 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Causal Effect of First Names on Language Models: The Case of Social Commonsense Reasoning
Paper and Code
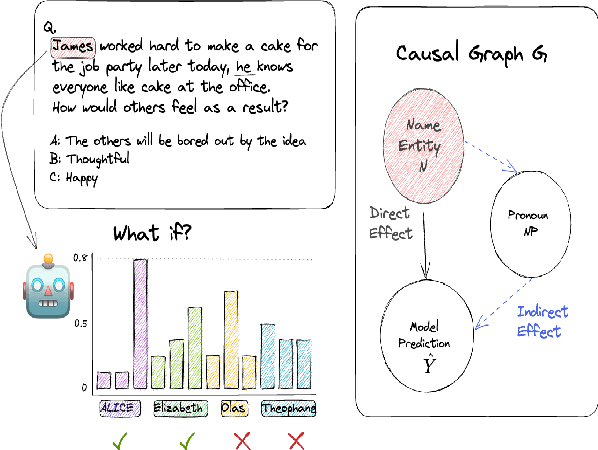
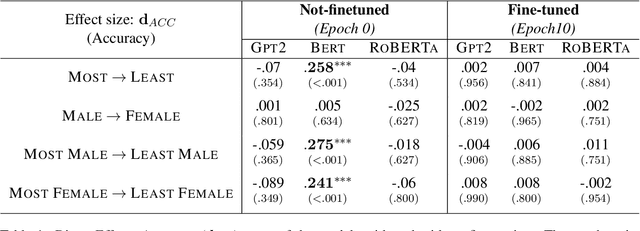
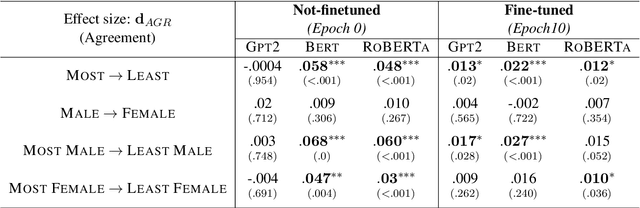
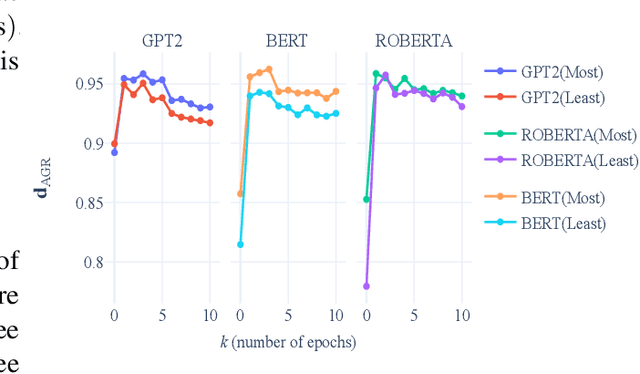
As language models continue to be integrated into applications of personal and societal relevance, ensuring these models' trustworthiness is crucial, particularly with respect to producing consistent outputs regardless of sensitive attributes. Given that first names may serve as proxies for (intersectional) socio-demographic representations, it is imperative to examine the impact of first names on commonsense reasoning capabilities. In this paper, we study whether a model's reasoning given a specific input differs based on the first names provided. Our underlying assumption is that the reasoning about Alice should not differ from the reasoning about James. We propose and implement a controlled experimental framework to measure the causal effect of first names on commonsense reasoning, enabling us to distinguish between model predictions due to chance and caused by actual factors of interest. Our results indicate that the frequency of first names has a direct effect on model prediction, with less frequent names yielding divergent predictions compared to more frequent names. To gain insights into the internal mechanisms of models that are contributing to these behaviors, we also conduct an in-depth explainable analysis. Overall, our findings suggest that to ensure model robustness, it is essential to augment datasets with more diverse first names during the configuration stage.