 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuizzard@INOVA Challenge 2025 -- Track A: Plug-and-Play Technique in Interleaved Multi-Image Model
Jun 13, 2025This paper addresses two main objectives. Firstly, we demonstrate the impressive performance of the LLaVA-NeXT-interleave on 22 datasets across three different tasks: Multi-Image Reasoning, Documents and Knowledge-Based Understanding and Interactive Multi-Modal Communication. Secondly, we add the Dense Channel Integration (DCI) connector to the LLaVA-NeXT-Interleave and compare its performance against the standard model. We find that the standard model achieves the highest overall accuracy, excelling in vision-heavy tasks like VISION, NLVR2, and Fashion200K. Meanwhile, the DCI-enhanced version shows particular strength on datasets requiring deeper semantic coherence or structured change understanding such as MIT-States_PropertyCoherence and SlideVQA. Our results highlight the potential of combining powerful foundation models with plug-and-play techniques for Interleave tasks. The code is available at https://github.com/dinhvietcuong1996/icme25-inova.
The CASTLE 2024 Dataset: Advancing the Art of Multimodal Understanding
Mar 21, 2025Egocentric video has seen increased interest in recent years, as it is used in a range of areas. However, most existing datasets are limited to a single perspective. In this paper, we present the CASTLE 2024 dataset, a multimodal collection containing ego- and exo-centric (i.e., first- and third-person perspective) video and audio from 15 time-aligned sources, as well as other sensor streams and auxiliary data. The dataset was recorded by volunteer participants over four days in a fixed location and includes the point of view of 10 participants, with an additional 5 fixed cameras providing an exocentric perspective. The entire dataset contains over 600 hours of UHD video recorded at 50 frames per second. In contrast to other datasets, CASTLE 2024 does not contain any partial censoring, such as blurred faces or distorted audio. The dataset is available via https://castle-dataset.github.io/.
LoGra-Med: Long Context Multi-Graph Alignment for Medical Vision-Language Model
Oct 03, 2024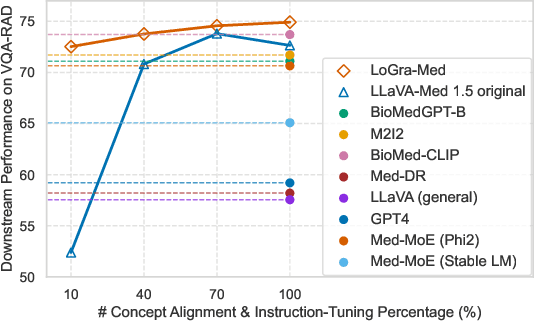
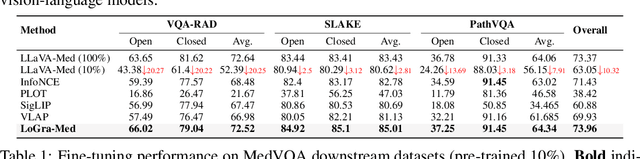
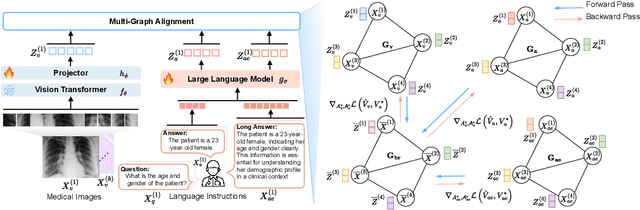
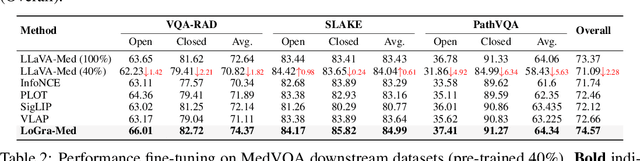
State-of-the-art medical multi-modal large language models (med-MLLM), like LLaVA-Med or BioMedGPT, leverage instruction-following data in pre-training. However, those models primarily focus on scaling the model size and data volume to boost performance while mainly relying on the autoregressive learning objectives. Surprisingly, we reveal that such learning schemes might result in a weak alignment between vision and language modalities, making these models highly reliant on extensive pre-training datasets - a significant challenge in medical domains due to the expensive and time-consuming nature of curating high-quality instruction-following instances. We address this with LoGra-Med, a new multi-graph alignment algorithm that enforces triplet correlations across image modalities, conversation-based descriptions, and extended captions. This helps the model capture contextual meaning, handle linguistic variability, and build cross-modal associations between visuals and text. To scale our approach, we designed an efficient end-to-end learning scheme using black-box gradient estimation, enabling faster LLaMa 7B training. Our results show LoGra-Med matches LLAVA-Med performance on 600K image-text pairs for Medical VQA and significantly outperforms it when trained on 10% of the data. For example, on VQA-RAD, we exceed LLAVA-Med by 20.13% and nearly match the 100% pre-training score (72.52% vs. 72.64%). We also surpass SOTA methods like BiomedGPT on visual chatbots and RadFM on zero-shot image classification with VQA, highlighting the effectiveness of multi-graph alignment.