 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decentralized Approach to Bayesian Learning
Jul 14, 2020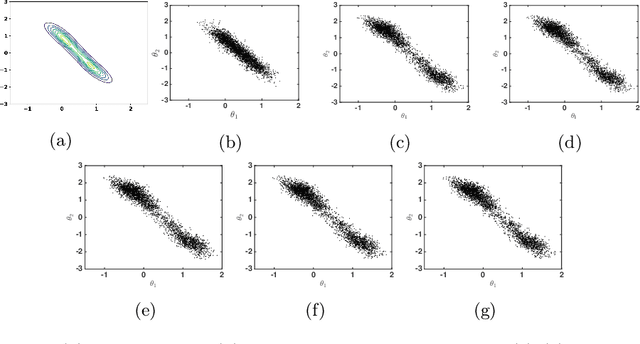
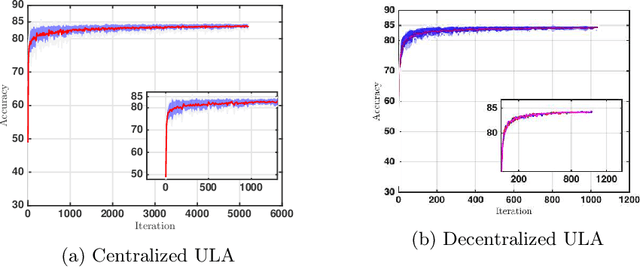
Motivated by decentralized approaches to machine learning, we propose a collaborative Bayesian learning algorithm taking the form of decentralized Langevin dynamics in a non-convex setting. Our analysis show that the initial KL-divergence between the Markov Chain and the target posterior distribution is exponentially decreasing while the error contributions to the overall KL-divergence from the additive noise is decreasing in polynomial time. We further show that the polynomial-term experiences speed-up with number of agents and provide sufficient conditions on the time-varying step-sizes to guarantee convergence to the desired distribution. The performance of the proposed algorithm is evaluated on a wide variety of machine learning tasks. The empirical results show that the performance of individual agents with locally available data is on par with the centralized setting with considerable improvement in the convergence rate.
Explaining Motion Relevance for Activity Recognition in Video Deep Learning Models
Mar 31, 2020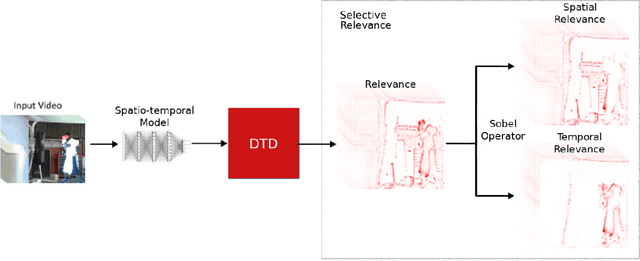
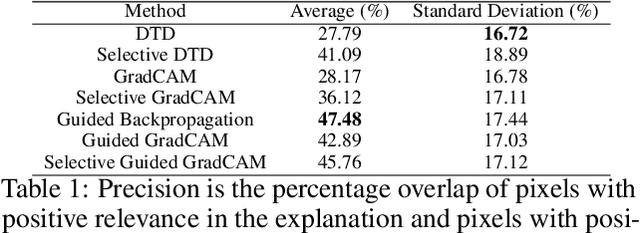
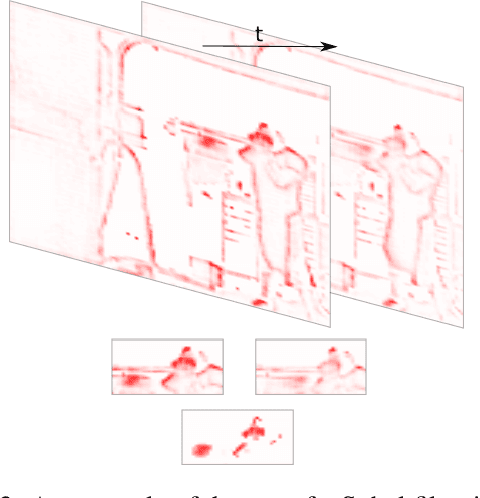

A small subset of explainability techniques developed initially for image recognition models has recently been applied for interpretability of 3D Convolutional Neural Network models in activity recognition tasks. Much like the models themselves, the techniques require little or no modification to be compatible with 3D inputs. However, these explanation techniques regard spatial and temporal information jointly. Therefore, using such explanation techniques, a user cannot explicitly distinguish the role of motion in a 3D model's decision. In fact, it has been shown that these models do not appropriately factor motion information into their decision. We propose a selective relevance method for adapting the 2D explanation techniques to provide motion-specific explanations, better aligning them with the human understanding of motion as conceptually separate from static spatial features. We demonstrate the utility of our method in conjunction with several widely-used 2D explanation methods, and show that it improves explanation selectivity for motion. Our results show that the selective relevance method can not only provide insight on the role played by motion in the model's decision -- in effect, revealing and quantifying the model's spatial bias -- but the method also simplifies the resulting explanations for human consumption.
Sanity Checks for Saliency Metrics
Nov 29, 2019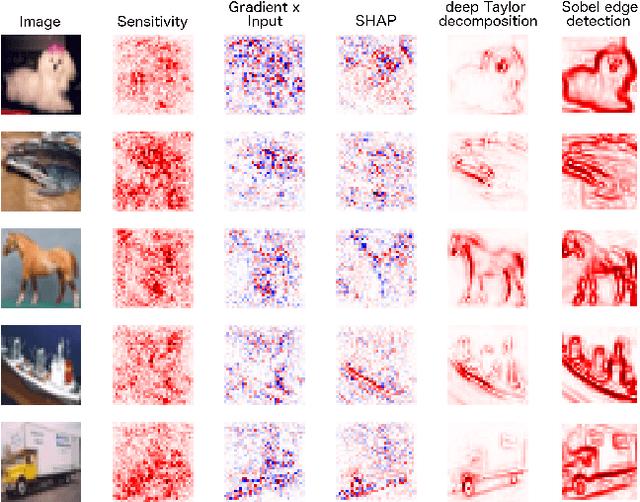
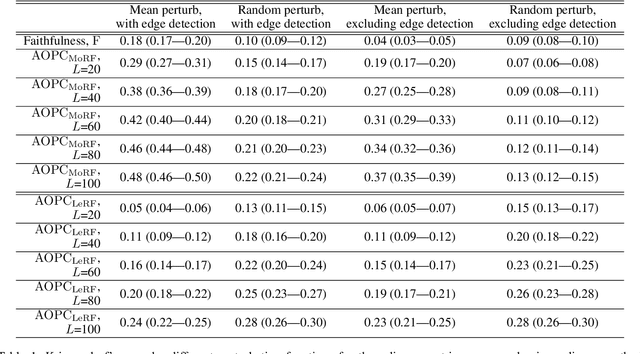
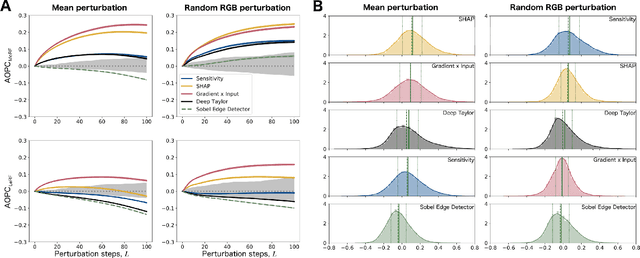
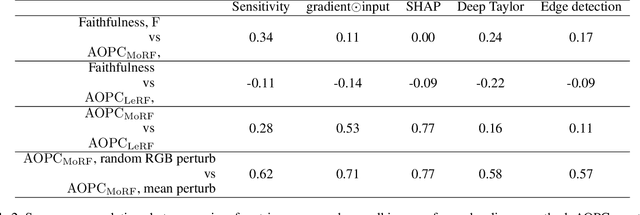
Saliency maps are a popular approach to creating post-hoc explanations of image classifier outputs. These methods produce estimates of the relevance of each pixel to the classification output score, which can be displayed as a saliency map that highlights important pixels. Despite a proliferation of such methods, little effort has been made to quantify how good these saliency maps are at capturing the true relevance of the pixels to the classifier output (i.e. their "fidelity"). We therefore investigate existing metrics for evaluating the fidelity of saliency methods (i.e. saliency metrics). We find that there is little consistency in the literature in how such metrics are calculated, and show that such inconsistencies can have a significant effect on the measured fidelity. Further, we apply measures of reliability developed in the psychometric testing literature to assess the consistency of saliency metrics when applied to individual saliency maps. Our results show that saliency metrics can be statistically unreliable and inconsistent, indicating that comparative rankings between saliency methods generated using such metrics can be untrustworthy.
Wasserstein Distance Based Domain Adaptation for Object Detection
Sep 18, 2019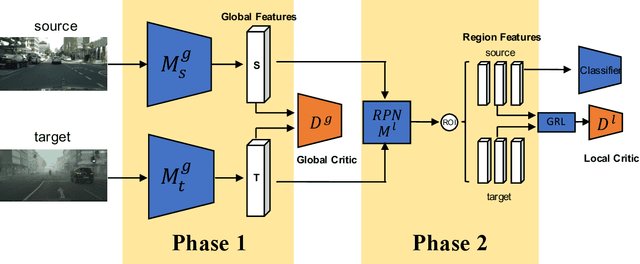
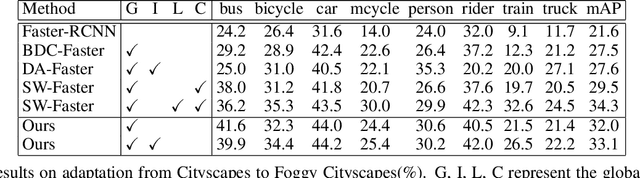


In this paper, we present an adversarial unsupervised domain adaptation framework for object detection. Prior approaches utilize adversarial training based on cross entropy between the source and target domain distributions to learn a shared feature mapping that minimizes the domain gap. Here, we minimize the Wasserstein distance between the two distributions instead of cross entropy or Jensen-Shannon divergence to improve the stability of domain adaptation in high-dimensional feature spaces that are inherent to object detection task. Additionally, we remove the exact consistency constraint of the shared feature mapping between the source and target domains, so that the target feature mapping can be optimized independently, which is necessary in the case of significant domain gap. We empirically show that the proposed framework can mitigate domain shift in different scenarios, and provide improved target domain object detection performance.
Distributed Deep Learning with Event-Triggered Communication
Sep 08, 2019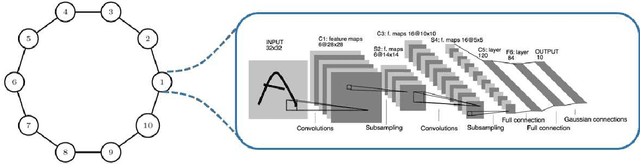
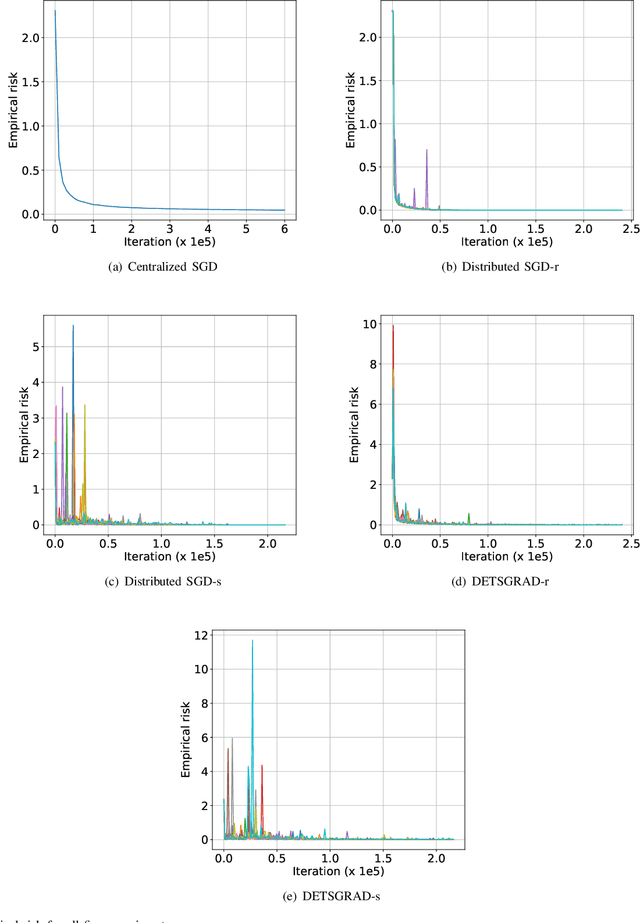
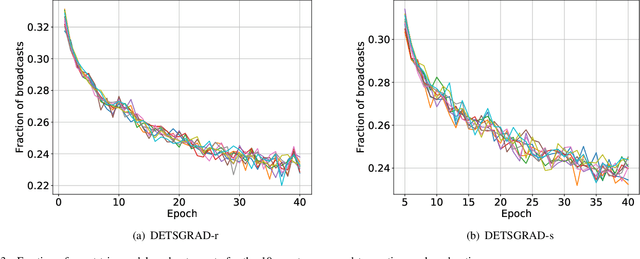
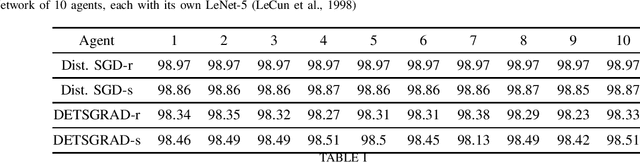
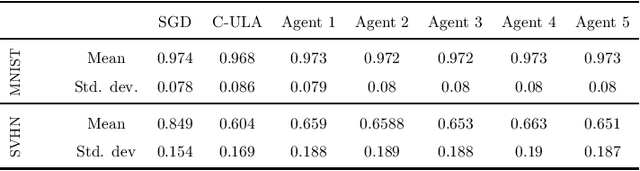
We develop a Distributed Event-Triggered Stochastic GRAdient Descent (DETSGRAD) algorithm for solving non-convex optimization problems typically encountered in distributed deep learning. We propose a novel communication triggering mechanism that would allow the networked agents to update their model parameters aperiodically and provide sufficient conditions on the algorithm step-sizes that guarantee the asymptotic mean-square convergence. The algorithm is applied to a distributed supervised-learning problem, in which a set of networked agents collaboratively train their individual neural networks to recognize handwritten digits in images, while aperiodically sharing the model parameters with their one-hop neighbors. Results indicate that all agents report similar performance that is also comparable to the performance of a centrally trained neural network, while the event-triggered communication provides significant reduction in inter-agent communication. Results also show that the proposed algorithm allows the individual agents to recognize the digits even though the training data corresponding to all the digits are not locally available to each agent.
Cyclostationary Statistical Models and Algorithms for Anomaly Detection Using Multi-Modal Data
Jul 02, 2018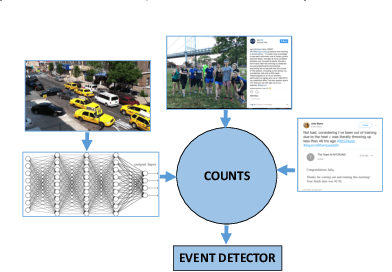
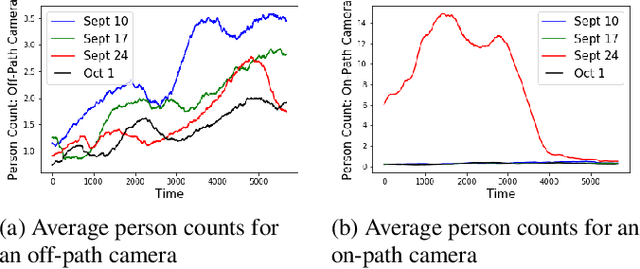
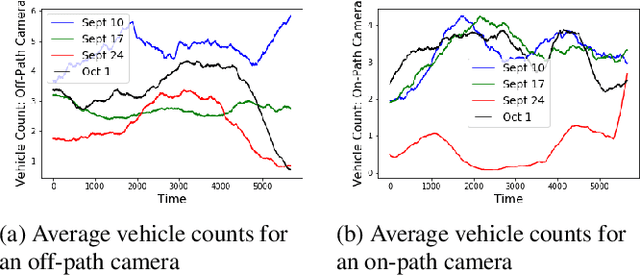
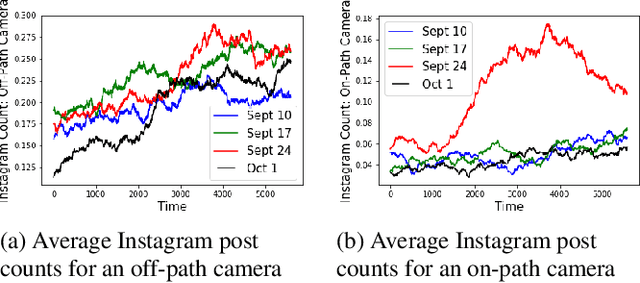
A framework is proposed to detect anomalies in multi-modal data. A deep neural network-based object detector is employed to extract counts of objects and sub-events from the data. A cyclostationary model is proposed to model regular patterns of behavior in the count sequences. The anomaly detection problem is formulated as a problem of detecting deviations from learned cyclostationary behavior. Sequential algorithms are proposed to detect anomalies using the proposed model. The proposed algorithms are shown to be asymptotically efficient in a well-defined sense. The developed algorithms are applied to a multi-modal data consisting of CCTV imagery and social media posts to detect a 5K run in New York City.
Human Action Attribute Learning From Video Data Using Low-Rank Representations
Dec 23, 2016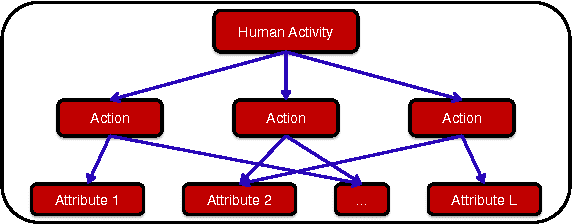
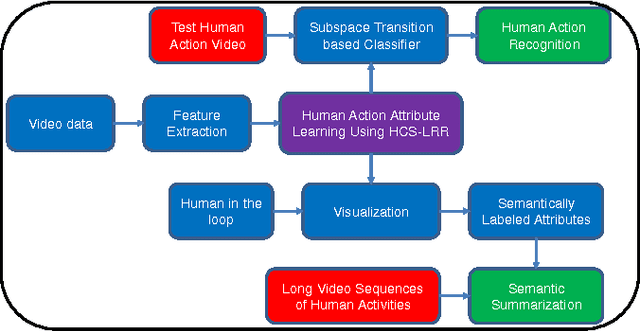


Representation of human actions as a sequence of human body movements or action attributes enables the development of models for human activity recognition and summarization. We present an extension of the low-rank representation (LRR) model, termed the clustering-aware structure-constrained low-rank representation (CS-LRR) model, for unsupervised learning of human action attributes from video data. Our model is based on the union-of-subspaces (UoS) framework, and integrates spectral clustering into the LRR optimization problem for better subspace clustering results. We lay out an efficient linear alternating direction method to solve the CS-LRR optimization problem. We also introduce a hierarchical subspace clustering approach, termed hierarchical CS-LRR, to learn the attributes without the need for a priori specification of their number. By visualizing and labeling these action attributes, the hierarchical model can be used to semantically summarize long video sequences of human actions at multiple resolutions. A human action or activity can also be uniquely represented as a sequence of transitions from one action attribute to another, which can then be used for human action recognition. We demonstrate the effectiveness of the proposed model for semantic summarization and action recognition through comprehensive experiments on five real-world human action datasets.
Optimal Sparse Kernel Learning for Hyperspectral Anomaly Detection
Jun 08, 2015
In this paper, a novel framework of sparse kernel learning for Support Vector Data Description (SVDD) based anomaly detection is presented. In this work, optimal sparse feature selection for anomaly detection is first modeled as a Mixed Integer Programming (MIP) problem. Due to the prohibitively high computational complexity of the MIP, it is relaxed into a Quadratically Constrained Linear Programming (QCLP) problem. The QCLP problem can then be practically solved by using an iterative optimization method, in which multiple subsets of features are iteratively found as opposed to a single subset. The QCLP-based iterative optimization problem is solved in a finite space called the \emph{Empirical Kernel Feature Space} (EKFS) instead of in the input space or \emph{Reproducing Kernel Hilbert Space} (RKHS). This is possible because of the fact that the geometrical properties of the EKFS and the corresponding RKHS remain the same. Now, an explicit nonlinear exploitation of the data in a finite EKFS is achievable, which results in optimal feature ranking. Experimental results based on a hyperspectral image show that the proposed method can provide improved performance over the current state-of-the-art techniques.