 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open-Source Knowledge Graph Ecosystem for the Life Sciences
Jul 11, 2023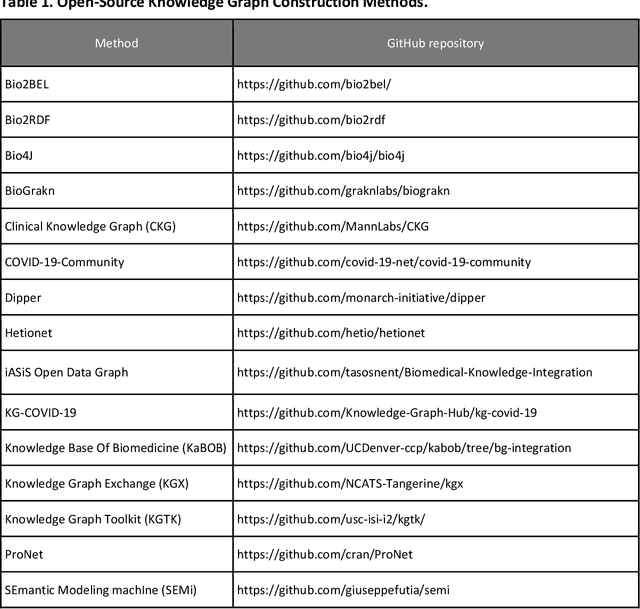
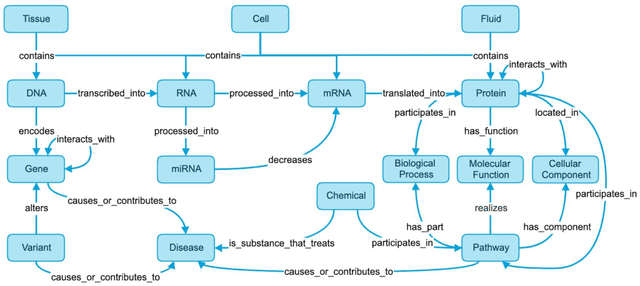
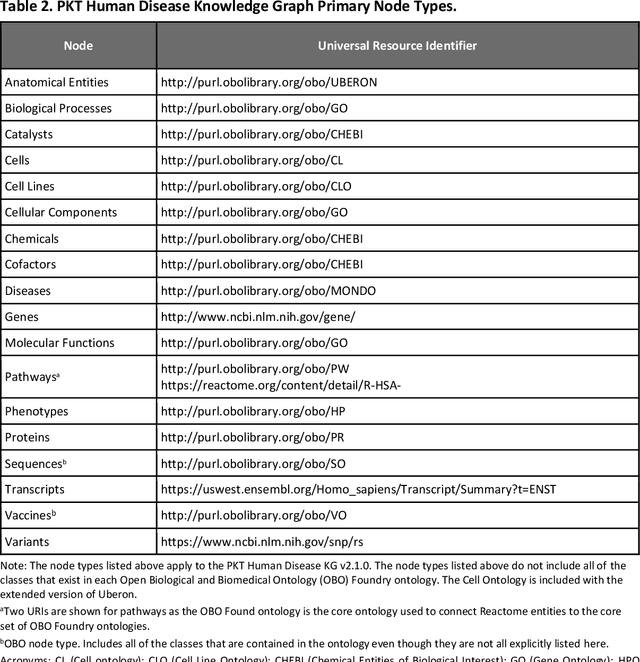
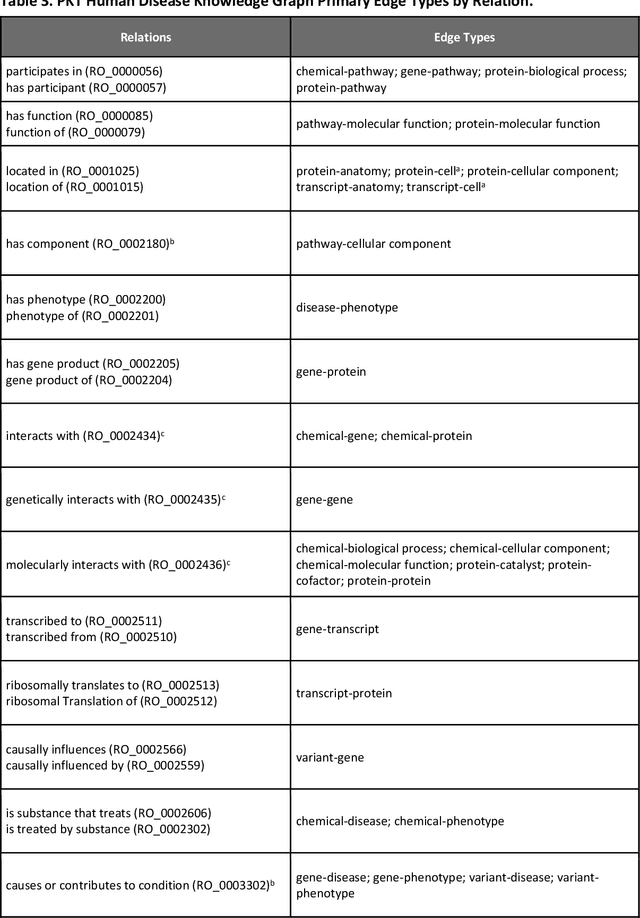
Translational research requires data at multiple scales of biological organization. Advancements in sequencing and multi-omics technologies have increased the availability of these data but researchers face significant integration challenges. Knowledge graphs (KGs) are used to model complex phenomena, and methods exist to automatically construct them. However, tackling complex biomedical integration problems requires flexibility in the way knowledge is modeled. Moreover, existing KG construction methods provide robust tooling at the cost of fixed or limited choices among knowledge representation models. PheKnowLator (Phenotype Knowledge Translator) is a semantic ecosystem for automating the FAIR (Findable, Accessible, Interoperable, and Reusable) construction of ontologically grounded KGs with fully customizable knowledge representation. The ecosystem includes KG construction resources (e.g., data preparation APIs), analysis tools (e.g., SPARQL endpoints and abstraction algorithms), and benchmarks (e.g., prebuilt KGs and embeddings). We evaluate the ecosystem by surveying open-source KG construction methods and analyzing its computational performance when constructing 12 large-scale KGs. With flexible knowledge representation, PheKnowLator enables fully customizable KGs without compromising performance or usability.
GraPE: fast and scalable Graph Processing and Embedding
Oct 12, 2021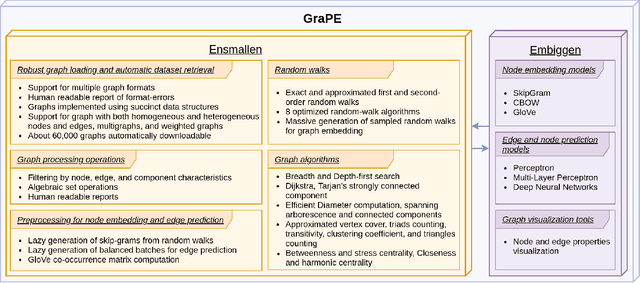
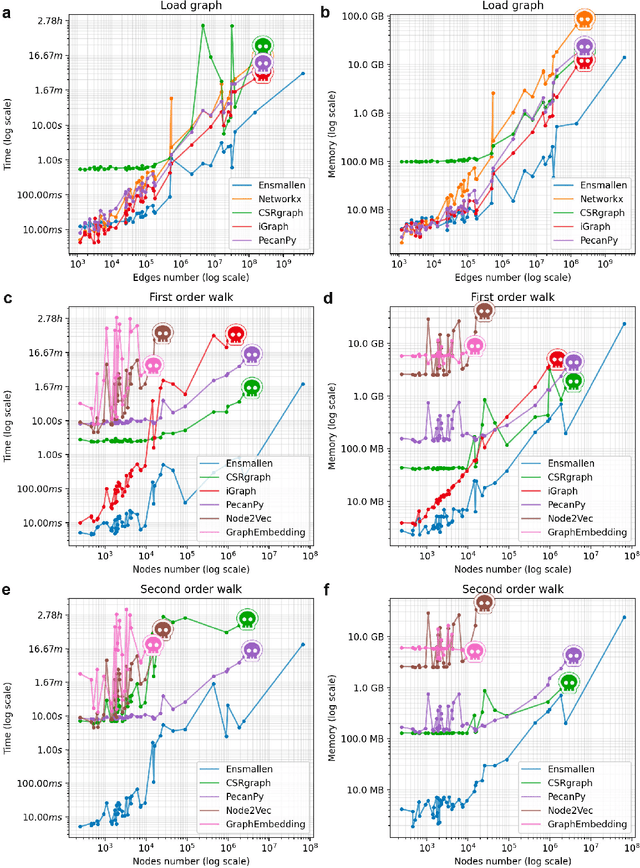
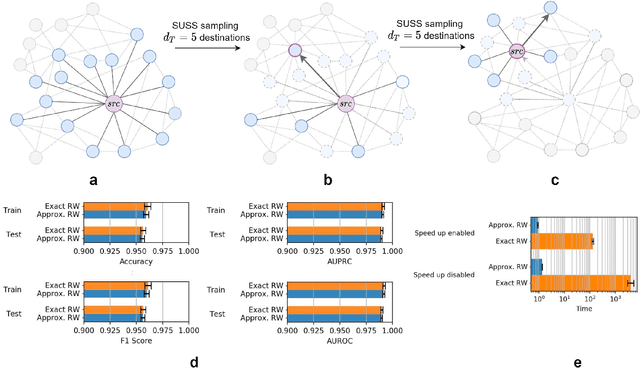
Graph Representation Learning methods have enabled a wide range of learning problems to be addressed for data that can be represented in graph form. Nevertheless, several real world problems in economy, biology, medicine and other fields raised relevant scaling problems with existing methods and their software implementation, due to the size of real world graphs characterized by millions of nodes and billions of edges. We present GraPE, a software resource for graph processing and random walk based embedding, that can scale with large and high-degree graphs and significantly speed up-computation. GraPE comprises specialized data structures, algorithms, and a fast parallel implementation that displays everal orders of magnitude improvement in empirical space and time complexity compared to state of the art software resources, with a corresponding boost in the performance of machine learning methods for edge and node label prediction and for the unsupervised analysis of graphs.GraPE is designed to run on laptop and desktop computers, as well as on high performance computing clusters
Het-node2vec: second order random walk sampling for heterogeneous multigraphs embedding
Jan 05, 2021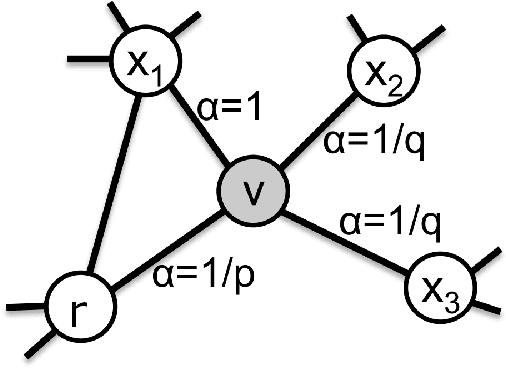
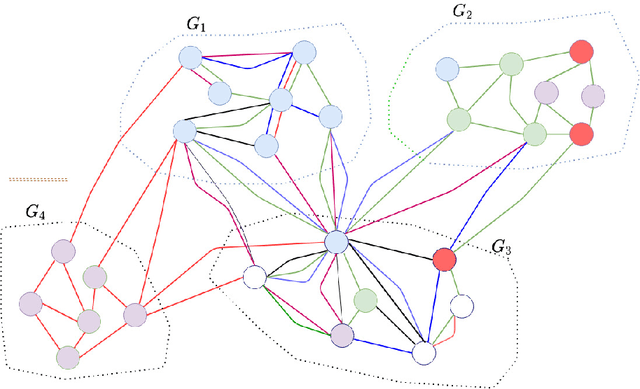
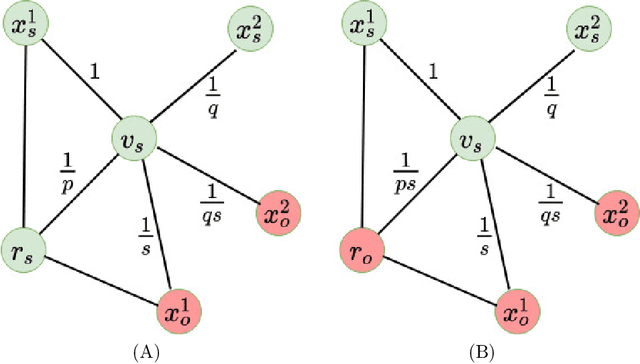

We introduce a set of algorithms (Het-node2vec) that extend the original node2vec node-neighborhood sampling method to heterogeneous multigraphs, i.e. networks characterized by multiple types of nodes and edges. The resulting random walk samples capture both the structural characteristics of the graph and the semantics of the different types of nodes and edges. The proposed algorithms can focus their attention on specific node or edge types, allowing accurate representations also for underrepresented types of nodes/edges that are of interest for the prediction problem under investigation. These rich and well-focused representations can boost unsupervised and supervised learning on heterogeneous graphs.