 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrug Repurposing for COVID-19 via Knowledge Graph Completion
Oct 19, 2020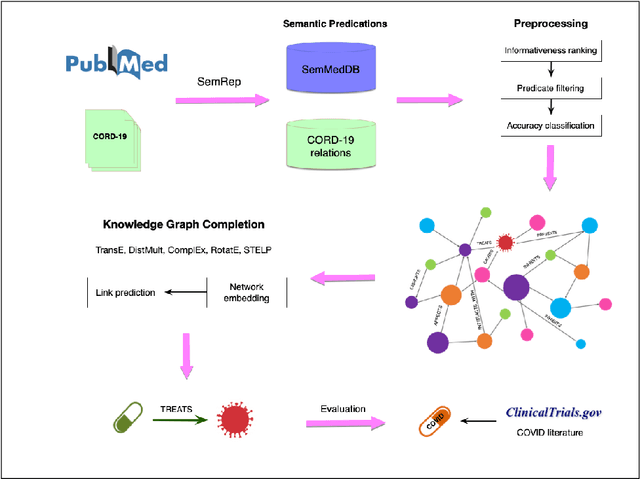
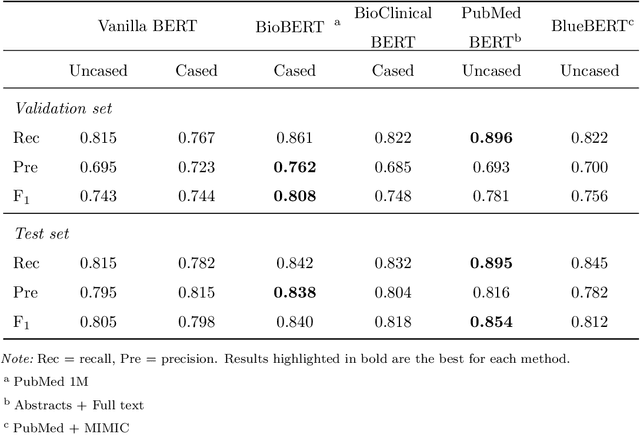
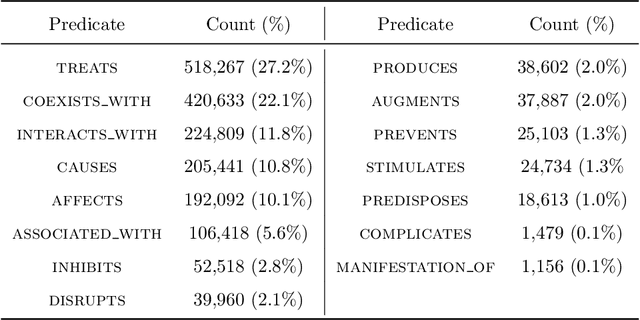
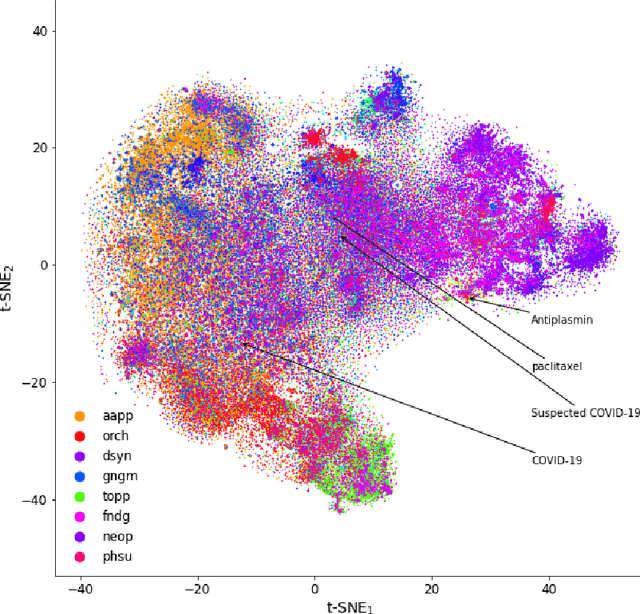
Objective: To discover candidate drugs to repurpose for COVID-19 using literature-derived knowledge and knowledge graph completion methods. Methods: We propose a novel, integrative, and neural network-based literature-based discovery (LBD) approach to identify drug candidates from both PubMed and COVID-19-focused research literature. Our approach relies on semantic triples extracted using SemRep (via SemMedDB). We identified an informative subset of semantic triples using filtering rules and an accuracy classifier developed on a BERT variant, and used this subset to construct a knowledge graph. Five SOTA, neural knowledge graph completion algorithms were used to predict drug repurposing candidates. The models were trained and assessed using a time slicing approach and the predicted drugs were compared with a list of drugs reported in the literature and evaluated in clinical trials. These models were complemented by a discovery pattern-based approach. Results: Accuracy classifier based on PubMedBERT achieved the best performance (F1= 0.854) in classifying semantic predications. Among five knowledge graph completion models, TransE outperformed others (MR = 0.923, Hits@1=0.417). Some known drugs linked to COVID-19 in the literature were identified, as well as some candidate drugs that have not yet been studied. Discovery patterns enabled generation of plausible hypotheses regarding the relationships between the candidate drugs and COVID-19. Among them, five highly ranked and novel drugs (paclitaxel, SB 203580, alpha 2-antiplasmin, pyrrolidine dithiocarbamate, and butylated hydroxytoluene) with their mechanistic explanations were further discussed. Conclusion: We show that an LBD approach can be feasible for discovering drug candidates for COVID-19, and for generating mechanistic explanations. Our approach can be generalized to other diseases as well as to other clinical questions.
Chi-square-based scoring function for categorization of MEDLINE citations
Jun 05, 2010
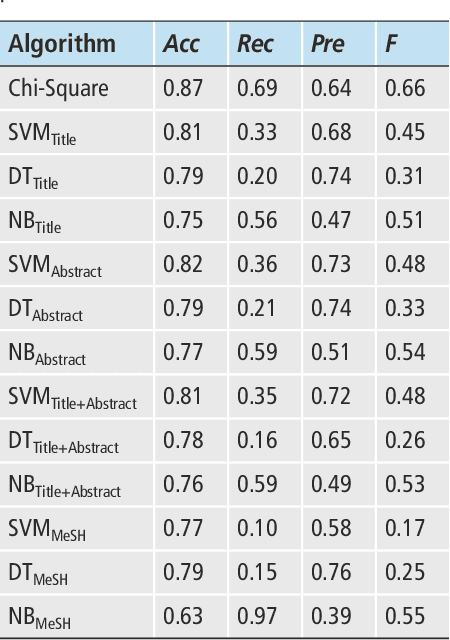
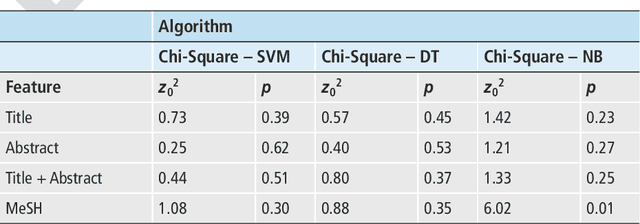
Objectives: Text categorization has been used in biomedical informatics for identifying documents containing relevant topics of interest. We developed a simple method that uses a chi-square-based scoring function to determine the likelihood of MEDLINE citations containing genetic relevant topic. Methods: Our procedure requires construction of a genetic and a nongenetic domain document corpus. We used MeSH descriptors assigned to MEDLINE citations for this categorization task. We compared frequencies of MeSH descriptors between two corpora applying chi-square test. A MeSH descriptor was considered to be a positive indicator if its relative observed frequency in the genetic domain corpus was greater than its relative observed frequency in the nongenetic domain corpus. The output of the proposed method is a list of scores for all the citations, with the highest score given to those citations containing MeSH descriptors typical for the genetic domain. Results: Validation was done on a set of 734 manually annotated MEDLINE citations. It achieved predictive accuracy of 0.87 with 0.69 recall and 0.64 precision. We evaluated the method by comparing it to three machine learning algorithms (support vector machines, decision trees, na\"ive Bayes). Although the differences were not statistically significantly different, results showed that our chi-square scoring performs as good as compared machine learning algorithms. Conclusions: We suggest that the chi-square scoring is an effective solution to help categorize MEDLINE citations. The algorithm is implemented in the BITOLA literature-based discovery support system as a preprocessor for gene symbol disambiguation process.
* 34 pages, 2 figures