 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive political surveys and GPT-4: Tackling the cold start problem with simulated user interactions
Mar 12, 2025Adaptive questionnaires dynamically select the next question for a survey participant based on their previous answers. Due to digitalisation, they have become a viable alternative to traditional surveys in application areas such as political science. One limitation, however, is their dependency on data to train the model for question selection. Often, such training data (i.e., user interactions) are unavailable a priori. To address this problem, we (i) test whether Large Language Models (LLM) can accurately generate such interaction data and (ii) explore if these synthetic data can be used to pre-train the statistical model of an adaptive political survey. To evaluate this approach, we utilise existing data from the Swiss Voting Advice Application (VAA) Smartvote in two ways: First, we compare the distribution of LLM-generated synthetic data to the real distribution to assess its similarity. Second, we compare the performance of an adaptive questionnaire that is randomly initialised with one pre-trained on synthetic data to assess their suitability for training. We benchmark these results against an "oracle" questionnaire with perfect prior knowledge. We find that an off-the-shelf LLM (GPT-4) accurately generates answers to the Smartvote questionnaire from the perspective of different Swiss parties. Furthermore, we demonstrate that initialising the statistical model with synthetic data can (i) significantly reduce the error in predicting user responses and (ii) increase the candidate recommendation accuracy of the VAA. Our work emphasises the considerable potential of LLMs to create training data to improve the data collection process in adaptive questionnaires in LLM-affine areas such as political surveys.
Bridging Voting and Deliberation with Algorithms: Field Insights from vTaiwan and Kultur Komitee
Feb 07, 2025Democratic processes increasingly aim to integrate large-scale voting with face-to-face deliberation, addressing the challenge of reconciling individual preferences with collective decision-making. This work introduces new methods that use algorithms and computational tools to bridge online voting with face-to-face deliberation, tested in two real-world scenarios: Kultur Komitee 2024 (KK24) and vTaiwan. These case studies highlight the practical applications and impacts of the proposed methods. We present three key contributions: (1) Radial Clustering for Preference Based Subgroups, which enables both in-depth and broad discussions in deliberative settings by computing homogeneous and heterogeneous group compositions with balanced and adjustable group sizes; (2) Human-in-the-loop MES, a practical method that enhances the Method of Equal Shares (MES) algorithm with real-time digital feedback. This builds algorithmic trust by giving participants full control over how much decision-making is delegated to the voting aggregation algorithm as compared to deliberation; and (3) the ReadTheRoom deliberation method, which uses opinion space mapping to identify agreement and divergence, along with spectrum-based preference visualisation to track opinion shifts during deliberation. This approach enhances transparency by clarifying collective sentiment and fosters collaboration by encouraging participants to engage constructively with differing perspectives. By introducing these actionable frameworks, this research extends in-person deliberation with scalable digital methods that address the complexities of modern decision-making in participatory processes.
Fast and Adaptive Questionnaires for Voting Advice Applications
Apr 02, 2024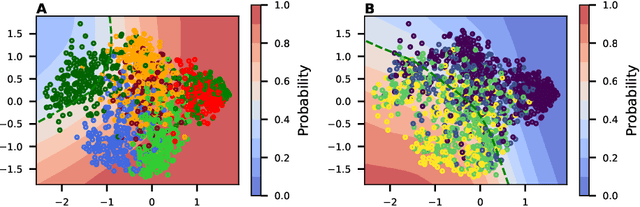
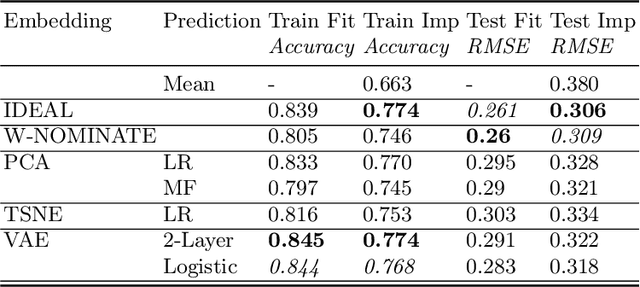
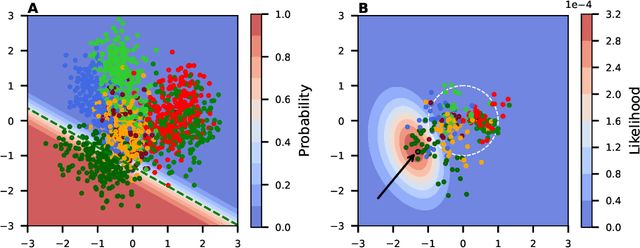
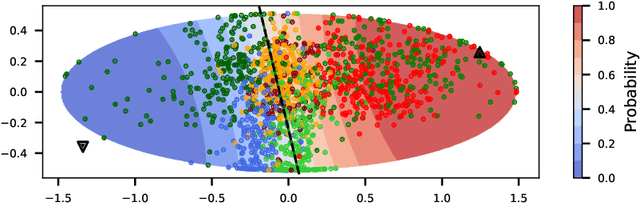
The effectiveness of Voting Advice Applications (VAA) is often compromised by the length of their questionnaires. To address user fatigue and incomplete responses, some applications (such as the Swiss Smartvote) offer a condensed version of their questionnaire. However, these condensed versions can not ensure the accuracy of recommended parties or candidates, which we show to remain below 40%. To tackle these limitations, this work introduces an adaptive questionnaire approach that selects subsequent questions based on users' previous answers, aiming to enhance recommendation accuracy while reducing the number of questions posed to the voters. Our method uses an encoder and decoder module to predict missing values at any completion stage, leveraging a two-dimensional latent space reflective of political science's traditional methods for visualizing political orientations. Additionally, a selector module is proposed to determine the most informative subsequent question based on the voter's current position in the latent space and the remaining unanswered questions. We validated our approach using the Smartvote dataset from the Swiss Federal elections in 2019, testing various spatial models and selection methods to optimize the system's predictive accuracy. Our findings indicate that employing the IDEAL model both as encoder and decoder, combined with a PosteriorRMSE method for question selection, significantly improves the accuracy of recommendations, achieving 74% accuracy after asking the same number of questions as in the condensed version.
Wasserstein t-SNE
May 16, 2022



Scientific datasets often have hierarchical structure: for example, in surveys, individual participants (samples) might be grouped at a higher level (units) such as their geographical region. In these settings, the interest is often in exploring the structure on the unit level rather than on the sample level. Units can be compared based on the distance between their means, however this ignores the within-unit distribution of samples. Here we develop an approach for exploratory analysis of hierarchical datasets using the Wasserstein distance metric that takes into account the shapes of within-unit distributions. We use t-SNE to construct 2D embeddings of the units, based on the matrix of pairwise Wasserstein distances between them. The distance matrix can be efficiently computed by approximating each unit with a Gaussian distribution, but we also provide a scalable method to compute exact Wasserstein distances. We use synthetic data to demonstrate the effectiveness of our Wasserstein t-SNE, and apply it to data from the 2017 German parliamentary election, considering polling stations as samples and voting districts as units. The resulting embedding uncovers meaningful structure in the data.