 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining word embeddings with perfect fidelity: Case study in research impact prediction
Sep 24, 2024
Best performing approaches for scholarly document quality prediction are based on embedding models, which do not allow direct explanation of classifiers as distinct words no longer correspond to the input features for model training. Although model-agnostic explanation methods such as Local interpretable model-agnostic explanations (LIME) can be applied, these produce results with questionable correspondence to the ML model. We introduce a new feature importance method, Self-model Rated Entities (SMER), for logistic regression-based classification models trained on word embeddings. We show that SMER has theoretically perfect fidelity with the explained model, as its prediction corresponds exactly to the average of predictions for individual words in the text. SMER allows us to reliably determine which words or entities positively contribute to predicting impactful articles. Quantitative and qualitative evaluation is performed through five diverse experiments conducted on 50.000 research papers from the CORD-19 corpus. Through an AOPC curve analysis, we experimentally demonstrate that SMER produces better explanations than LIME for logistic regression.
The Artificial Intelligence Ontology: LLM-assisted construction of AI concept hierarchies
Apr 03, 2024


The Artificial Intelligence Ontology (AIO) is a systematization of artificial intelligence (AI) concepts, methodologies, and their interrelations. Developed via manual curation, with the additional assistance of large language models (LLMs), AIO aims to address the rapidly evolving landscape of AI by providing a comprehensive framework that encompasses both technical and ethical aspects of AI technologies. The primary audience for AIO includes AI researchers, developers, and educators seeking standardized terminology and concepts within the AI domain. The ontology is structured around six top-level branches: Networks, Layers, Functions, LLMs, Preprocessing, and Bias, each designed to support the modular composition of AI methods and facilitate a deeper understanding of deep learning architectures and ethical considerations in AI. AIO's development utilized the Ontology Development Kit (ODK) for its creation and maintenance, with its content being dynamically updated through AI-driven curation support. This approach not only ensures the ontology's relevance amidst the fast-paced advancements in AI but also significantly enhances its utility for researchers, developers, and educators by simplifying the integration of new AI concepts and methodologies. The ontology's utility is demonstrated through the annotation of AI methods data in a catalog of AI research publications and the integration into the BioPortal ontology resource, highlighting its potential for cross-disciplinary research. The AIO ontology is open source and is available on GitHub (https://github.com/berkeleybop/artificial-intelligence-ontology) and BioPortal (https://bioportal.bioontology.org/ontologies/AIO).
An Open-Source Knowledge Graph Ecosystem for the Life Sciences
Jul 11, 2023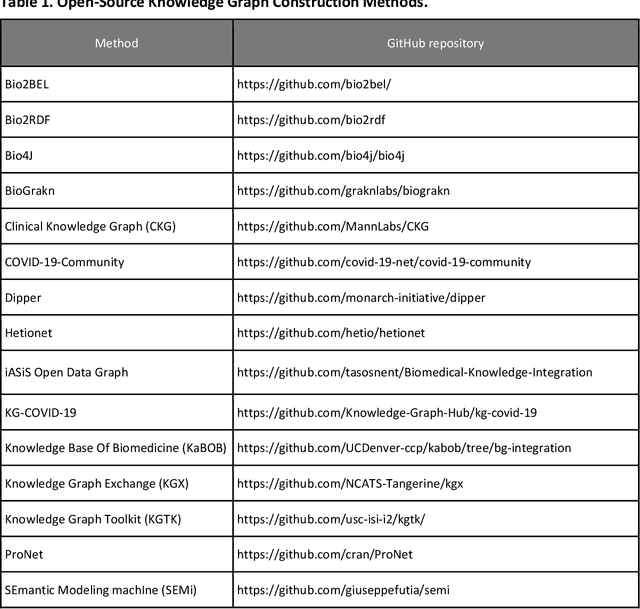
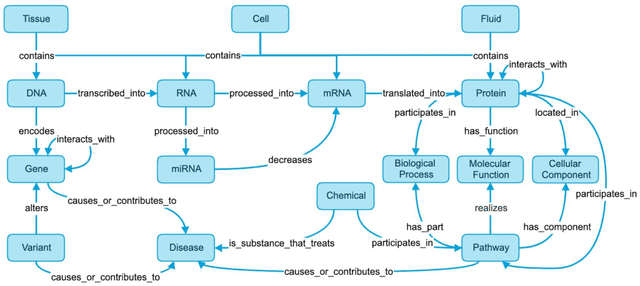
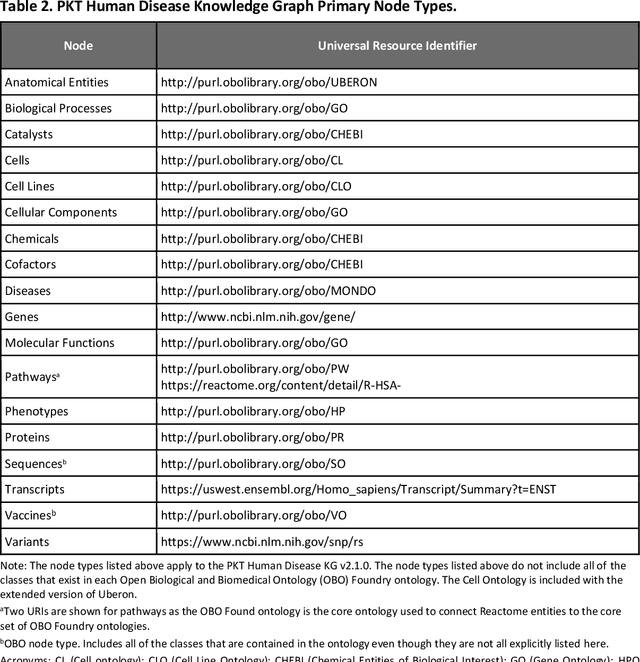
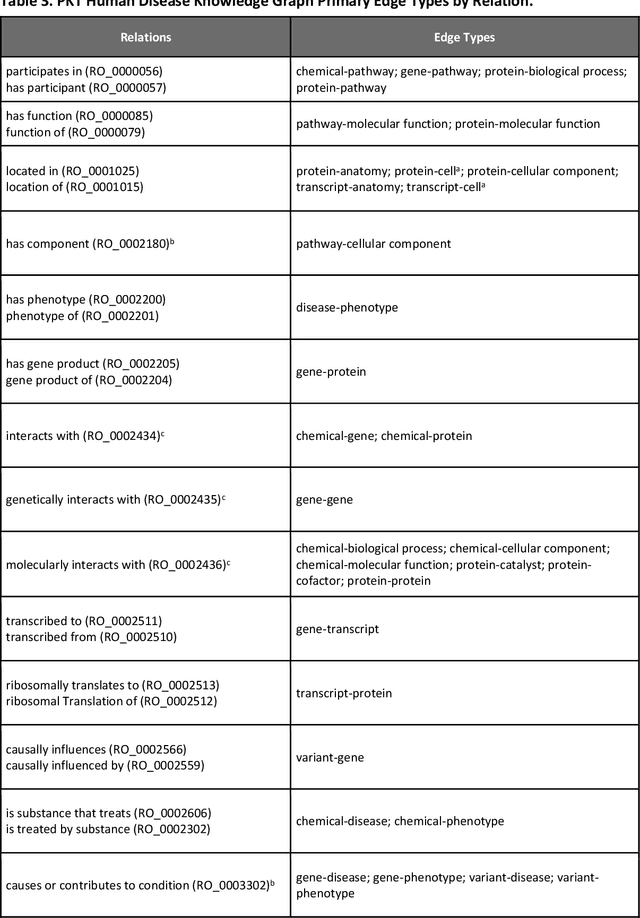
Translational research requires data at multiple scales of biological organization. Advancements in sequencing and multi-omics technologies have increased the availability of these data but researchers face significant integration challenges. Knowledge graphs (KGs) are used to model complex phenomena, and methods exist to automatically construct them. However, tackling complex biomedical integration problems requires flexibility in the way knowledge is modeled. Moreover, existing KG construction methods provide robust tooling at the cost of fixed or limited choices among knowledge representation models. PheKnowLator (Phenotype Knowledge Translator) is a semantic ecosystem for automating the FAIR (Findable, Accessible, Interoperable, and Reusable) construction of ontologically grounded KGs with fully customizable knowledge representation. The ecosystem includes KG construction resources (e.g., data preparation APIs), analysis tools (e.g., SPARQL endpoints and abstraction algorithms), and benchmarks (e.g., prebuilt KGs and embeddings). We evaluate the ecosystem by surveying open-source KG construction methods and analyzing its computational performance when constructing 12 large-scale KGs. With flexible knowledge representation, PheKnowLator enables fully customizable KGs without compromising performance or usability.
Gene Set Summarization using Large Language Models
May 25, 2023Molecular biologists frequently interpret gene lists derived from high-throughput experiments and computational analysis. This is typically done as a statistical enrichment analysis that measures the over- or under-representation of biological function terms associated with genes or their properties, based on curated assertions from a knowledge base (KB) such as the Gene Ontology (GO). Interpreting gene lists can also be framed as a textual summarization task, enabling the use of Large Language Models (LLMs), potentially utilizing scientific texts directly and avoiding reliance on a KB. We developed SPINDOCTOR (Structured Prompt Interpolation of Natural Language Descriptions of Controlled Terms for Ontology Reporting), a method that uses GPT models to perform gene set function summarization as a complement to standard enrichment analysis. This method can use different sources of gene functional information: (1) structured text derived from curated ontological KB annotations, (2) ontology-free narrative gene summaries, or (3) direct model retrieval. We demonstrate that these methods are able to generate plausible and biologically valid summary GO term lists for gene sets. However, GPT-based approaches are unable to deliver reliable scores or p-values and often return terms that are not statistically significant. Crucially, these methods were rarely able to recapitulate the most precise and informative term from standard enrichment, likely due to an inability to generalize and reason using an ontology. Results are highly nondeterministic, with minor variations in prompt resulting in radically different term lists. Our results show that at this point, LLM-based methods are unsuitable as a replacement for standard term enrichment analysis and that manual curation of ontological assertions remains necessary.
Structured prompt interrogation and recursive extraction of semantics (SPIRES): A method for populating knowledge bases using zero-shot learning
Apr 05, 2023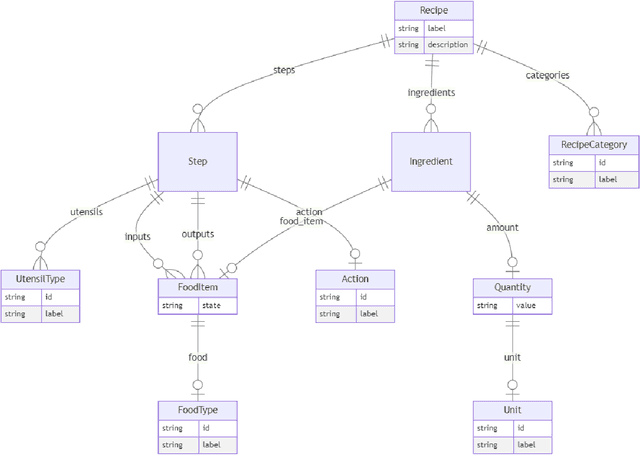
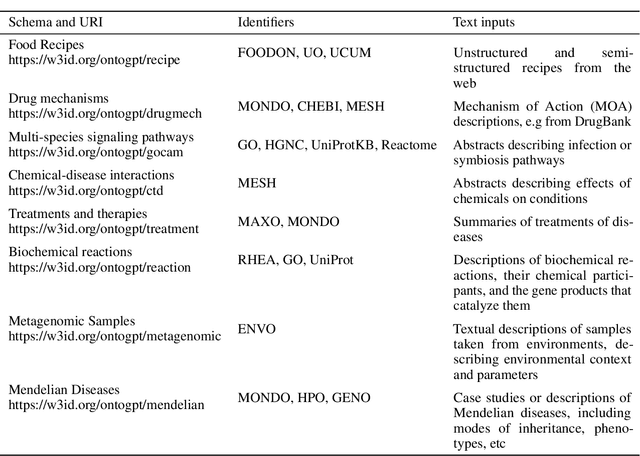
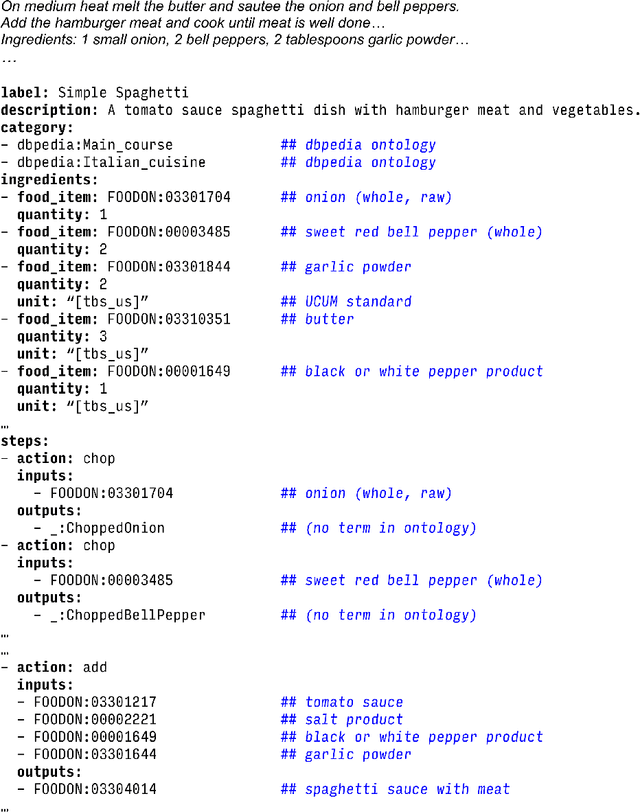

Creating knowledge bases and ontologies is a time consuming task that relies on a manual curation. AI/NLP approaches can assist expert curators in populating these knowledge bases, but current approaches rely on extensive training data, and are not able to populate arbitrary complex nested knowledge schemas. Here we present Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES), a Knowledge Extraction approach that relies on the ability of Large Language Models (LLMs) to perform zero-shot learning (ZSL) and general-purpose query answering from flexible prompts and return information conforming to a specified schema. Given a detailed, user-defined knowledge schema and an input text, SPIRES recursively performs prompt interrogation against GPT-3+ to obtain a set of responses matching the provided schema. SPIRES uses existing ontologies and vocabularies to provide identifiers for all matched elements. We present examples of use of SPIRES in different domains, including extraction of food recipes, multi-species cellular signaling pathways, disease treatments, multi-step drug mechanisms, and chemical to disease causation graphs. Current SPIRES accuracy is comparable to the mid-range of existing Relation Extraction (RE) methods, but has the advantage of easy customization, flexibility, and, crucially, the ability to perform new tasks in the absence of any training data. This method supports a general strategy of leveraging the language interpreting capabilities of LLMs to assemble knowledge bases, assisting manual knowledge curation and acquisition while supporting validation with publicly-available databases and ontologies external to the LLM. SPIRES is available as part of the open source OntoGPT package: https://github.com/ monarch-initiative/ontogpt.
Developing a Knowledge Graph Framework for Pharmacokinetic Natural Product-Drug Interactions
Sep 24, 2022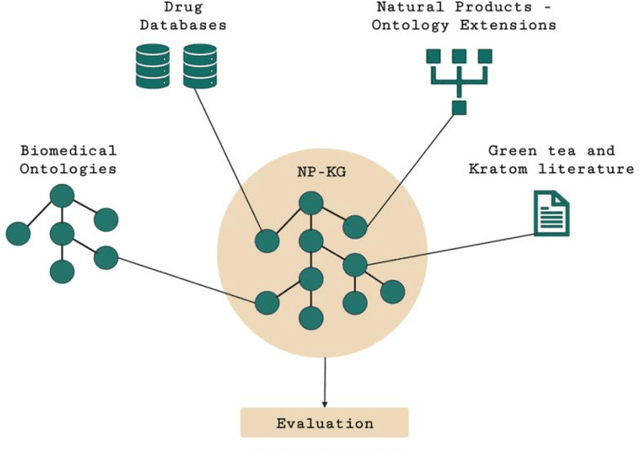
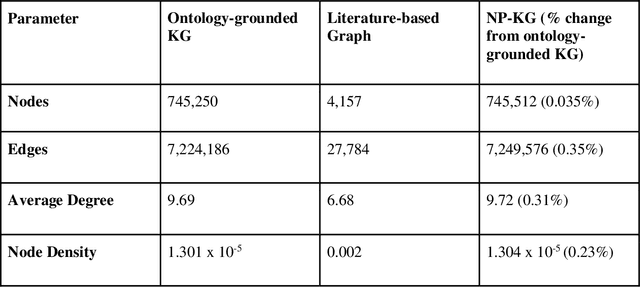

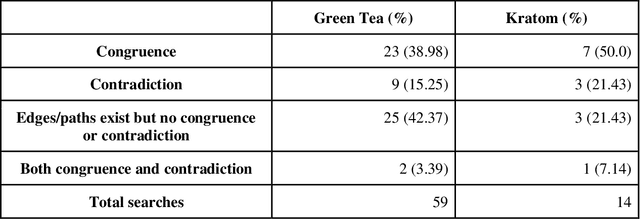
Pharmacokinetic natural product-drug interactions (NPDIs) occur when botanical natural products are co-consumed with pharmaceutical drugs. Understanding mechanisms of NPDIs is key to preventing adverse events. We constructed a knowledge graph framework, NP-KG, as a step toward computational discovery of pharmacokinetic NPDIs. NP-KG is a heterogeneous KG with biomedical ontologies, linked data, and full texts of the scientific literature, constructed with the Phenotype Knowledge Translator framework and the semantic relation extraction systems, SemRep and Integrated Network and Dynamic Reasoning Assembler. NP-KG was evaluated with case studies of pharmacokinetic green tea- and kratom-drug interactions through path searches and meta-path discovery to determine congruent and contradictory information compared to ground truth data. The fully integrated NP-KG consisted of 745,512 nodes and 7,249,576 edges. Evaluation of NP-KG resulted in congruent (38.98% for green tea, 50% for kratom), contradictory (15.25% for green tea, 21.43% for kratom), and both congruent and contradictory (15.25% for green tea, 21.43% for kratom) information. Potential pharmacokinetic mechanisms for several purported NPDIs, including the green tea-raloxifene, green tea-nadolol, kratom-midazolam, kratom-quetiapine, and kratom-venlafaxine interactions were congruent with the published literature. NP-KG is the first KG to integrate biomedical ontologies with full texts of the scientific literature focused on natural products. We demonstrate the application of NP-KG to identify pharmacokinetic interactions involving enzymes, transporters, and pharmaceutical drugs. We envision that NP-KG will facilitate improved human-machine collaboration to guide researchers in future studies of pharmacokinetic NPDIs. The NP-KG framework is publicly available at https://doi.org/10.5281/zenodo.6814507 and https://github.com/sanyabt/np-kg.
GraPE: fast and scalable Graph Processing and Embedding
Oct 12, 2021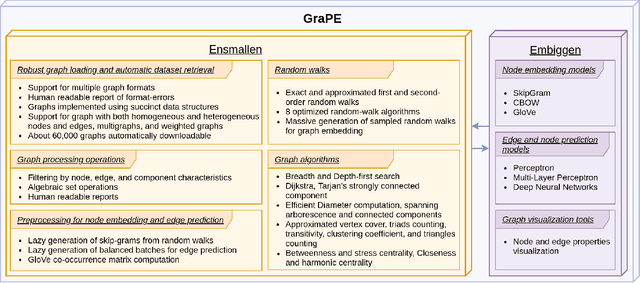
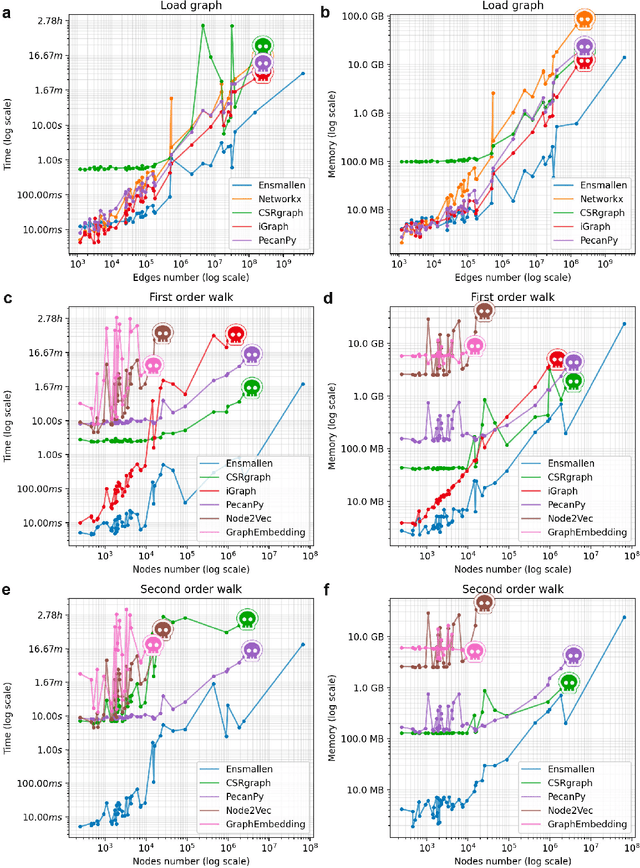
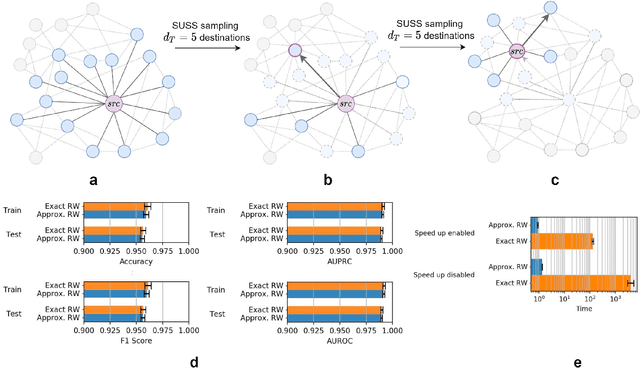
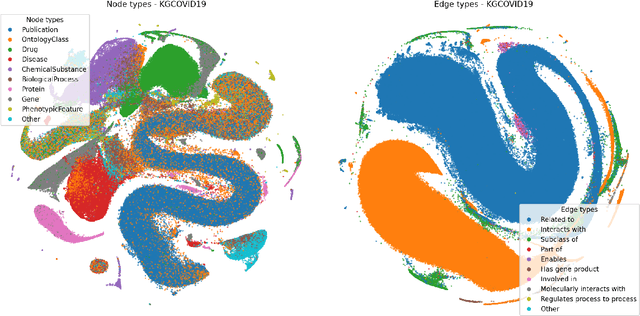
Graph Representation Learning methods have enabled a wide range of learning problems to be addressed for data that can be represented in graph form. Nevertheless, several real world problems in economy, biology, medicine and other fields raised relevant scaling problems with existing methods and their software implementation, due to the size of real world graphs characterized by millions of nodes and billions of edges. We present GraPE, a software resource for graph processing and random walk based embedding, that can scale with large and high-degree graphs and significantly speed up-computation. GraPE comprises specialized data structures, algorithms, and a fast parallel implementation that displays everal orders of magnitude improvement in empirical space and time complexity compared to state of the art software resources, with a corresponding boost in the performance of machine learning methods for edge and node label prediction and for the unsupervised analysis of graphs.GraPE is designed to run on laptop and desktop computers, as well as on high performance computing clusters