 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurateGPT: A flexible language-model assisted biocuration tool
Oct 29, 2024



Effective data-driven biomedical discovery requires data curation: a time-consuming process of finding, organizing, distilling, integrating, interpreting, annotating, and validating diverse information into a structured form suitable for databases and knowledge bases. Accurate and efficient curation of these digital assets is critical to ensuring that they are FAIR, trustworthy, and sustainable. Unfortunately, expert curators face significant time and resource constraints. The rapid pace of new information being published daily is exceeding their capacity for curation. Generative AI, exemplified by instruction-tuned large language models (LLMs), has opened up new possibilities for assisting human-driven curation. The design philosophy of agents combines the emerging abilities of generative AI with more precise methods. A curator's tasks can be aided by agents for performing reasoning, searching ontologies, and integrating knowledge across external sources, all efforts otherwise requiring extensive manual effort. Our LLM-driven annotation tool, CurateGPT, melds the power of generative AI together with trusted knowledge bases and literature sources. CurateGPT streamlines the curation process, enhancing collaboration and efficiency in common workflows. Compared to direct interaction with an LLM, CurateGPT's agents enable access to information beyond that in the LLM's training data and they provide direct links to the data supporting each claim. This helps curators, researchers, and engineers scale up curation efforts to keep pace with the ever-increasing volume of scientific data.
Automated Annotation of Scientific Texts for ML-based Keyphrase Extraction and Validation
Nov 08, 2023Advanced omics technologies and facilities generate a wealth of valuable data daily; however, the data often lacks the essential metadata required for researchers to find and search them effectively. The lack of metadata poses a significant challenge in the utilization of these datasets. Machine learning-based metadata extraction techniques have emerged as a potentially viable approach to automatically annotating scientific datasets with the metadata necessary for enabling effective search. Text labeling, usually performed manually, plays a crucial role in validating machine-extracted metadata. However, manual labeling is time-consuming; thus, there is an need to develop automated text labeling techniques in order to accelerate the process of scientific innovation. This need is particularly urgent in fields such as environmental genomics and microbiome science, which have historically received less attention in terms of metadata curation and creation of gold-standard text mining datasets. In this paper, we present two novel automated text labeling approaches for the validation of ML-generated metadata for unlabeled texts, with specific applications in environmental genomics. Our techniques show the potential of two new ways to leverage existing information about the unlabeled texts and the scientific domain. The first technique exploits relationships between different types of data sources related to the same research study, such as publications and proposals. The second technique takes advantage of domain-specific controlled vocabularies or ontologies. In this paper, we detail applying these approaches for ML-generated metadata validation. Our results show that the proposed label assignment approaches can generate both generic and highly-specific text labels for the unlabeled texts, with up to 44% of the labels matching with those suggested by a ML keyword extraction algorithm.
Structured prompt interrogation and recursive extraction of semantics (SPIRES): A method for populating knowledge bases using zero-shot learning
Apr 05, 2023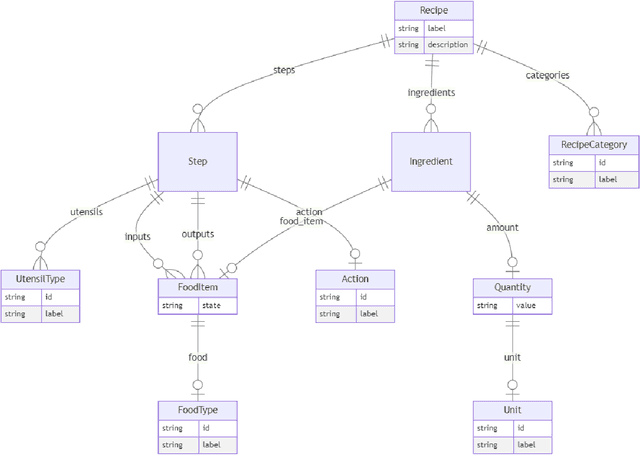
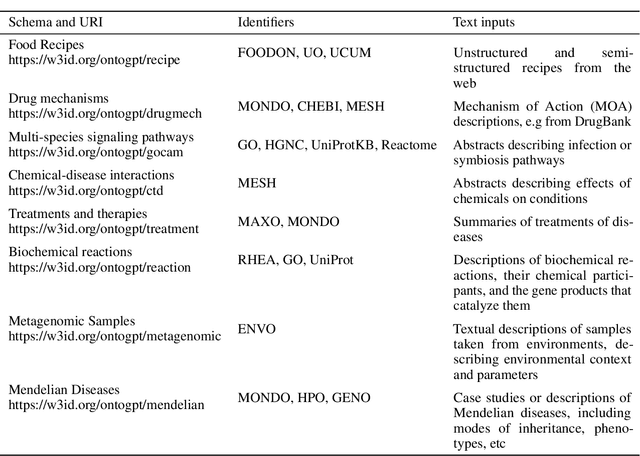
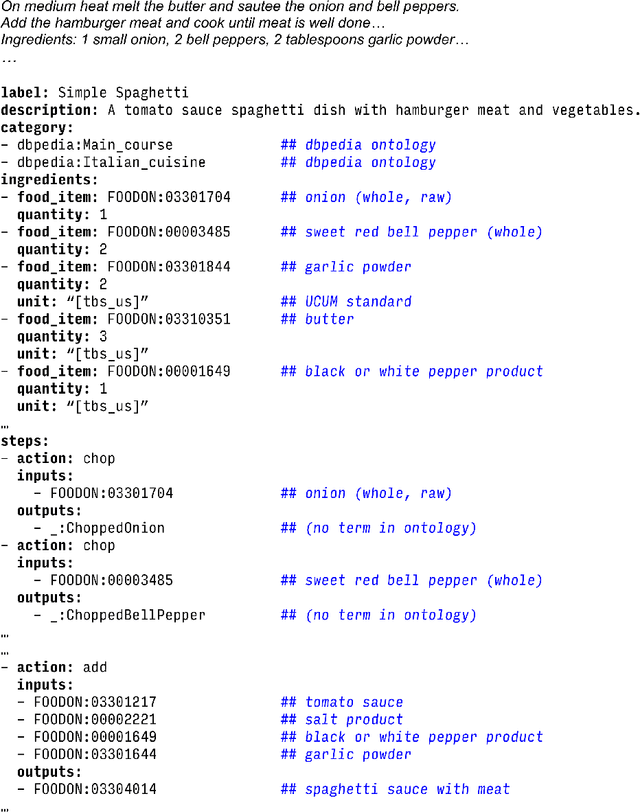

Creating knowledge bases and ontologies is a time consuming task that relies on a manual curation. AI/NLP approaches can assist expert curators in populating these knowledge bases, but current approaches rely on extensive training data, and are not able to populate arbitrary complex nested knowledge schemas. Here we present Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES), a Knowledge Extraction approach that relies on the ability of Large Language Models (LLMs) to perform zero-shot learning (ZSL) and general-purpose query answering from flexible prompts and return information conforming to a specified schema. Given a detailed, user-defined knowledge schema and an input text, SPIRES recursively performs prompt interrogation against GPT-3+ to obtain a set of responses matching the provided schema. SPIRES uses existing ontologies and vocabularies to provide identifiers for all matched elements. We present examples of use of SPIRES in different domains, including extraction of food recipes, multi-species cellular signaling pathways, disease treatments, multi-step drug mechanisms, and chemical to disease causation graphs. Current SPIRES accuracy is comparable to the mid-range of existing Relation Extraction (RE) methods, but has the advantage of easy customization, flexibility, and, crucially, the ability to perform new tasks in the absence of any training data. This method supports a general strategy of leveraging the language interpreting capabilities of LLMs to assemble knowledge bases, assisting manual knowledge curation and acquisition while supporting validation with publicly-available databases and ontologies external to the LLM. SPIRES is available as part of the open source OntoGPT package: https://github.com/ monarch-initiative/ontogpt.