 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Drug Overdose Prediction from Longitudinal Medical Records
Apr 16, 2025The ability to predict drug overdose risk from a patient's medical records is crucial for timely intervention and prevention. Traditional machine learning models have shown promise in analyzing longitudinal medical records for this task. However, recent advancements in large language models (LLMs) offer an opportunity to enhance prediction performance by leveraging their ability to process long textual data and their inherent prior knowledge across diverse tasks. In this study, we assess the effectiveness of Open AI's GPT-4o LLM in predicting drug overdose events using patients' longitudinal insurance claims records. We evaluate its performance in both fine-tuned and zero-shot settings, comparing them to strong traditional machine learning methods as baselines. Our results show that LLMs not only outperform traditional models in certain settings but can also predict overdose risk in a zero-shot setting without task-specific training. These findings highlight the potential of LLMs in clinical decision support, particularly for drug overdose risk prediction.
Forecasting Opioid Incidents for Rapid Actionable Data for Opioid Response in Kentucky
Oct 21, 2024We present efforts in the fields of machine learning and time series forecasting to accurately predict counts of future opioid overdose incidents recorded by Emergency Medical Services (EMS) in the state of Kentucky. Forecasts are useful to state government agencies to properly prepare and distribute resources related to opioid overdoses effectively. Our approach uses county and district level aggregations of EMS opioid overdose encounters and forecasts future counts for each month. A variety of additional covariates were tested to determine their impact on the model's performance. Models with different levels of complexity were evaluated to optimize training time and accuracy. Our results show that when special precautions are taken to address data sparsity, useful predictions can be generated with limited error by utilizing yearly trends and covariance with additional data sources.
An Open Natural Language Processing Development Framework for EHR-based Clinical Research: A case demonstration using the National COVID Cohort Collaborative (N3C)
Oct 20, 2021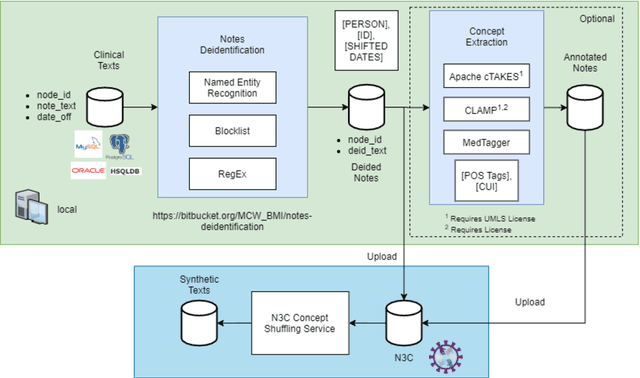

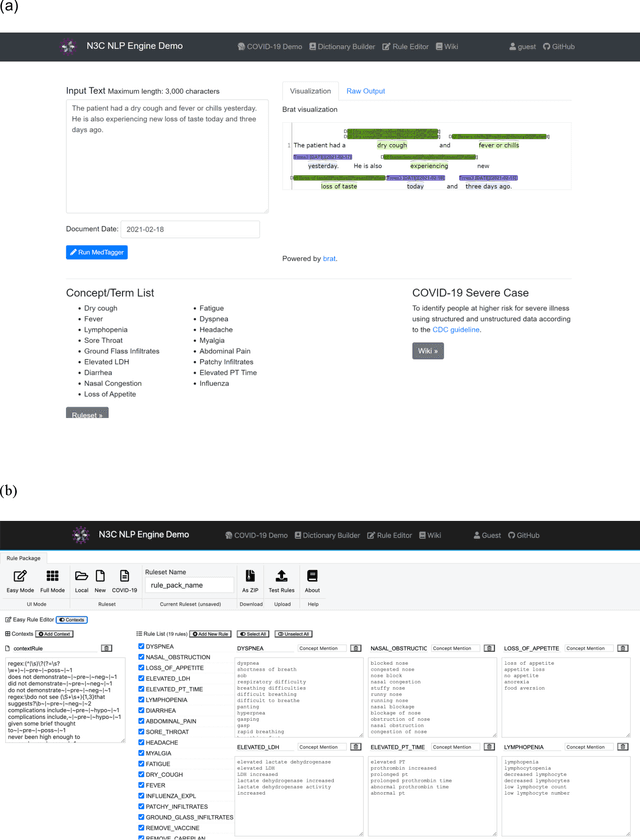
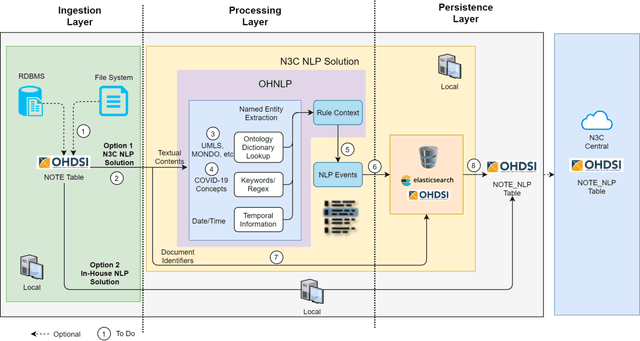
While we pay attention to the latest advances in clinical natural language processing (NLP), we can notice some resistance in the clinical and translational research community to adopt NLP models due to limited transparency, Interpretability and usability. Built upon our previous work, in this study, we proposed an open natural language processing development framework and evaluated it through the implementation of NLP algorithms for the National COVID Cohort Collaborative (N3C). Based on the interests in information extraction from COVID-19 related clinical notes, our work includes 1) an open data annotation process using COVID-19 signs and symptoms as the use case, 2) a community-driven ruleset composing platform, and 3) a synthetic text data generation workflow to generate texts for information extraction tasks without involving human subjects. The generated corpora derived out of the texts from multiple intuitions and gold standard annotation are tested on a single institution's rule set has the performances in F1 score of 0.876, 0.706 and 0.694, respectively. The study as a consortium effort of the N3C NLP subgroup demonstrates the feasibility of creating a federated NLP algorithm development and benchmarking platform to enhance multi-institution clinical NLP study.