 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining word embeddings with perfect fidelity: Case study in research impact prediction
Paper and Code
Sep 24, 2024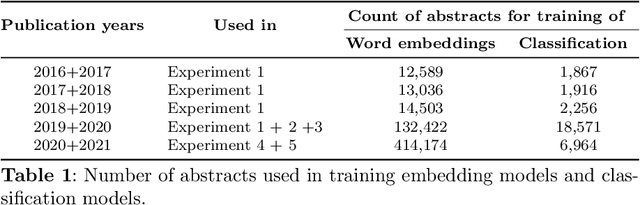
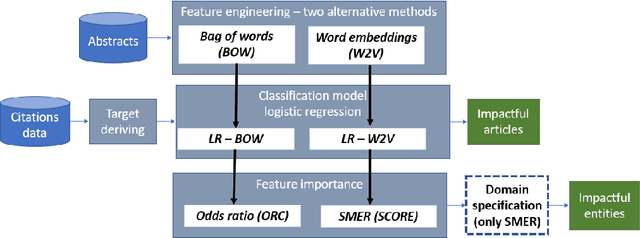
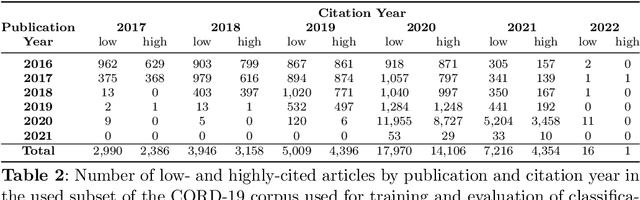
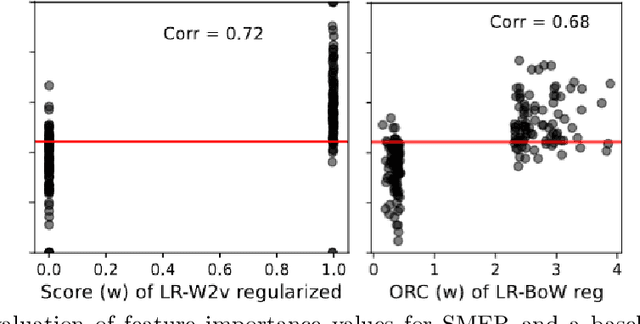
Best performing approaches for scholarly document quality prediction are based on embedding models, which do not allow direct explanation of classifiers as distinct words no longer correspond to the input features for model training. Although model-agnostic explanation methods such as Local interpretable model-agnostic explanations (LIME) can be applied, these produce results with questionable correspondence to the ML model. We introduce a new feature importance method, Self-model Rated Entities (SMER), for logistic regression-based classification models trained on word embeddings. We show that SMER has theoretically perfect fidelity with the explained model, as its prediction corresponds exactly to the average of predictions for individual words in the text. SMER allows us to reliably determine which words or entities positively contribute to predicting impactful articles. Quantitative and qualitative evaluation is performed through five diverse experiments conducted on 50.000 research papers from the CORD-19 corpus. Through an AOPC curve analysis, we experimentally demonstrate that SMER produces better explanations than LIME for logistic regression.