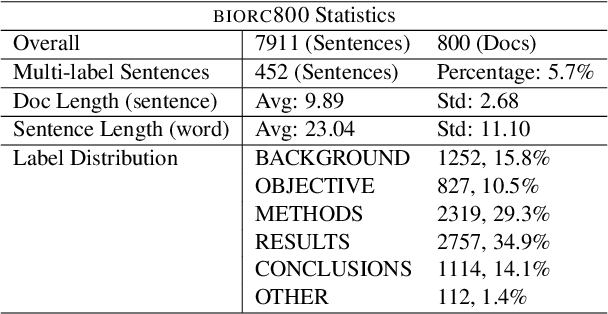

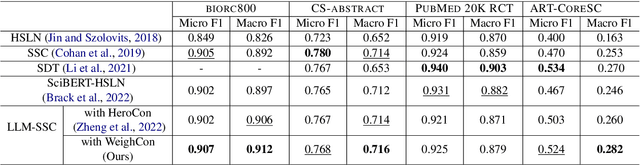
Sequential sentence classification (SSC) in scientific publications is crucial for supporting downstream tasks such as fine-grained information retrieval and extractive summarization. However, current SSC methods are constrained by model size, sequence length, and single-label setting. To address these limitations, this paper proposes LLM-SSC, a large language model (LLM)-based framework for both single- and multi-label SSC tasks. Unlike previous approaches that employ small- or medium-sized language models, the proposed framework utilizes LLMs to generate SSC labels through designed prompts, which enhance task understanding by incorporating demonstrations and a query to describe the prediction target. We also present a multi-label contrastive learning loss with auto-weighting scheme, enabling the multi-label classification task. To support our multi-label SSC analysis, we introduce and release a new dataset, biorc800, which mainly contains unstructured abstracts in the biomedical domain with manual annotations. Experiments demonstrate LLM-SSC's strong performance in SSC under both in-context learning and task-specific tuning settings. We release biorc800 and our code at: https://github.com/ScienceNLP-Lab/LLM-SSC.
Online Multi-modal Root Cause Analysis
Oct 13, 2024Root Cause Analysis (RCA) is essential for pinpointing the root causes of failures in microservice systems. Traditional data-driven RCA methods are typically limited to offline applications due to high computational demands, and existing online RCA methods handle only single-modal data, overlooking complex interactions in multi-modal systems. In this paper, we introduce OCEAN, a novel online multi-modal causal structure learning method for root cause localization. OCEAN employs a dilated convolutional neural network to capture long-term temporal dependencies and graph neural networks to learn causal relationships among system entities and key performance indicators. We further design a multi-factor attention mechanism to analyze and reassess the relationships among different metrics and log indicators/attributes for enhanced online causal graph learning. Additionally, a contrastive mutual information maximization-based graph fusion module is developed to effectively model the relationships across various modalities. Extensive experiments on three real-world datasets demonstrate the effectiveness and efficiency of our proposed method.