 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeDecider: An LLM-Based Framework for Federated Cross-Domain Recommendation
Feb 17, 2026Federated cross-domain recommendation (Federated CDR) aims to collaboratively learn personalized recommendation models across heterogeneous domains while preserving data privacy. Recently, large language model (LLM)-based recommendation models have demonstrated impressive performance by leveraging LLMs' strong reasoning capabilities and broad knowledge. However, adopting LLM-based recommendation models in Federated CDR scenarios introduces new challenges. First, there exists a risk of overfitting with domain-specific local adapters. The magnitudes of locally optimized parameter updates often vary across domains, causing biased aggregation and overfitting toward domain-specific distributions. Second, unlike traditional recommendation models (e.g., collaborative filtering, bipartite graph-based methods) that learn explicit and comparable user/item representations, LLMs encode knowledge implicitly through autoregressive text generation training. This poses additional challenges for effectively measuring the cross-domain similarities under heterogeneity. To address these challenges, we propose an LLM-based framework for federated cross-domain recommendation, FeDecider. Specifically, FeDecider tackles the challenge of scale-specific noise by disentangling each client's low-rank updates and sharing only their directional components. To handle the need for flexible and effective integration, each client further learns personalized weights that achieve the data-aware integration of updates from other domains. Extensive experiments across diverse datasets validate the effectiveness of our proposed FeDecider.
GTR: Graph-Table-RAG for Cross-Table Question Answering
Apr 03, 2025Beyond pure text, a substantial amount of knowledge is stored in tables. In real-world scenarios, user questions often require retrieving answers that are distributed across multiple tables. GraphRAG has recently attracted much attention for enhancing LLMs' reasoning capabilities by organizing external knowledge to address ad-hoc and complex questions, exemplifying a promising direction for cross-table question answering. In this paper, to address the current gap in available data, we first introduce a multi-table benchmark, MutliTableQA, comprising 60k tables and 25k user queries collected from real-world sources. Then, we propose the first Graph-Table-RAG framework, namely GTR, which reorganizes table corpora into a heterogeneous graph, employs a hierarchical coarse-to-fine retrieval process to extract the most relevant tables, and integrates graph-aware prompting for downstream LLMs' tabular reasoning. Extensive experiments show that GTR exhibits superior cross-table question-answering performance while maintaining high deployment efficiency, demonstrating its real-world practical applicability.
PyG-SSL: A Graph Self-Supervised Learning Toolkit
Dec 30, 2024



Graph Self-Supervised Learning (SSL) has emerged as a pivotal area of research in recent years. By engaging in pretext tasks to learn the intricate topological structures and properties of graphs using unlabeled data, these graph SSL models achieve enhanced performance, improved generalization, and heightened robustness. Despite the remarkable achievements of these graph SSL methods, their current implementation poses significant challenges for beginners and practitioners due to the complex nature of graph structures, inconsistent evaluation metrics, and concerns regarding reproducibility hinder further progress in this field. Recognizing the growing interest within the research community, there is an urgent need for a comprehensive, beginner-friendly, and accessible toolkit consisting of the most representative graph SSL algorithms. To address these challenges, we present a Graph SSL toolkit named PyG-SSL, which is built upon PyTorch and is compatible with various deep learning and scientific computing backends. Within the toolkit, we offer a unified framework encompassing dataset loading, hyper-parameter configuration, model training, and comprehensive performance evaluation for diverse downstream tasks. Moreover, we provide beginner-friendly tutorials and the best hyper-parameters of each graph SSL algorithm on different graph datasets, facilitating the reproduction of results. The GitHub repository of the library is https://github.com/iDEA-iSAIL-Lab-UIUC/pyg-ssl.
Co-clustering for Federated Recommender System
Nov 03, 2024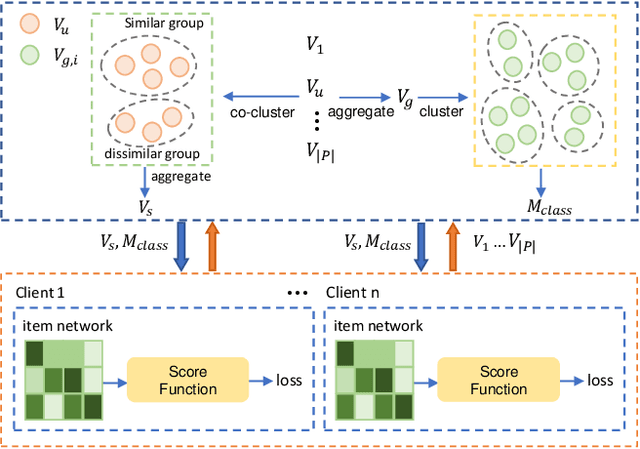
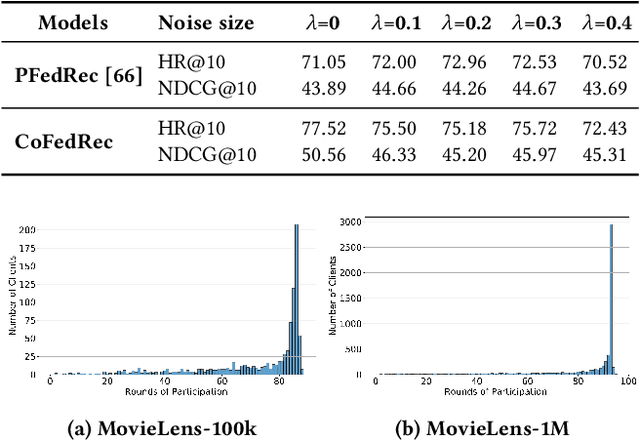
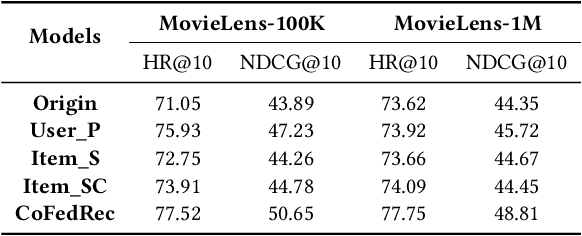
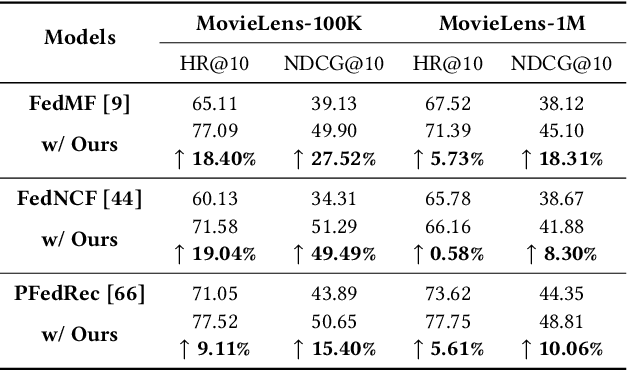
As data privacy and security attract increasing attention, Federated Recommender System (FRS) offers a solution that strikes a balance between providing high-quality recommendations and preserving user privacy. However, the presence of statistical heterogeneity in FRS, commonly observed due to personalized decision-making patterns, can pose challenges. To address this issue and maximize the benefit of collaborative filtering (CF) in FRS, it is intuitive to consider clustering clients (users) as well as items into different groups and learning group-specific models. Existing methods either resort to client clustering via user representations-risking privacy leakage, or employ classical clustering strategies on item embeddings or gradients, which we found are plagued by the curse of dimensionality. In this paper, we delve into the inefficiencies of the K-Means method in client grouping, attributing failures due to the high dimensionality as well as data sparsity occurring in FRS, and propose CoFedRec, a novel Co-clustering Federated Recommendation mechanism, to address clients heterogeneity and enhance the collaborative filtering within the federated framework. Specifically, the server initially formulates an item membership from the client-provided item networks. Subsequently, clients are grouped regarding a specific item category picked from the item membership during each communication round, resulting in an intelligently aggregated group model. Meanwhile, to comprehensively capture the global inter-relationships among items, we incorporate an additional supervised contrastive learning term based on the server-side generated item membership into the local training phase for each client. Extensive experiments on four datasets are provided, which verify the effectiveness of the proposed CoFedRec.
LLM-Forest for Health Tabular Data Imputation
Oct 28, 2024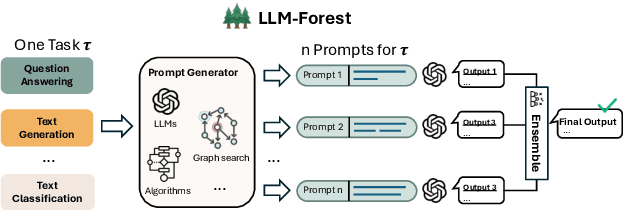
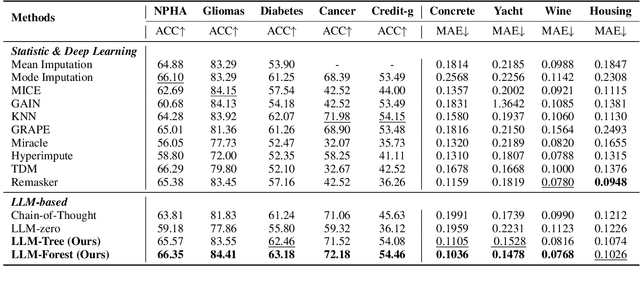
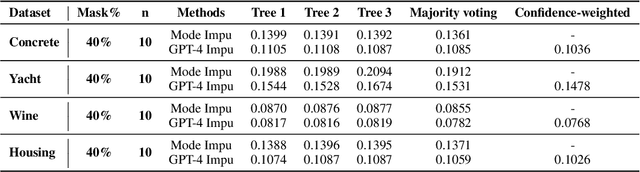
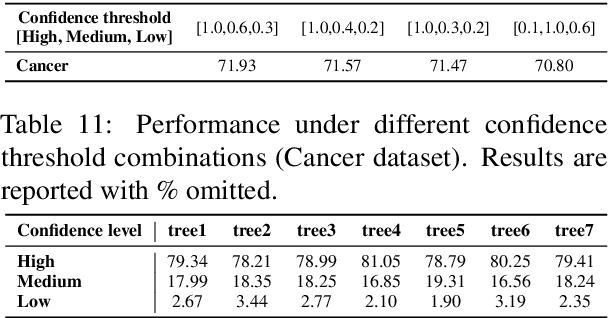
Missing data imputation is a critical challenge in tabular datasets, especially in healthcare, where data completeness is vital for accurate analysis. Large language models (LLMs), trained on vast corpora, have shown strong potential in data generation, making them a promising tool for tabular data imputation. However, challenges persist in designing effective prompts for a finetuning-free process and in mitigating the risk of LLM hallucinations. To address these issues, we propose a novel framework, LLM-Forest, which introduces a "forest" of few-shot learning LLM "trees" with confidence-based weighted voting. This framework is established on a new concept of bipartite information graphs to identify high-quality relevant neighboring entries with both feature and value granularity. Extensive experiments on four real-world healthcare datasets demonstrate the effectiveness and efficiency of LLM-Forest.
Robust Basket Recommendation via Noise-tolerated Graph Contrastive Learning
Dec 01, 2023The growth of e-commerce has seen a surge in popularity of platforms like Amazon, eBay, and Taobao. This has given rise to a unique shopping behavior involving baskets - sets of items purchased together. As a less studied interaction mode in the community, the question of how should shopping basket complement personalized recommendation systems remains under-explored. While previous attempts focused on jointly modeling user purchases and baskets, the distinct semantic nature of these elements can introduce noise when directly integrated. This noise negatively impacts the model's performance, further exacerbated by significant noise (e.g., a user is misled to click an item or recognizes it as uninteresting after consuming it) within both user and basket behaviors. In order to cope with the above difficulties, we propose a novel Basket recommendation framework via Noise-tolerated Contrastive Learning, named BNCL, to handle the noise existing in the cross-behavior integration and within-behavior modeling. First, we represent the basket-item interactions as the hypergraph to model the complex basket behavior, where all items appearing in the same basket are treated as a single hyperedge. Second, cross-behavior contrastive learning is designed to suppress the noise during the fusion of diverse behaviors. Next, to further inhibit the within-behavior noise of the user and basket interactions, we propose to exploit invariant properties of the recommenders w.r.t augmentations through within-behavior contrastive learning. A novel consistency-aware augmentation approach is further designed to better identify noisy interactions with the consideration of the above two types of interactions. Our framework BNCL offers a generic training paradigm that is applicable to different backbones. Extensive experiments on three shopping transaction datasets verify the effectiveness of our proposed method.
* CIKM 2023