 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide-Prompt-Refine: a Training-Free, Structure-Aware Framework for Biomedical Abstract Generation
May 20, 2026Biomedical abstracts play a critical role in downstream NLP applications, such as information retrieval, biocuration, and biomedical knowledge discovery. However, a non-trivial number of biomedical articles do not have abstracts, diminishing the utility of these articles for downstream tasks. We propose DPR-BAG (Divide, Prompt, and Refine for Biomedical Abstract Generation), a training-free, zero-shot framework that generates coherent and factually grounded abstracts for biomedical articles with full text but no abstract. DPR-BAG decomposes full-text documents into structured rhetorical facets following the Background-Objective-Methods-Results-Conclusions (BOMRC) schema, performs parallel LLM-based summarization for each facet, and applies a final refinement stage to restore global discourse coherence. On PMC-MAD, a distribution-aligned dataset of 46,309 biomedical articles, DPR-BAG improves abstractive novelty over strong extractive and fine-tuned baselines, while maintaining factual consistency. Our ablation study reveals a counterintuitive finding: increasing prompt complexity or explicitly injecting entity-level guidance can degrade factual alignment, highlighting the importance of controlled prompting strategies. These findings underscore the potential of training-free, structure-aware frameworks for scalable biomedical abstract generation in low-resource settings. Our data and code are available at https://huggingface.co/datasets/pmc-mad/PMC-MAD and https://github.com/ScienceNLP-Lab/MultiTagger-v2/tree/main/DPR-BAG.
When Evidence Conflicts: Uncertainty and Order Effects in Retrieval-Augmented Biomedical Question Answering
May 13, 2026Biomedical retrieval-augmented large language models (LLMs) often face evidence that is incomplete, misleading, or internally contradictory, yet evaluation usually emphasizes answer accuracy under helpful context rather than reliability under conflict. Using HealthContradict, we evaluate six open-weight LLMs under five controlled evidence conditions: no retrieved context, correct-only context, incorrect-only context, and two mixed conditions containing both correct and contradictory documents in opposite orders. In this conflicting-evidence order contrast, where the same two documents are both present and only their order is reversed, accuracy drops for every model and 11.4%--25.2% of predictions flip. To support abstention in these difficult cases, we also evaluate a conflict-aware abstention score that combines model confidence with a detector of evidence conflict. In the two hardest conditions, this score improves selective accuracy over confidence-only, with mean gains of 7.2--33.4 points in incorrect-only (`IC') and 3.6--14.4 points in incorrect-first conflicting (`ICC') conditions across 75%, 50%, and 25% coverage. These results show that conflicting biomedical evidence is both an uncertainty and robustness problem and motivate evaluation and abstention methods that explicitly account for evidence disagreement.
Robust Biomedical Publication Type and Study Design Classification with Knowledge-Guided Perturbations
May 12, 2026Accurately and consistently indexing biomedical literature by publication type and study design is essential for supporting evidence synthesis and knowledge discovery. Prior work on automated publication type and study design indexing has primarily focused on expanding label coverage, enriching feature representations, and improving in-domain accuracy, with evaluation typically conducted on data drawn from the same distribution as training. Although pretrained biomedical language models achieve strong performance under these settings, models optimized for in-domain accuracy may rely on superficial lexical or dataset-specific cues, resulting in reduced robustness under distributional shift. In this study, we introduce an evaluation framework based on controlled semantic perturbations to assess the robustness of a publication type classifier and investigate robustness-oriented training strategies that combine entity masking and domain-adversarial training to mitigate reliance on spurious topical correlations. Our results show that the commonly observed trade-off between robustness and in-domain accuracy can be mitigated when robustness objectives are designed to selectively suppress non-task-defining features while preserving salient methodological signals. We find that these improvements arise from two complementary mechanisms: (1) increased reliance on explicit methodological cues when such cues are present in the input, and (2) reduced reliance on spurious domain-specific topical features. These findings highlight the importance of feature-level robustness analysis for publication type and study design classification and suggest that refining masking and adversarial objectives to more selectively suppress topical information may further improve robustness. Data, code, and models are available at: https://github.com/ScienceNLP-Lab/MultiTagger-v2/tree/main/ICHI
Use as Directed? A Comparison of Software Tools Intended to Check Rigor and Transparency of Published Work
Jul 23, 2025



The causes of the reproducibility crisis include lack of standardization and transparency in scientific reporting. Checklists such as ARRIVE and CONSORT seek to improve transparency, but they are not always followed by authors and peer review often fails to identify missing items. To address these issues, there are several automated tools that have been designed to check different rigor criteria. We have conducted a broad comparison of 11 automated tools across 9 different rigor criteria from the ScreenIT group. We found some criteria, including detecting open data, where the combination of tools showed a clear winner, a tool which performed much better than other tools. In other cases, including detection of inclusion and exclusion criteria, the combination of tools exceeded the performance of any one tool. We also identified key areas where tool developers should focus their effort to make their tool maximally useful. We conclude with a set of insights and recommendations for stakeholders in the development of rigor and transparency detection tools. The code and data for the study is available at https://github.com/PeterEckmann1/tool-comparison.
Multi-label Sequential Sentence Classification via Large Language Model
Nov 23, 2024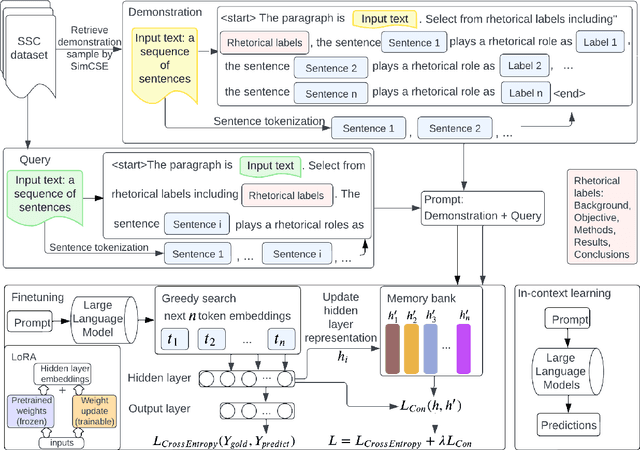
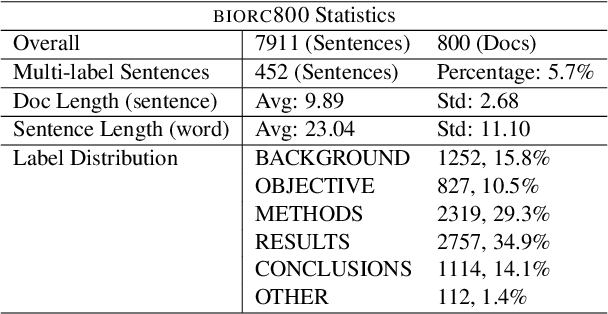

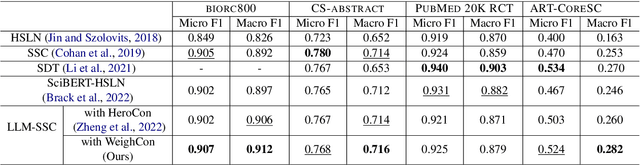
Sequential sentence classification (SSC) in scientific publications is crucial for supporting downstream tasks such as fine-grained information retrieval and extractive summarization. However, current SSC methods are constrained by model size, sequence length, and single-label setting. To address these limitations, this paper proposes LLM-SSC, a large language model (LLM)-based framework for both single- and multi-label SSC tasks. Unlike previous approaches that employ small- or medium-sized language models, the proposed framework utilizes LLMs to generate SSC labels through designed prompts, which enhance task understanding by incorporating demonstrations and a query to describe the prediction target. We also present a multi-label contrastive learning loss with auto-weighting scheme, enabling the multi-label classification task. To support our multi-label SSC analysis, we introduce and release a new dataset, biorc800, which mainly contains unstructured abstracts in the biomedical domain with manual annotations. Experiments demonstrate LLM-SSC's strong performance in SSC under both in-context learning and task-specific tuning settings. We release biorc800 and our code at: https://github.com/ScienceNLP-Lab/LLM-SSC.
DiMB-RE: Mining the Scientific Literature for Diet-Microbiome Associations
Sep 29, 2024
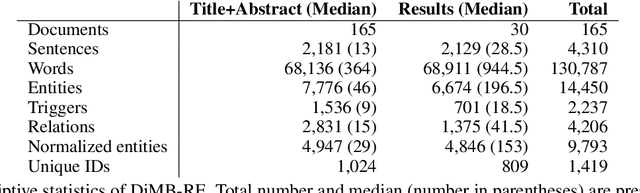
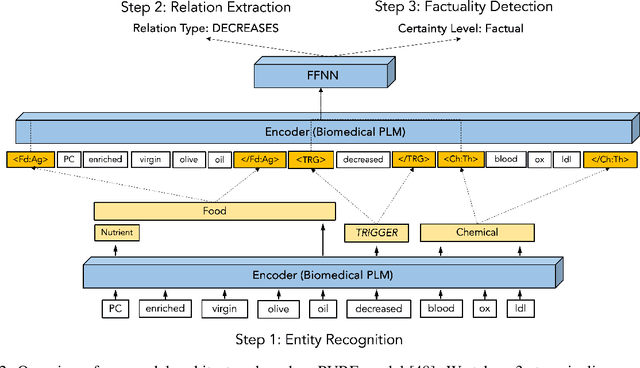
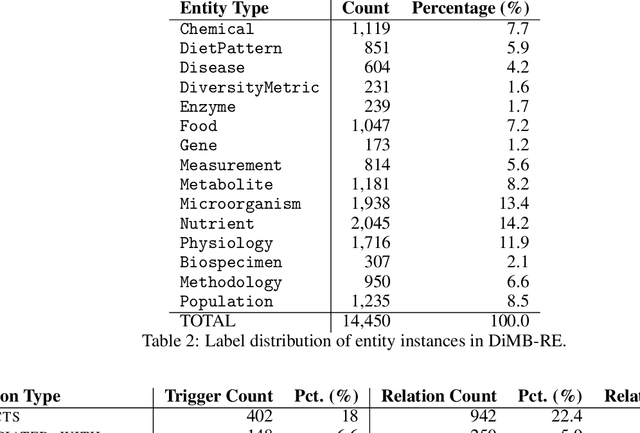
Motivation: The gut microbiota has recently emerged as a key factor that underpins certain connections between diet and human health. A tremendous amount of knowledge has been amassed from experimental studies on diet, human metabolism and microbiome. However, this evidence remains mostly buried in scientific publications, and biomedical literature mining in this domain remains scarce. We developed DiMB-RE, a comprehensive corpus annotated with 15 entity types (e.g., Nutrient, Microorganism) and 13 relation types (e.g., increases, improves) capturing diet-microbiome associations. We also trained and evaluated state-of-the-art natural language processing (NLP) models for named entity, trigger, and relation extraction as well as factuality detection using DiMB-RE. Results: DiMB-RE consists of 14,450 entities and 4,206 relationships from 165 articles. While NLP models performed reasonably well for named entity recognition (0.760 F$_{1}$), end-to-end relation extraction performance was modest (0.356 F$_{1}$), partly due to missed entities and triggers as well as cross-sentence relations. Conclusions: To our knowledge, DiMB-RE is largest and most diverse dataset focusing on diet-microbiome interactions. It can serve as a benchmark corpus for biomedical literature mining. Availability: DiMB-RE and the NLP models are available at https://github.com/ScienceNLP-Lab/DiMB-RE.
BiomedRAG: A Retrieval Augmented Large Language Model for Biomedicine
May 02, 2024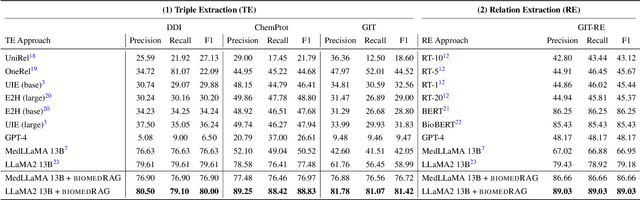
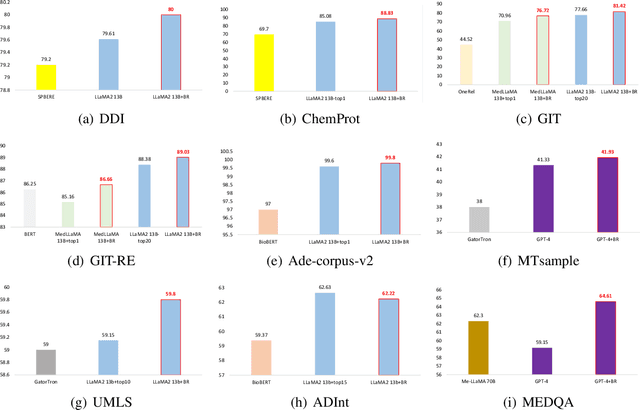
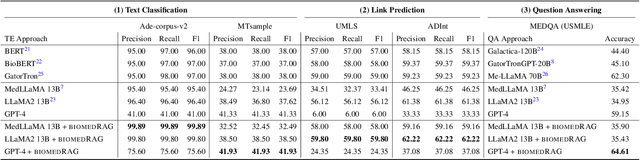
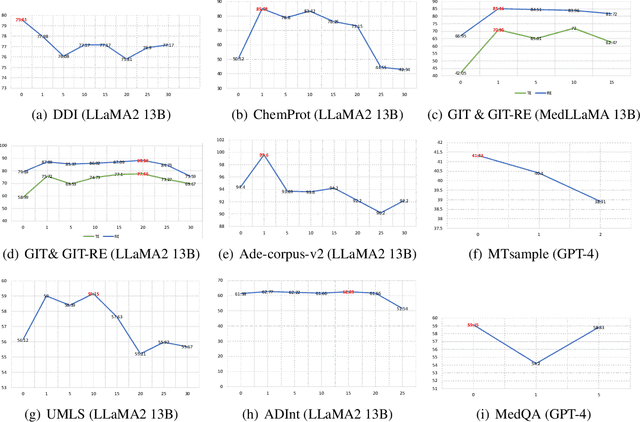
Large Language Models (LLMs) have swiftly emerged as vital resources for different applications in the biomedical and healthcare domains; however, these models encounter issues such as generating inaccurate information or hallucinations. Retrieval-augmented generation provided a solution for these models to update knowledge and enhance their performance. In contrast to previous retrieval-augmented LMs, which utilize specialized cross-attention mechanisms to help LLM encode retrieved text, BiomedRAG adopts a simpler approach by directly inputting the retrieved chunk-based documents into the LLM. This straightforward design is easily applicable to existing retrieval and language models, effectively bypassing noise information in retrieved documents, particularly in noise-intensive tasks. Moreover, we demonstrate the potential for utilizing the LLM to supervise the retrieval model in the biomedical domain, enabling it to retrieve the document that assists the LM in improving its predictions. Our experiments reveal that with the tuned scorer,\textsc{ BiomedRAG} attains superior performance across 5 biomedical NLP tasks, encompassing information extraction (triple extraction, relation extraction), text classification, link prediction, and question-answering, leveraging over 9 datasets. For instance, in the triple extraction task, \textsc{BiomedRAG} outperforms other triple extraction systems with micro-F1 scores of 81.42 and 88.83 on GIT and ChemProt corpora, respectively.
Examining the Causal Effect of First Names on Language Models: The Case of Social Commonsense Reasoning
Jun 01, 2023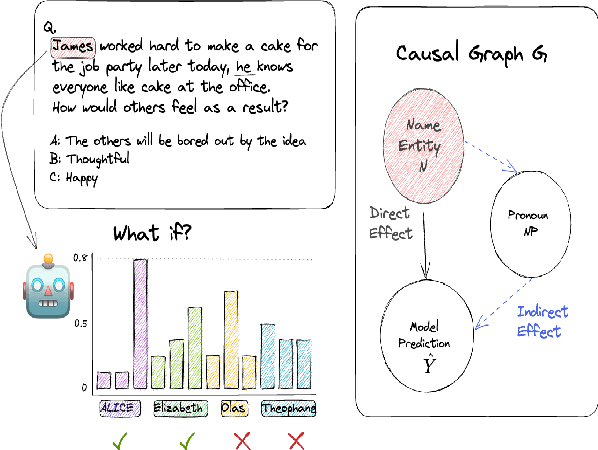
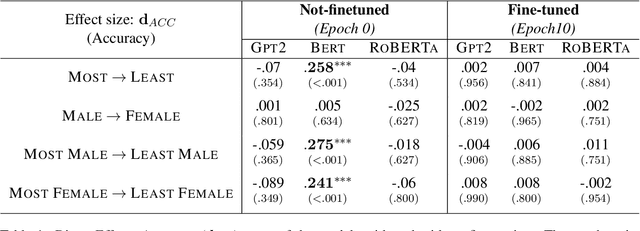
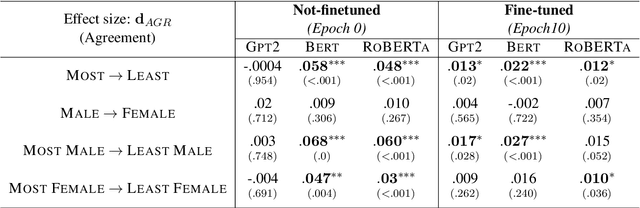
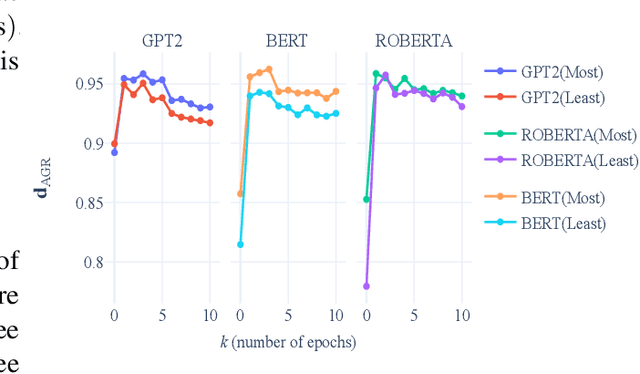
As language models continue to be integrated into applications of personal and societal relevance, ensuring these models' trustworthiness is crucial, particularly with respect to producing consistent outputs regardless of sensitive attributes. Given that first names may serve as proxies for (intersectional) socio-demographic representations, it is imperative to examine the impact of first names on commonsense reasoning capabilities. In this paper, we study whether a model's reasoning given a specific input differs based on the first names provided. Our underlying assumption is that the reasoning about Alice should not differ from the reasoning about James. We propose and implement a controlled experimental framework to measure the causal effect of first names on commonsense reasoning, enabling us to distinguish between model predictions due to chance and caused by actual factors of interest. Our results indicate that the frequency of first names has a direct effect on model prediction, with less frequent names yielding divergent predictions compared to more frequent names. To gain insights into the internal mechanisms of models that are contributing to these behaviors, we also conduct an in-depth explainable analysis. Overall, our findings suggest that to ensure model robustness, it is essential to augment datasets with more diverse first names during the configuration stage.
Complementary and Integrative Health Lexicon (CIHLex) and Entity Recognition in the Literature
May 27, 2023Objective: Our study aimed to construct an exhaustive Complementary and Integrative Health (CIH) Lexicon (CIHLex) to better represent the often underrepresented physical and psychological CIH approaches in standard terminologies. We also intended to apply advanced Natural Language Processing (NLP) models such as Bidirectional Encoder Representations from Transformers (BERT) and GPT-3.5 Turbo for CIH named entity recognition, evaluating their performance against established models like MetaMap and CLAMP. Materials and Methods: We constructed the CIHLex by integrating various resources, compiling and integrating data from biomedical literature and relevant knowledge bases. The Lexicon encompasses 198 unique concepts with 1090 corresponding unique terms. We matched these concepts to the Unified Medical Language System (UMLS). Additionally, we developed and utilized BERT models and compared their efficiency in CIH named entity recognition to that of other models such as MetaMap, CLAMP, and GPT3.5-turbo. Results: From the 198 unique concepts in CIHLex, 62.1% could be matched to at least one term in the UMLS. Moreover, 75.7% of the mapped UMLS Concept Unique Identifiers (CUIs) were categorized as "Therapeutic or Preventive Procedure." Among the models applied to CIH named entity recognition, BLUEBERT delivered the highest macro average F1-score of 0.90, surpassing other models. Conclusion: Our CIHLex significantly augments representation of CIH approaches in biomedical literature. Demonstrating the utility of advanced NLP models, BERT notably excelled in CIH entity recognition. These results highlight promising strategies for enhancing standardization and recognition of CIH terminology in biomedical contexts.
Commonsense-Aware Prompting for Controllable Empathetic Dialogue Generation
Feb 02, 2023Improving the emotional awareness of pre-trained language models is an emerging important problem for dialogue generation tasks. Although prior studies have introduced methods to improve empathetic dialogue generation, few have discussed how to incorporate commonsense knowledge into pre-trained language models for controllable dialogue generation. In this study, we propose a novel framework that improves empathetic dialogue generation using pre-trained language models by 1) incorporating commonsense knowledge through prompt verbalization, and 2) controlling dialogue generation using a strategy-driven future discriminator. We conducted experiments to reveal that both the incorporation of social commonsense knowledge and enforcement of control over generation help to improve generation performance. Finally, we discuss the implications of our study for future research.