 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence of Asynchronous Parallel Iteration with Unbounded Delays
Nov 15, 2017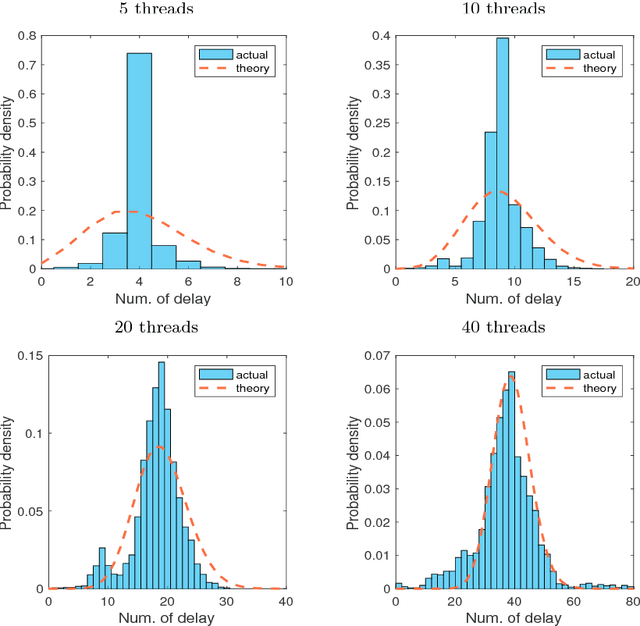
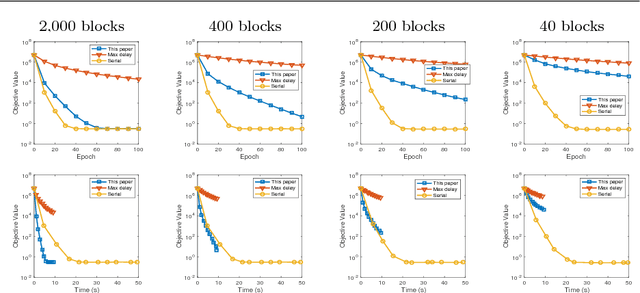
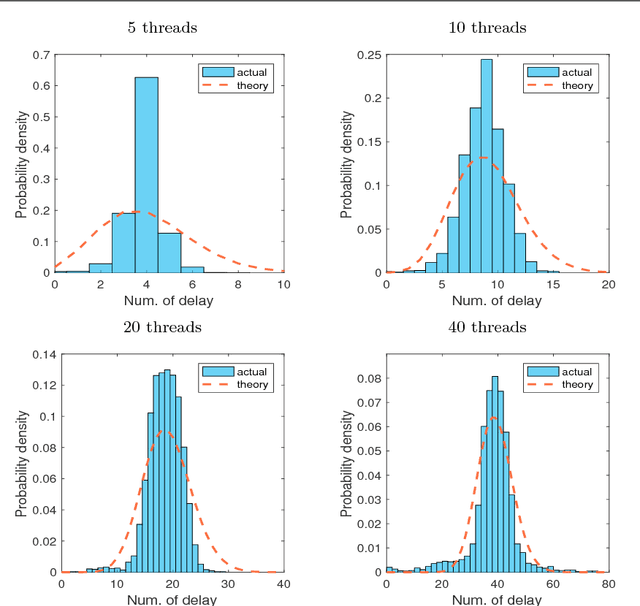
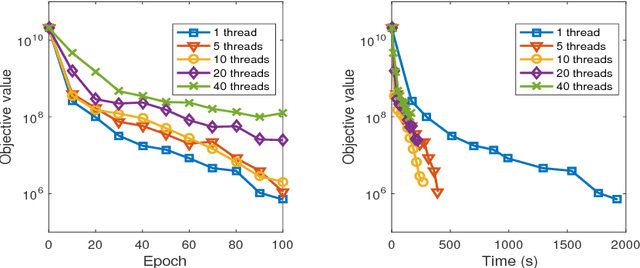
Recent years have witnessed the surge of asynchronous parallel (async-parallel) iterative algorithms due to problems involving very large-scale data and a large number of decision variables. Because of asynchrony, the iterates are computed with outdated information, and the age of the outdated information, which we call delay, is the number of times it has been updated since its creation. Almost all recent works prove convergence under the assumption of a finite maximum delay and set their stepsize parameters accordingly. However, the maximum delay is practically unknown. This paper presents convergence analysis of an async-parallel method from a probabilistic viewpoint, and it allows for large unbounded delays. An explicit formula of stepsize that guarantees convergence is given depending on delays' statistics. With $p+1$ identical processors, we empirically measured that delays closely follow the Poisson distribution with parameter $p$, matching our theoretical model, and thus the stepsize can be set accordingly. Simulations on both convex and nonconvex optimization problems demonstrate the validness of our analysis and also show that the existing maximum-delay induced stepsize is too conservative, often slowing down the convergence of the algorithm.
Coordinate Friendly Structures, Algorithms and Applications
Aug 14, 2016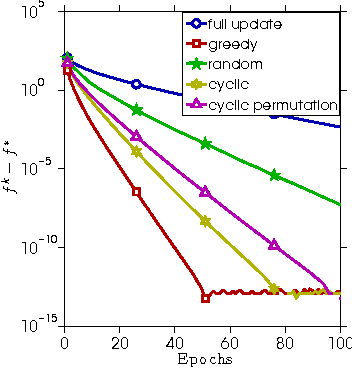
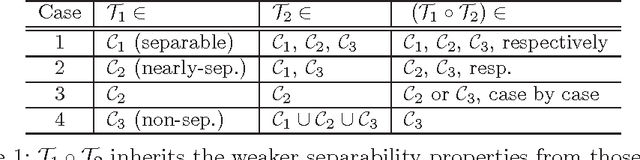

This paper focuses on coordinate update methods, which are useful for solving problems involving large or high-dimensional datasets. They decompose a problem into simple subproblems, where each updates one, or a small block of, variables while fixing others. These methods can deal with linear and nonlinear mappings, smooth and nonsmooth functions, as well as convex and nonconvex problems. In addition, they are easy to parallelize. The great performance of coordinate update methods depends on solving simple sub-problems. To derive simple subproblems for several new classes of applications, this paper systematically studies coordinate-friendly operators that perform low-cost coordinate updates. Based on the discovered coordinate friendly operators, as well as operator splitting techniques, we obtain new coordinate update algorithms for a variety of problems in machine learning, image processing, as well as sub-areas of optimization. Several problems are treated with coordinate update for the first time in history. The obtained algorithms are scalable to large instances through parallel and even asynchronous computing. We present numerical examples to illustrate how effective these algorithms are.
ARock: an Algorithmic Framework for Asynchronous Parallel Coordinate Updates
May 27, 2016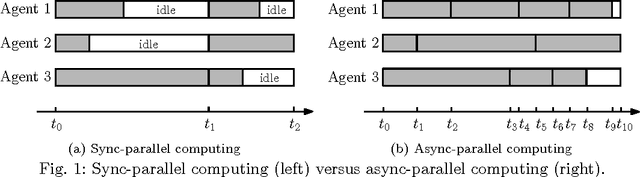

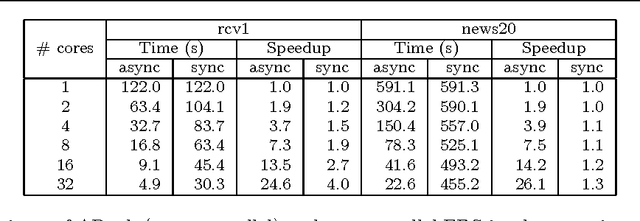
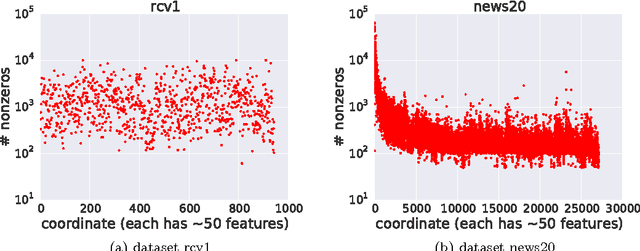
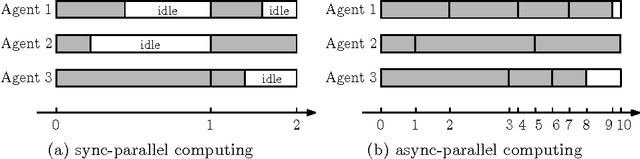
Finding a fixed point to a nonexpansive operator, i.e., $x^*=Tx^*$, abstracts many problems in numerical linear algebra, optimization, and other areas of scientific computing. To solve fixed-point problems, we propose ARock, an algorithmic framework in which multiple agents (machines, processors, or cores) update $x$ in an asynchronous parallel fashion. Asynchrony is crucial to parallel computing since it reduces synchronization wait, relaxes communication bottleneck, and thus speeds up computing significantly. At each step of ARock, an agent updates a randomly selected coordinate $x_i$ based on possibly out-of-date information on $x$. The agents share $x$ through either global memory or communication. If writing $x_i$ is atomic, the agents can read and write $x$ without memory locks. Theoretically, we show that if the nonexpansive operator $T$ has a fixed point, then with probability one, ARock generates a sequence that converges to a fixed points of $T$. Our conditions on $T$ and step sizes are weaker than comparable work. Linear convergence is also obtained. We propose special cases of ARock for linear systems, convex optimization, machine learning, as well as distributed and decentralized consensus problems. Numerical experiments of solving sparse logistic regression problems are presented.
* updated the linear convergence proofs
Optimal Sparse Kernel Learning for Hyperspectral Anomaly Detection
Jun 08, 2015
In this paper, a novel framework of sparse kernel learning for Support Vector Data Description (SVDD) based anomaly detection is presented. In this work, optimal sparse feature selection for anomaly detection is first modeled as a Mixed Integer Programming (MIP) problem. Due to the prohibitively high computational complexity of the MIP, it is relaxed into a Quadratically Constrained Linear Programming (QCLP) problem. The QCLP problem can then be practically solved by using an iterative optimization method, in which multiple subsets of features are iteratively found as opposed to a single subset. The QCLP-based iterative optimization problem is solved in a finite space called the \emph{Empirical Kernel Feature Space} (EKFS) instead of in the input space or \emph{Reproducing Kernel Hilbert Space} (RKHS). This is possible because of the fact that the geometrical properties of the EKFS and the corresponding RKHS remain the same. Now, an explicit nonlinear exploitation of the data in a finite EKFS is achievable, which results in optimal feature ranking. Experimental results based on a hyperspectral image show that the proposed method can provide improved performance over the current state-of-the-art techniques.