 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraPE: fast and scalable Graph Processing and Embedding
Oct 12, 2021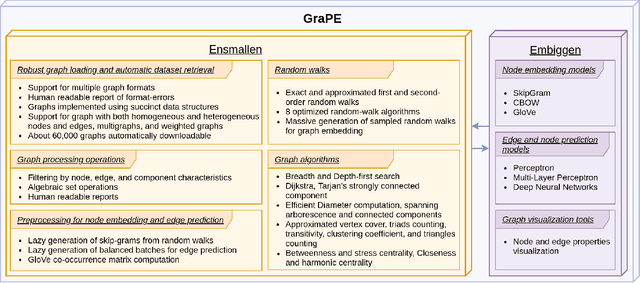
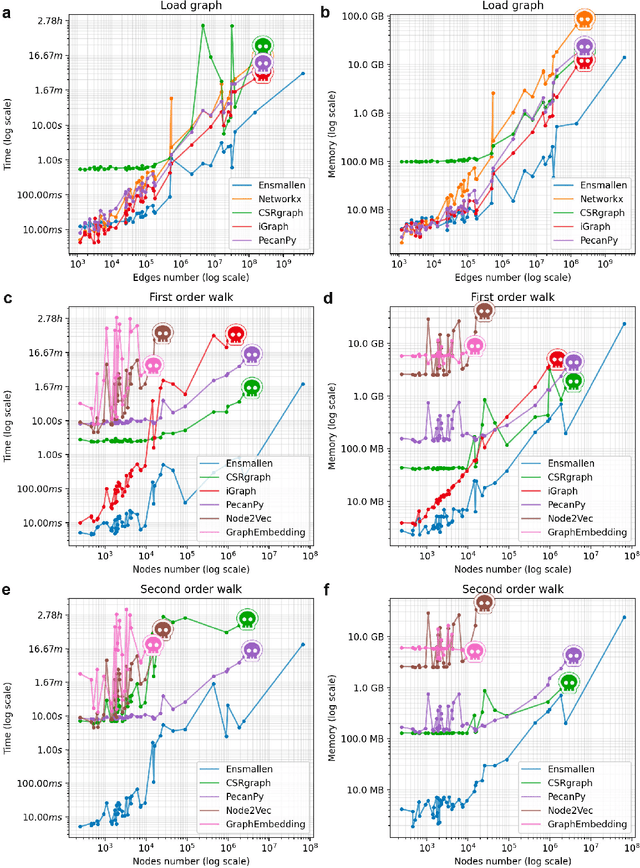
Graph Representation Learning methods have enabled a wide range of learning problems to be addressed for data that can be represented in graph form. Nevertheless, several real world problems in economy, biology, medicine and other fields raised relevant scaling problems with existing methods and their software implementation, due to the size of real world graphs characterized by millions of nodes and billions of edges. We present GraPE, a software resource for graph processing and random walk based embedding, that can scale with large and high-degree graphs and significantly speed up-computation. GraPE comprises specialized data structures, algorithms, and a fast parallel implementation that displays everal orders of magnitude improvement in empirical space and time complexity compared to state of the art software resources, with a corresponding boost in the performance of machine learning methods for edge and node label prediction and for the unsupervised analysis of graphs.GraPE is designed to run on laptop and desktop computers, as well as on high performance computing clusters
Het-node2vec: second order random walk sampling for heterogeneous multigraphs embedding
Jan 05, 2021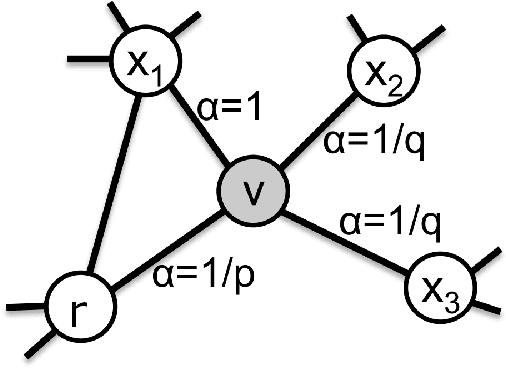
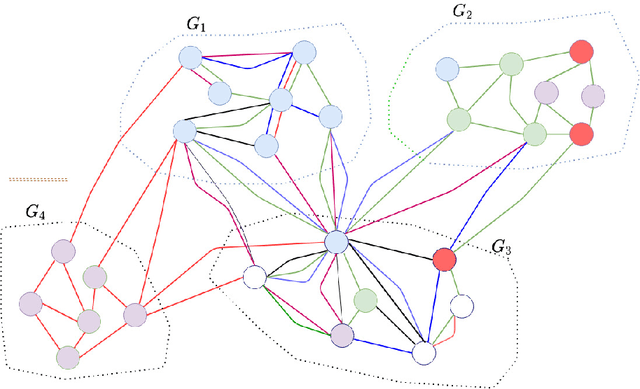
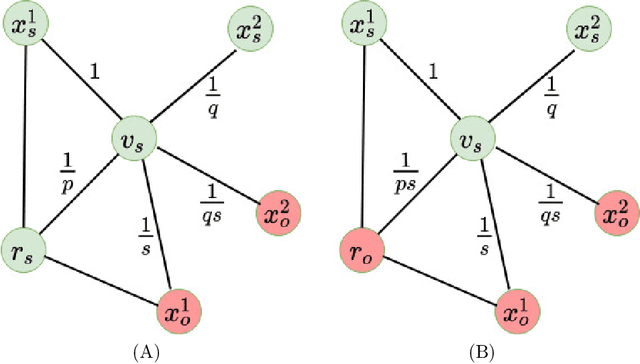

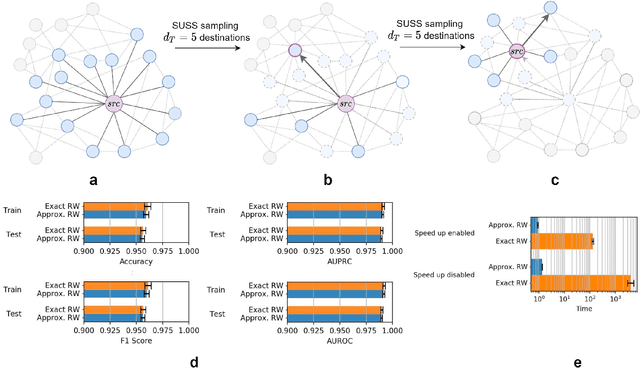
We introduce a set of algorithms (Het-node2vec) that extend the original node2vec node-neighborhood sampling method to heterogeneous multigraphs, i.e. networks characterized by multiple types of nodes and edges. The resulting random walk samples capture both the structural characteristics of the graph and the semantics of the different types of nodes and edges. The proposed algorithms can focus their attention on specific node or edge types, allowing accurate representations also for underrepresented types of nodes/edges that are of interest for the prediction problem under investigation. These rich and well-focused representations can boost unsupervised and supervised learning on heterogeneous graphs.