 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining word embeddings with perfect fidelity: Case study in research impact prediction
Sep 24, 2024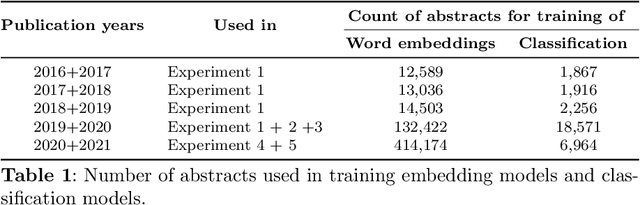
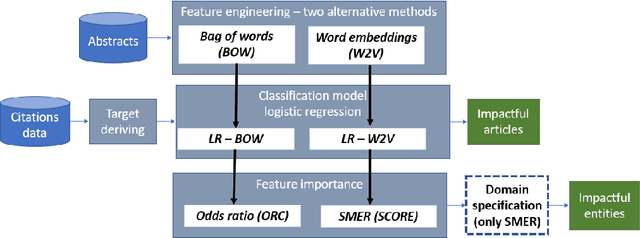
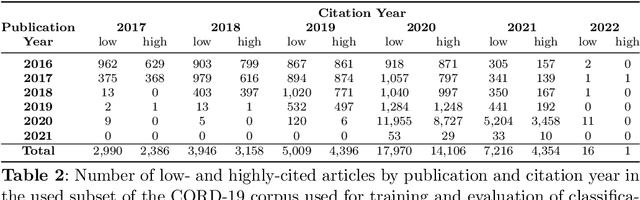
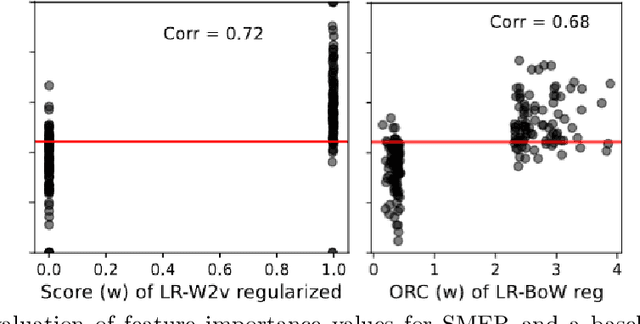
Best performing approaches for scholarly document quality prediction are based on embedding models, which do not allow direct explanation of classifiers as distinct words no longer correspond to the input features for model training. Although model-agnostic explanation methods such as Local interpretable model-agnostic explanations (LIME) can be applied, these produce results with questionable correspondence to the ML model. We introduce a new feature importance method, Self-model Rated Entities (SMER), for logistic regression-based classification models trained on word embeddings. We show that SMER has theoretically perfect fidelity with the explained model, as its prediction corresponds exactly to the average of predictions for individual words in the text. SMER allows us to reliably determine which words or entities positively contribute to predicting impactful articles. Quantitative and qualitative evaluation is performed through five diverse experiments conducted on 50.000 research papers from the CORD-19 corpus. Through an AOPC curve analysis, we experimentally demonstrate that SMER produces better explanations than LIME for logistic regression.
Neurosymbolic Methods for Rule Mining
Aug 11, 2024

In this chapter, we address the problem of rule mining, beginning with essential background information, including measures of rule quality. We then explore various rule mining methodologies, categorized into three groups: inductive logic programming, path sampling and generalization, and linear programming. Following this, we delve into neurosymbolic methods, covering topics such as the integration of deep learning with rules, the use of embeddings for rule learning, and the application of large language models in rule learning.
Quantitative CBA: Small and Comprehensible Association Rule Classification Models
Nov 28, 2017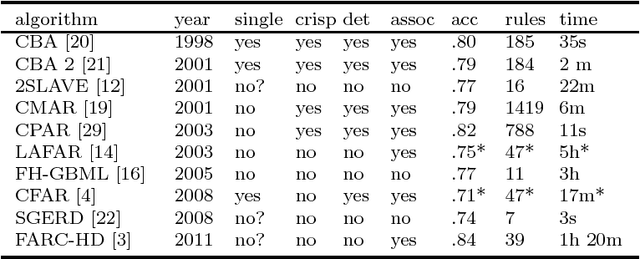
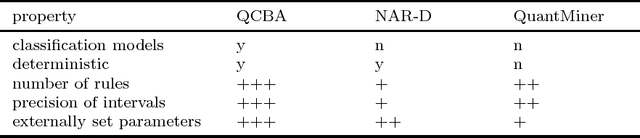
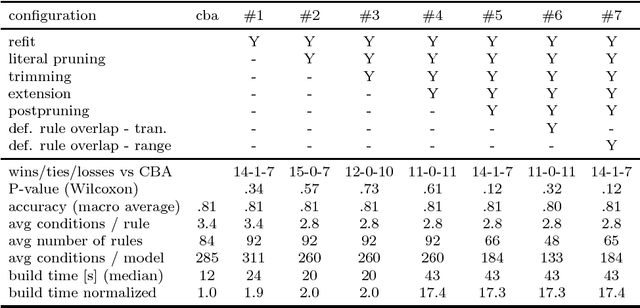
Quantitative CBA is a postprocessing algorithm for association rule classification algorithm CBA (Liu et al, 1998). QCBA uses original, undiscretized numerical attributes to optimize the discovered association rules, refining the boundaries of literals in the antecedent of the rules produced by CBA. Some rules as well as literals from the rules can consequently be removed, which makes the resulting classifier smaller. One-rule classification and crisp rules make CBA classification models possibly most comprehensible among all association rule classification algorithms. These viable properties are retained by QCBA. The postprocessing is conceptually fast, because it is performed on a relatively small number of rules that passed data coverage pruning in CBA. Benchmark of our QCBA approach on 22 UCI datasets shows average 53% decrease in the total size of the model as measured by the total number of conditions in all rules. Model accuracy remains on the same level as for CBA.