 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Motion Relevance for Activity Recognition in Video Deep Learning Models
Mar 31, 2020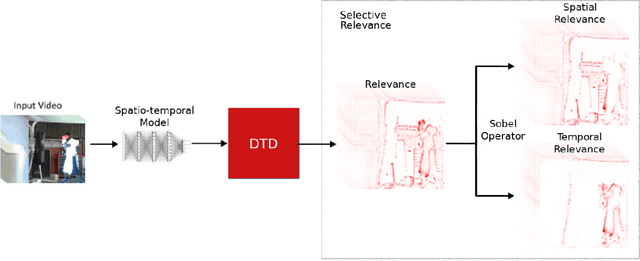
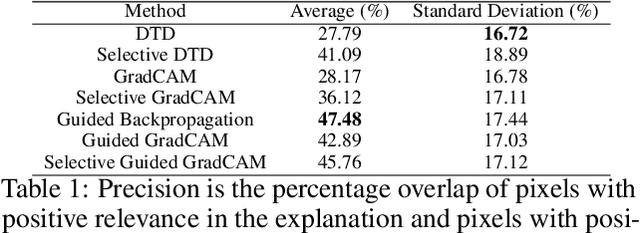

A small subset of explainability techniques developed initially for image recognition models has recently been applied for interpretability of 3D Convolutional Neural Network models in activity recognition tasks. Much like the models themselves, the techniques require little or no modification to be compatible with 3D inputs. However, these explanation techniques regard spatial and temporal information jointly. Therefore, using such explanation techniques, a user cannot explicitly distinguish the role of motion in a 3D model's decision. In fact, it has been shown that these models do not appropriately factor motion information into their decision. We propose a selective relevance method for adapting the 2D explanation techniques to provide motion-specific explanations, better aligning them with the human understanding of motion as conceptually separate from static spatial features. We demonstrate the utility of our method in conjunction with several widely-used 2D explanation methods, and show that it improves explanation selectivity for motion. Our results show that the selective relevance method can not only provide insight on the role played by motion in the model's decision -- in effect, revealing and quantifying the model's spatial bias -- but the method also simplifies the resulting explanations for human consumption.
Explainable Deep Learning for Video Recognition Tasks: A Framework & Recommendations
Sep 07, 2019The popularity of Deep Learning for real-world applications is ever-growing. With the introduction of high performance hardware, applications are no longer limited to image recognition. With the introduction of more complex problems comes more and more complex solutions, and the increasing need for explainable AI. Deep Neural Networks for Video tasks are amongst the most complex models, with at least twice the parameters of their Image counterparts. However, explanations for these models are often ill-adapted to the video domain. The current work in explainability for video models is still overshadowed by Image techniques, while Video Deep Learning itself is quickly gaining on methods for still images. This paper seeks to highlight the need for explainability methods designed with video deep learning models, and by association spatio-temporal input in mind, by first illustrating the cutting edge for video deep learning, and then noting the scarcity of research into explanations for these methods.
Discriminating Spatial and Temporal Relevance in Deep Taylor Decompositions for Explainable Activity Recognition
Aug 14, 2019

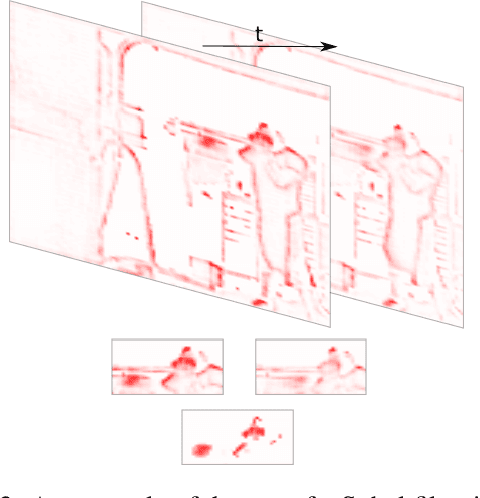
Current techniques for explainable AI have been applied with some success to image processing. The recent rise of research in video processing has called for similar work n deconstructing and explaining spatio-temporal models. While many techniques are designed for 2D convolutional models, others are inherently applicable to any input domain. One such body of work, deep Taylor decomposition, propagates relevance from the model output distributively onto its input and thus is not restricted to image processing models. However, by exploiting a simple technique that removes motion information, we show that it is not the case that this technique is effective as-is for representing relevance in non-image tasks. We instead propose a discriminative method that produces a na\"ive representation of both the spatial and temporal relevance of a frame as two separate objects. This new discriminative relevance model exposes relevance in the frame attributed to motion, that was previously ambiguous in the original explanation. We observe the effectiveness of this technique on a range of samples from the UCF-101 action recognition dataset, two of which are demonstrated in this paper.