 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured prompt interrogation and recursive extraction of semantics (SPIRES): A method for populating knowledge bases using zero-shot learning
Apr 05, 2023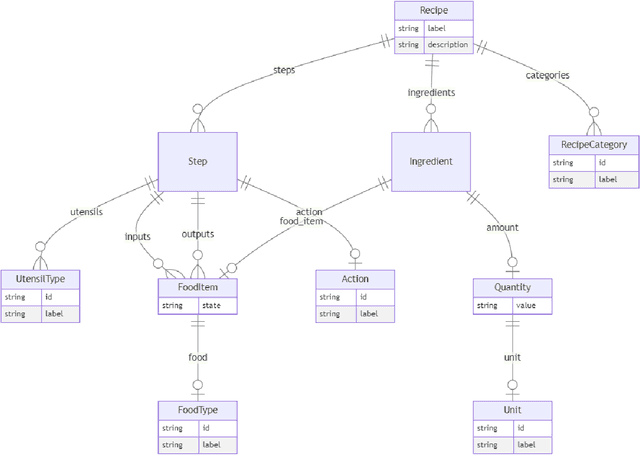
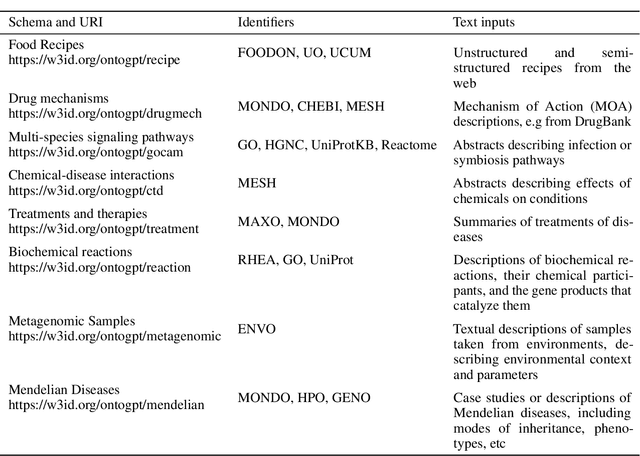
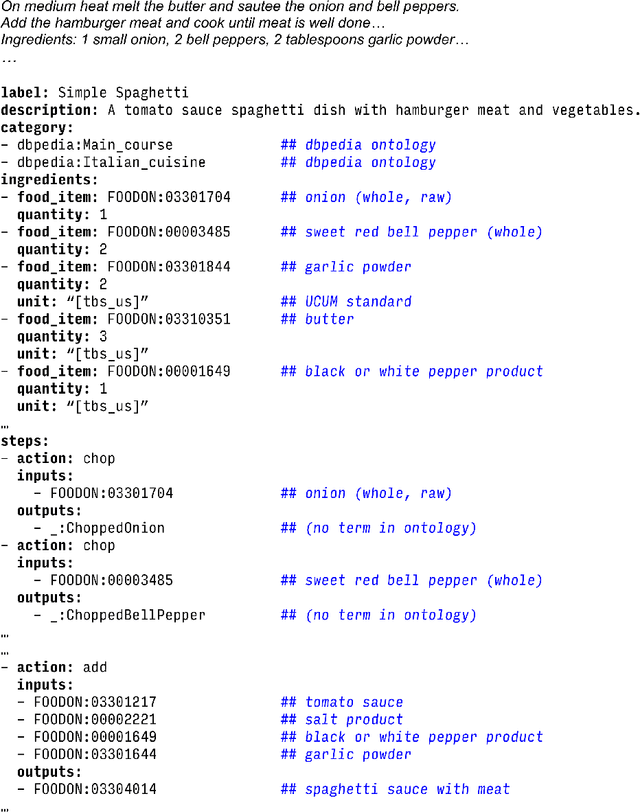

Creating knowledge bases and ontologies is a time consuming task that relies on a manual curation. AI/NLP approaches can assist expert curators in populating these knowledge bases, but current approaches rely on extensive training data, and are not able to populate arbitrary complex nested knowledge schemas. Here we present Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES), a Knowledge Extraction approach that relies on the ability of Large Language Models (LLMs) to perform zero-shot learning (ZSL) and general-purpose query answering from flexible prompts and return information conforming to a specified schema. Given a detailed, user-defined knowledge schema and an input text, SPIRES recursively performs prompt interrogation against GPT-3+ to obtain a set of responses matching the provided schema. SPIRES uses existing ontologies and vocabularies to provide identifiers for all matched elements. We present examples of use of SPIRES in different domains, including extraction of food recipes, multi-species cellular signaling pathways, disease treatments, multi-step drug mechanisms, and chemical to disease causation graphs. Current SPIRES accuracy is comparable to the mid-range of existing Relation Extraction (RE) methods, but has the advantage of easy customization, flexibility, and, crucially, the ability to perform new tasks in the absence of any training data. This method supports a general strategy of leveraging the language interpreting capabilities of LLMs to assemble knowledge bases, assisting manual knowledge curation and acquisition while supporting validation with publicly-available databases and ontologies external to the LLM. SPIRES is available as part of the open source OntoGPT package: https://github.com/ monarch-initiative/ontogpt.
Ontologizing Health Systems Data at Scale: Making Translational Discovery a Reality
Sep 10, 2022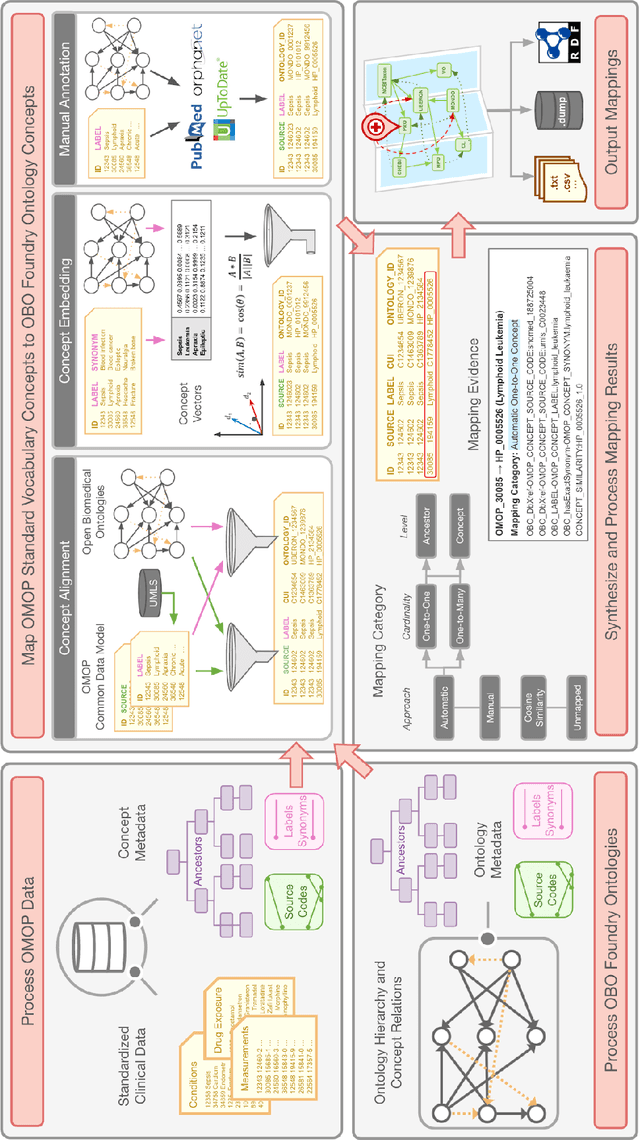
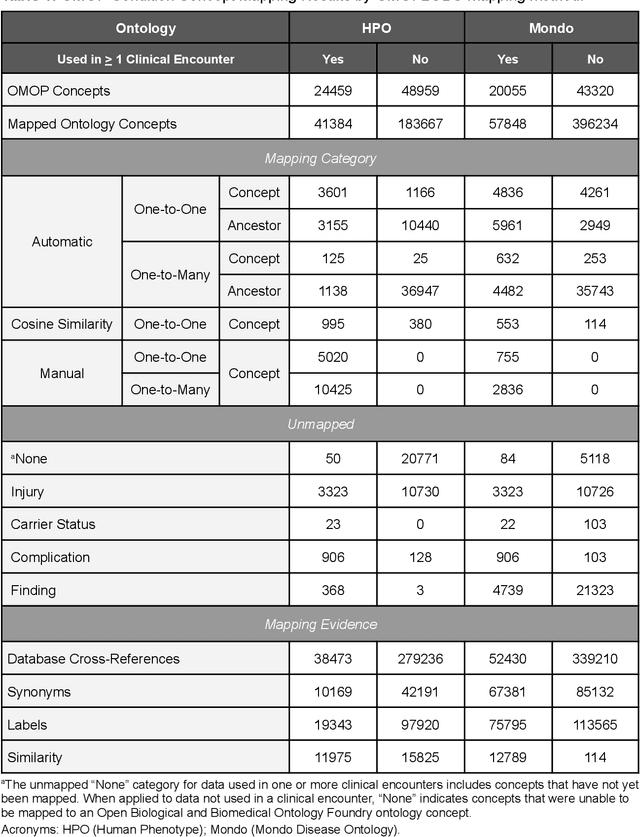
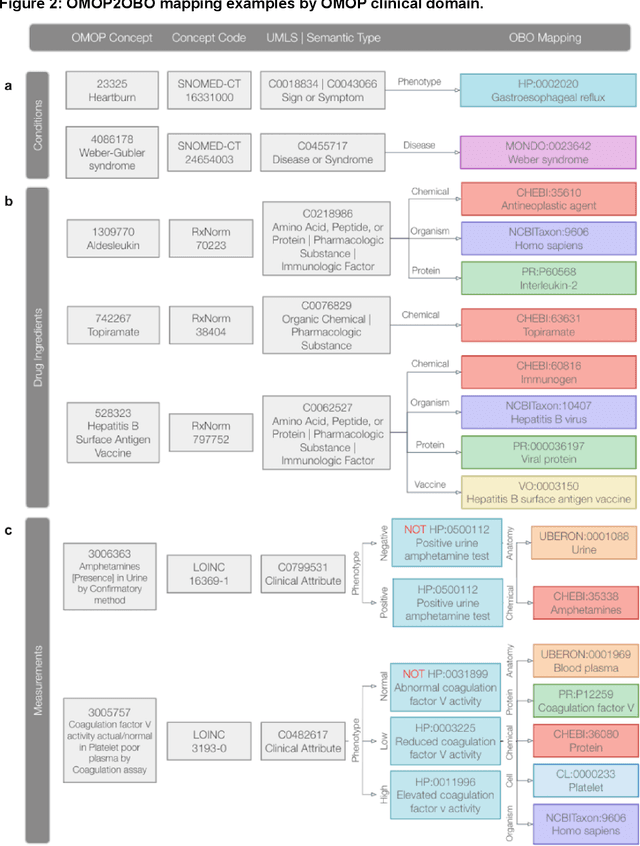
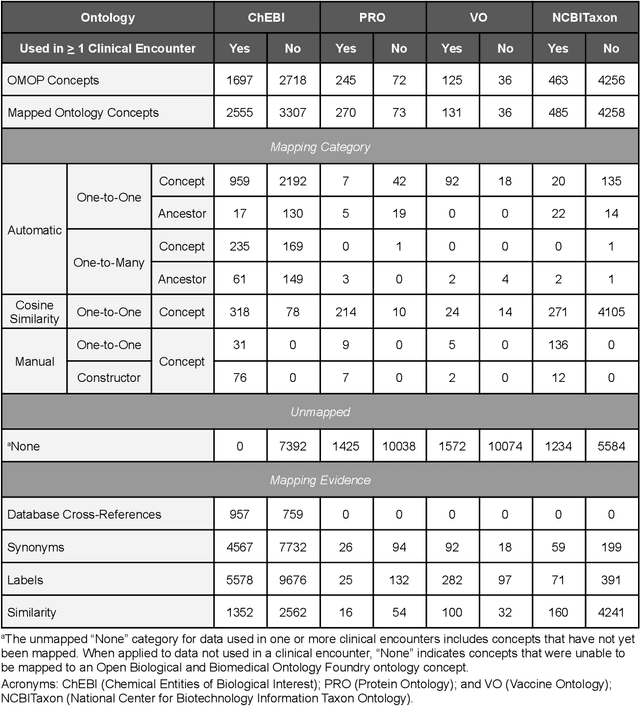
Common data models solve many challenges of standardizing electronic health record (EHR) data, but are unable to semantically integrate the resources needed for deep phenotyping. Open Biological and Biomedical Ontology (OBO) Foundry ontologies provide semantically computable representations of biological knowledge and enable the integration of a variety of biomedical data. However, mapping EHR data to OBO Foundry ontologies requires significant manual curation and domain expertise. We introduce a framework for mapping Observational Medical Outcomes Partnership (OMOP) standard vocabularies to OBO Foundry ontologies. Using this framework, we produced mappings for 92,367 conditions, 8,615 drug ingredients, and 10,673 measurement results. Mapping accuracy was verified by domain experts and when examined across 24 hospitals, the mappings covered 99% of conditions and drug ingredients and 68% of measurements. Finally, we demonstrate that OMOP2OBO mappings can aid in the systematic identification of undiagnosed rare disease patients who might benefit from genetic testing.
An Open Natural Language Processing Development Framework for EHR-based Clinical Research: A case demonstration using the National COVID Cohort Collaborative (N3C)
Oct 20, 2021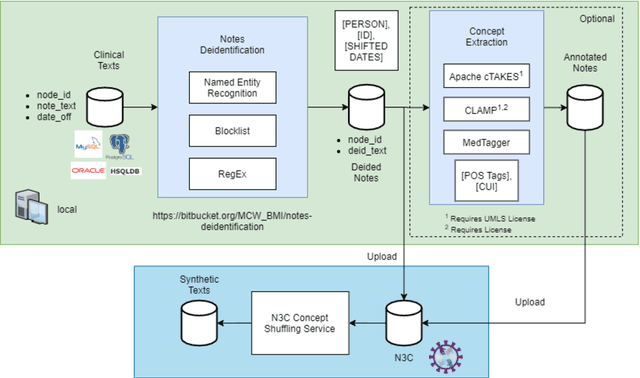

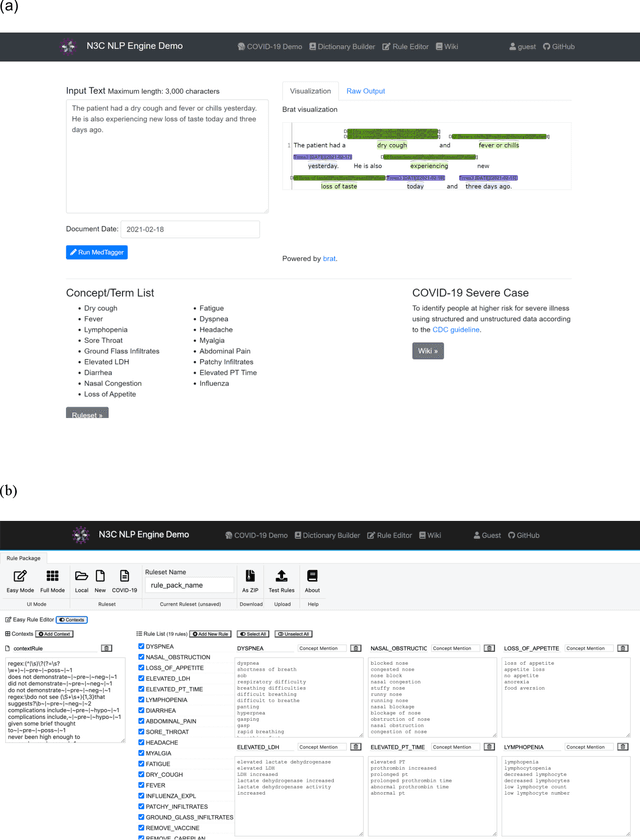
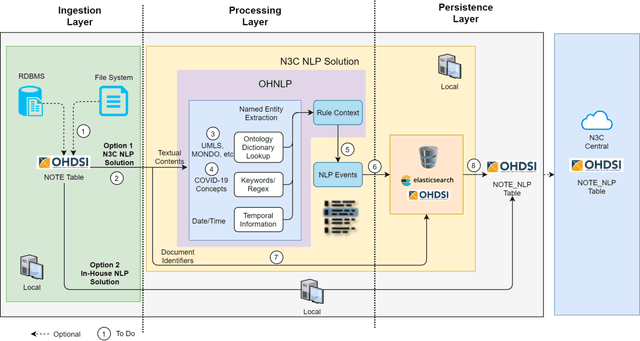
While we pay attention to the latest advances in clinical natural language processing (NLP), we can notice some resistance in the clinical and translational research community to adopt NLP models due to limited transparency, Interpretability and usability. Built upon our previous work, in this study, we proposed an open natural language processing development framework and evaluated it through the implementation of NLP algorithms for the National COVID Cohort Collaborative (N3C). Based on the interests in information extraction from COVID-19 related clinical notes, our work includes 1) an open data annotation process using COVID-19 signs and symptoms as the use case, 2) a community-driven ruleset composing platform, and 3) a synthetic text data generation workflow to generate texts for information extraction tasks without involving human subjects. The generated corpora derived out of the texts from multiple intuitions and gold standard annotation are tested on a single institution's rule set has the performances in F1 score of 0.876, 0.706 and 0.694, respectively. The study as a consortium effort of the N3C NLP subgroup demonstrates the feasibility of creating a federated NLP algorithm development and benchmarking platform to enhance multi-institution clinical NLP study.