 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialz: A Python Toolkit for Steering Vectors
May 04, 2025We introduce Dialz, a framework for advancing research on steering vectors for open-source LLMs, implemented in Python. Steering vectors allow users to modify activations at inference time to amplify or weaken a 'concept', e.g. honesty or positivity, providing a more powerful alternative to prompting or fine-tuning. Dialz supports a diverse set of tasks, including creating contrastive pair datasets, computing and applying steering vectors, and visualizations. Unlike existing libraries, Dialz emphasizes modularity and usability, enabling both rapid prototyping and in-depth analysis. We demonstrate how Dialz can be used to reduce harmful outputs such as stereotypes, while also providing insights into model behaviour across different layers. We release Dialz with full documentation, tutorials, and support for popular open-source models to encourage further research in safe and controllable language generation. Dialz enables faster research cycles and facilitates insights into model interpretability, paving the way for safer, more transparent, and more reliable AI systems.
Shifting Perspectives: Steering Vector Ensembles for Robust Bias Mitigation in LLMs
Mar 07, 2025We present a novel approach to bias mitigation in large language models (LLMs) by applying steering vectors to modify model activations in forward passes. We employ Bayesian optimization to systematically identify effective contrastive pair datasets across nine bias axes. When optimized on the BBQ dataset, our individually tuned steering vectors achieve average improvements of 12.2%, 4.7%, and 3.2% over the baseline for Mistral, Llama, and Qwen, respectively. Building on these promising results, we introduce Steering Vector Ensembles (SVE), a method that averages multiple individually optimized steering vectors, each targeting a specific bias axis such as age, race, or gender. By leveraging their collective strength, SVE outperforms individual steering vectors in both bias reduction and maintaining model performance. The work presents the first systematic investigation of steering vectors for bias mitigation, and we demonstrate that SVE is a powerful and computationally efficient strategy for reducing bias in LLMs, with broader implications for enhancing AI safety.
Who is better at math, Jenny or Jingzhen? Uncovering Stereotypes in Large Language Models
Jul 09, 2024Large language models (LLMs) have been shown to propagate and amplify harmful stereotypes, particularly those that disproportionately affect marginalised communities. To understand the effect of these stereotypes more comprehensively, we introduce GlobalBias, a dataset of 876k sentences incorporating 40 distinct gender-by-ethnicity groups alongside descriptors typically used in bias literature, which enables us to study a broad set of stereotypes from around the world. We use GlobalBias to directly probe a suite of LMs via perplexity, which we use as a proxy to determine how certain stereotypes are represented in the model's internal representations. Following this, we generate character profiles based on given names and evaluate the prevalence of stereotypes in model outputs. We find that the demographic groups associated with various stereotypes remain consistent across model likelihoods and model outputs. Furthermore, larger models consistently display higher levels of stereotypical outputs, even when explicitly instructed not to.
Network Classification in Temporal Networks Using Motifs
Aug 07, 2018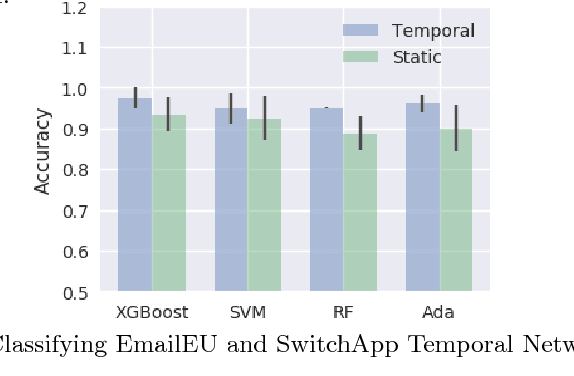
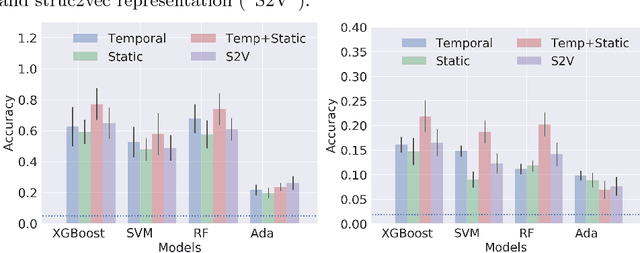
Network classification has a variety of applications, such as detecting communities within networks and finding similarities between those representing different aspects of the real world. However, most existing work in this area focus on examining static undirected networks without considering directed edges or temporality. In this paper, we propose a new methodology that utilizes feature representation for network classification based on the temporal motif distribution of the network and a null model for comparing against random graphs. Experimental results show that our method improves accuracy by up $10\%$ compared to the state-of-the-art embedding method in network classification, for tasks such as classifying network type, identifying communities in email exchange network, and identifying users given their app-switching behaviors.