 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntologizing Health Systems Data at Scale: Making Translational Discovery a Reality
Sep 10, 2022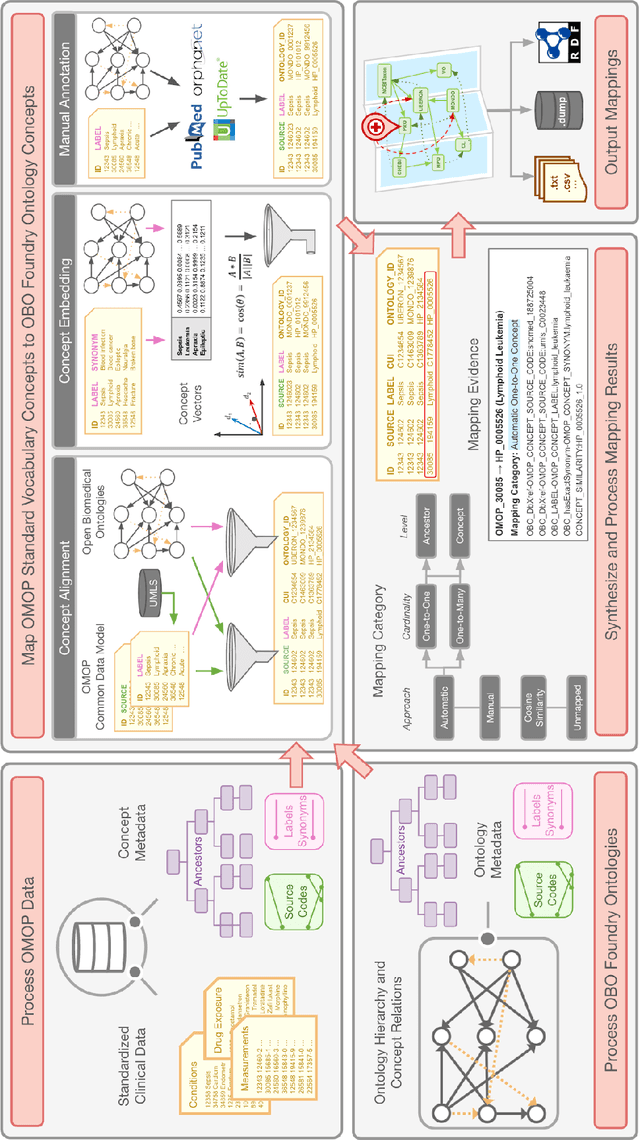
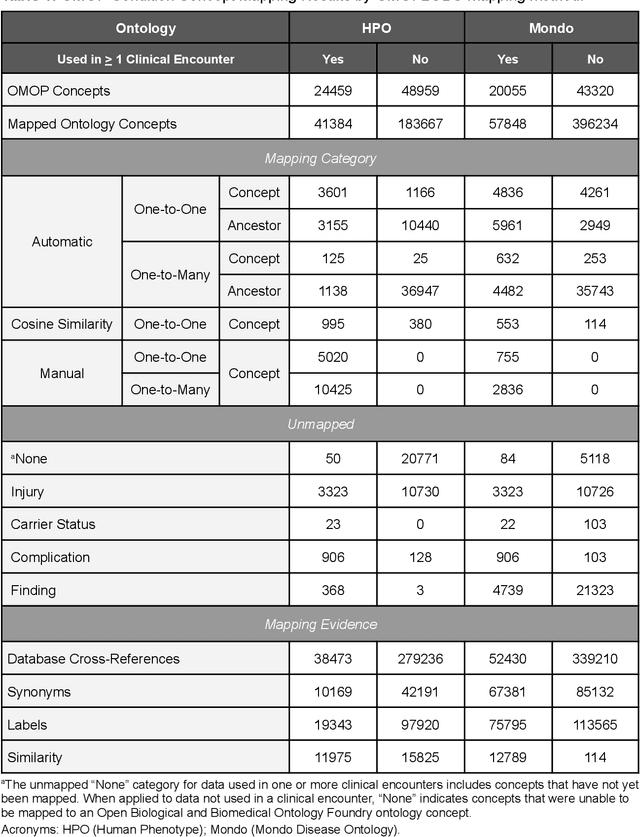
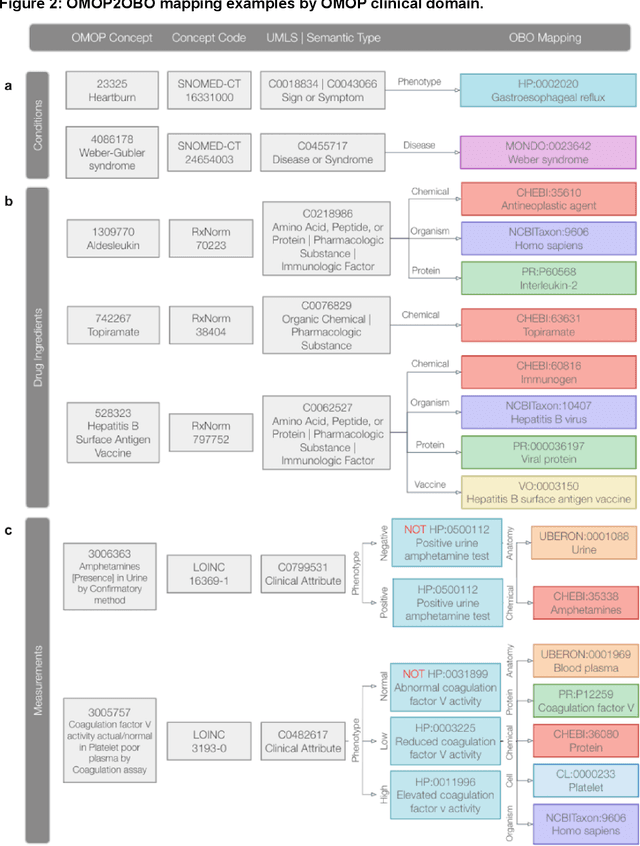
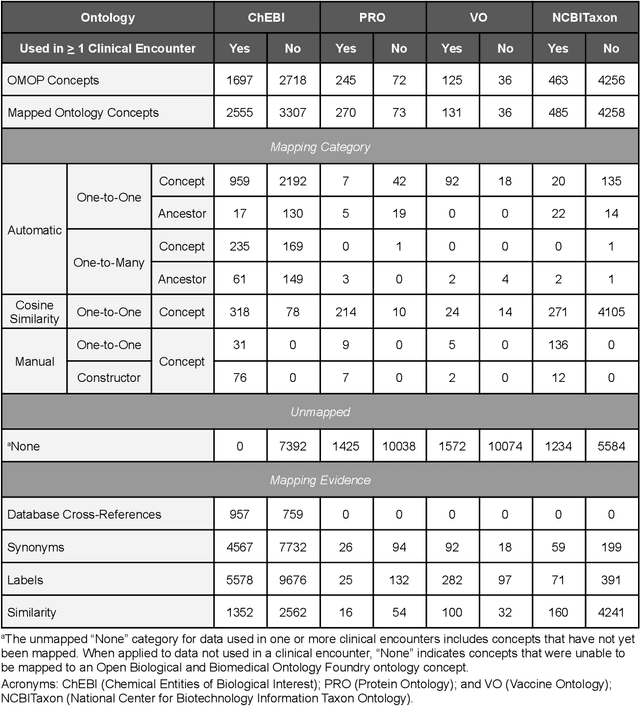
Common data models solve many challenges of standardizing electronic health record (EHR) data, but are unable to semantically integrate the resources needed for deep phenotyping. Open Biological and Biomedical Ontology (OBO) Foundry ontologies provide semantically computable representations of biological knowledge and enable the integration of a variety of biomedical data. However, mapping EHR data to OBO Foundry ontologies requires significant manual curation and domain expertise. We introduce a framework for mapping Observational Medical Outcomes Partnership (OMOP) standard vocabularies to OBO Foundry ontologies. Using this framework, we produced mappings for 92,367 conditions, 8,615 drug ingredients, and 10,673 measurement results. Mapping accuracy was verified by domain experts and when examined across 24 hospitals, the mappings covered 99% of conditions and drug ingredients and 68% of measurements. Finally, we demonstrate that OMOP2OBO mappings can aid in the systematic identification of undiagnosed rare disease patients who might benefit from genetic testing.
Knowledge-Driven Mechanistic Enrichment of the Preeclampsia Ignorome
Jul 28, 2022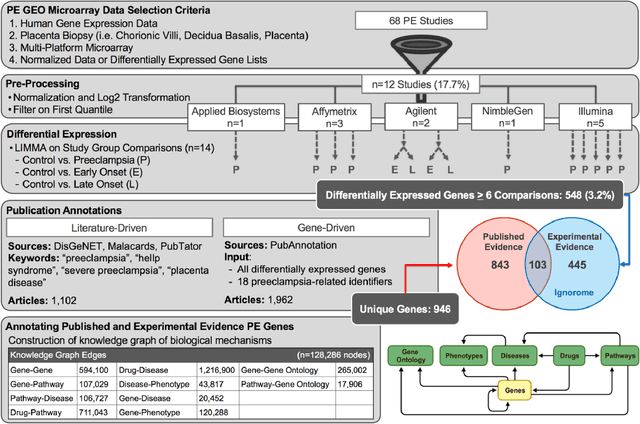
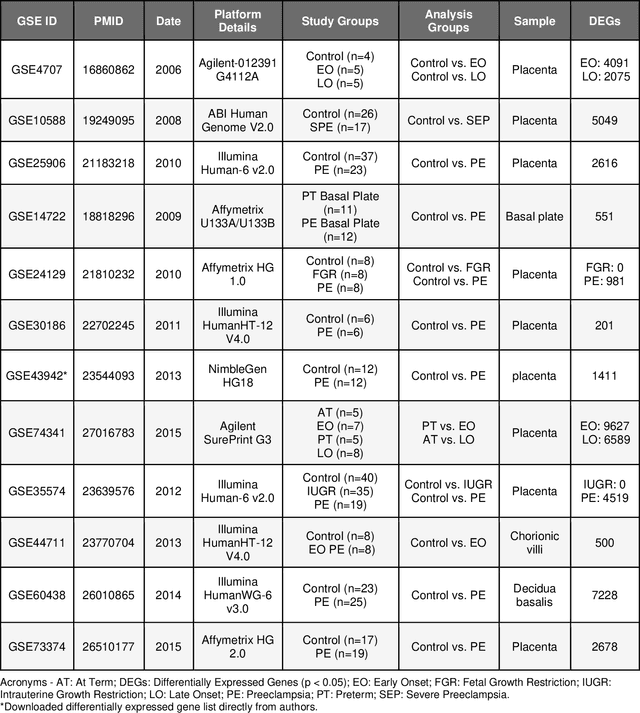
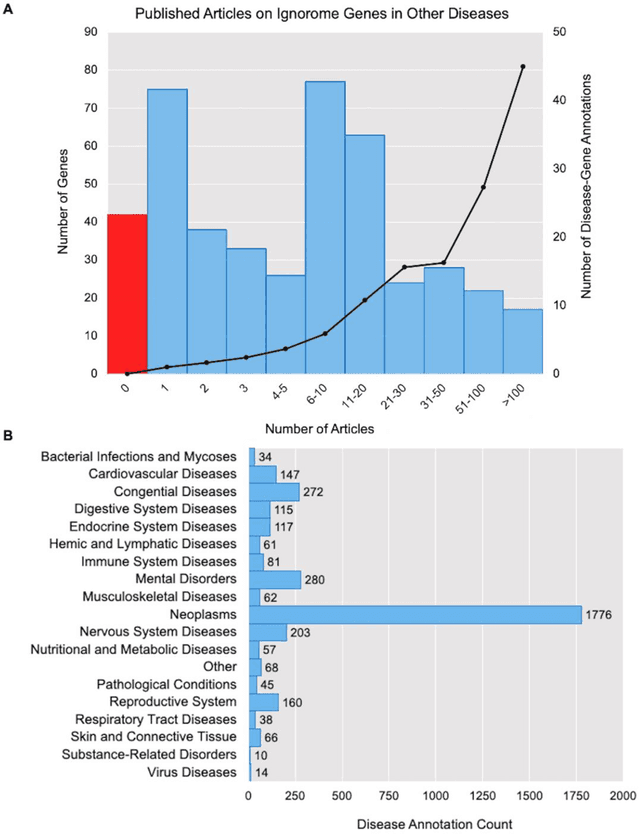
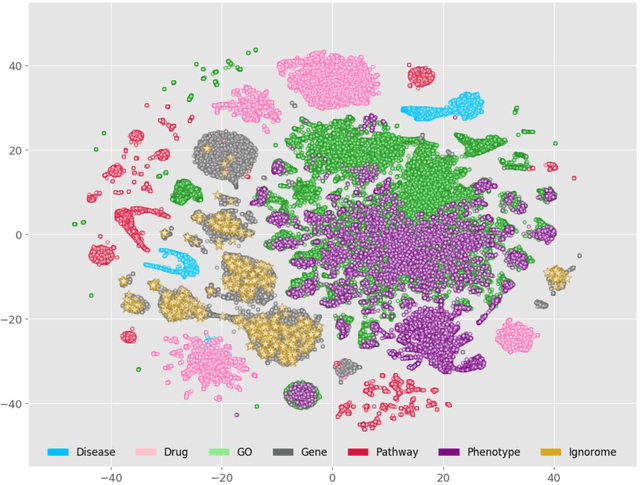
Preeclampsia is a leading cause of maternal and fetal morbidity and mortality. Currently, the only definitive treatment of preeclampsia is delivery of the placenta, which is central to the pathogenesis of the disease. Transcriptional profiling of human placenta from pregnancies complicated by preeclampsia has been extensively performed to identify differentially expressed genes (DEGs). DEGs are identified using unbiased assays, however, the decisions to investigate DEGs experimentally are biased by many factors, causing many DEGs to remain uninvestigated. A set of DEGs which are associated with a disease experimentally, but which have no known association with the disease in the literature is known as the ignorome. Preeclampsia has an extensive body of scientific literature, a large pool of DEG data, and only one definitive treatment. Tools facilitating knowledge-based analyses, which are capable of combining disparate data from many sources in order to suggest underlying mechanisms of action, may be a valuable resource to support discovery and improve our understanding of this disease. In this work we demonstrate how a biomedical knowledge graph (KG) can be used to identify novel preeclampsia molecular mechanisms. Existing open source biomedical resources and publicly available high-throughput transcriptional profiling data were used to identify and annotate the function of currently uninvestigated preeclampsia-associated DEGs. Experimentally investigated genes associated with preeclampsia were identified from PubMed abstracts using text-mining methodologies. The relative complement of the text-mined- and meta-analysis-derived lists were identified as the uninvestigated preeclampsia-associated DEGs (n=445), i.e., the preeclampsia ignorome. Using the KG to investigate relevant DEGs revealed 53 novel clinically relevant and biologically actionable mechanistic associations.