 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptPrompt: Parameter-Efficient Adaptation of VLMs for Generalizable Deepfake Detection
Dec 19, 2025
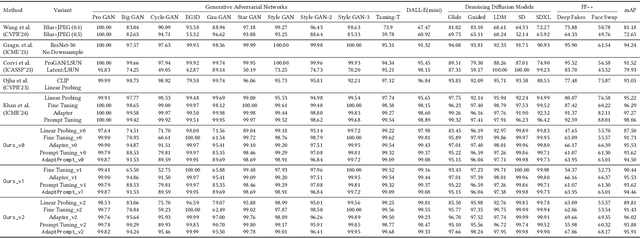
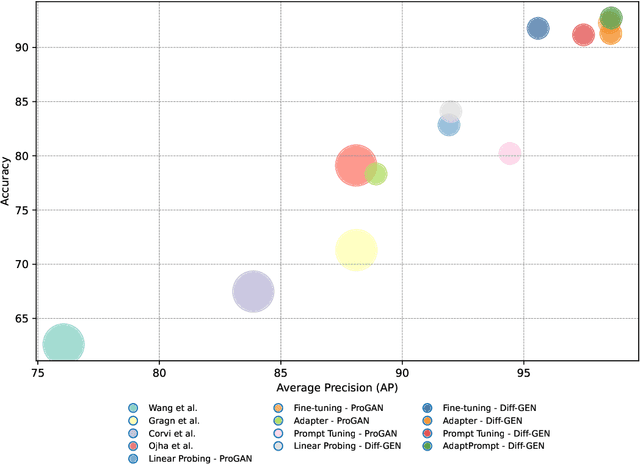
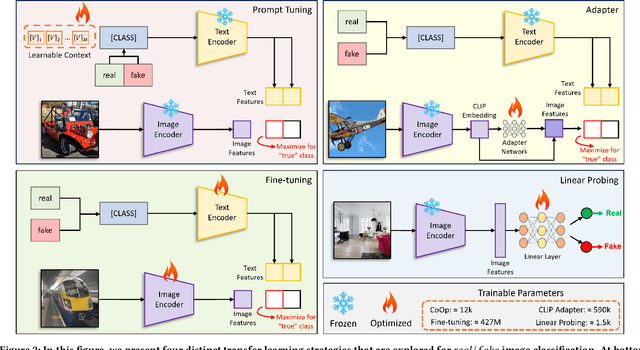
Recent advances in image generation have led to the widespread availability of highly realistic synthetic media, increasing the difficulty of reliable deepfake detection. A key challenge is generalization, as detectors trained on a narrow class of generators often fail when confronted with unseen models. In this work, we address the pressing need for generalizable detection by leveraging large vision-language models, specifically CLIP, to identify synthetic content across diverse generative techniques. First, we introduce Diff-Gen, a large-scale benchmark dataset comprising 100k diffusion-generated fakes that capture broad spectral artifacts unlike traditional GAN datasets. Models trained on Diff-Gen demonstrate stronger cross-domain generalization, particularly on previously unseen image generators. Second, we propose AdaptPrompt, a parameter-efficient transfer learning framework that jointly learns task-specific textual prompts and visual adapters while keeping the CLIP backbone frozen. We further show via layer ablation that pruning the final transformer block of the vision encoder enhances the retention of high-frequency generative artifacts, significantly boosting detection accuracy. Our evaluation spans 25 challenging test sets, covering synthetic content generated by GANs, diffusion models, and commercial tools, establishing a new state-of-the-art in both standard and cross-domain scenarios. We further demonstrate the framework's versatility through few-shot generalization (using as few as 320 images) and source attribution, enabling the precise identification of generator architectures in closed-set settings.
The State-of-the-Art in Lifelog Retrieval: A Review of Progress at the ACM Lifelog Search Challenge Workshop 2022-24
Jun 07, 2025The ACM Lifelog Search Challenge (LSC) is a venue that welcomes and compares systems that support the exploration of lifelog data, and in particular the retrieval of specific information, through an interactive competition format. This paper reviews the recent advances in interactive lifelog retrieval as demonstrated at the ACM LSC from 2022 to 2024. Through a detailed comparative analysis, we highlight key improvements across three main retrieval tasks: known-item search, question answering, and ad-hoc search. Our analysis identifies trends such as the widespread adoption of embedding-based retrieval methods (e.g., CLIP, BLIP), increased integration of large language models (LLMs) for conversational retrieval, and continued innovation in multimodal and collaborative search interfaces. We further discuss how specific retrieval techniques and user interface (UI) designs have impacted system performance, emphasizing the importance of balancing retrieval complexity with usability. Our findings indicate that embedding-driven approaches combined with LLMs show promise for lifelog retrieval systems. Likewise, improving UI design can enhance usability and efficiency. Additionally, we recommend reconsidering multi-instance system evaluations within the expert track to better manage variability in user familiarity and configuration effectiveness.
The CASTLE 2024 Dataset: Advancing the Art of Multimodal Understanding
Mar 21, 2025Egocentric video has seen increased interest in recent years, as it is used in a range of areas. However, most existing datasets are limited to a single perspective. In this paper, we present the CASTLE 2024 dataset, a multimodal collection containing ego- and exo-centric (i.e., first- and third-person perspective) video and audio from 15 time-aligned sources, as well as other sensor streams and auxiliary data. The dataset was recorded by volunteer participants over four days in a fixed location and includes the point of view of 10 participants, with an additional 5 fixed cameras providing an exocentric perspective. The entire dataset contains over 600 hours of UHD video recorded at 50 frames per second. In contrast to other datasets, CASTLE 2024 does not contain any partial censoring, such as blurred faces or distorted audio. The dataset is available via https://castle-dataset.github.io/.
CLIPping the Deception: Adapting Vision-Language Models for Universal Deepfake Detection
Feb 20, 2024


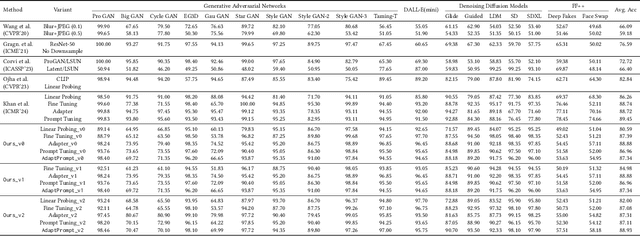
The recent advancements in Generative Adversarial Networks (GANs) and the emergence of Diffusion models have significantly streamlined the production of highly realistic and widely accessible synthetic content. As a result, there is a pressing need for effective general purpose detection mechanisms to mitigate the potential risks posed by deepfakes. In this paper, we explore the effectiveness of pre-trained vision-language models (VLMs) when paired with recent adaptation methods for universal deepfake detection. Following previous studies in this domain, we employ only a single dataset (ProGAN) in order to adapt CLIP for deepfake detection. However, in contrast to prior research, which rely solely on the visual part of CLIP while ignoring its textual component, our analysis reveals that retaining the text part is crucial. Consequently, the simple and lightweight Prompt Tuning based adaptation strategy that we employ outperforms the previous SOTA approach by 5.01% mAP and 6.61% accuracy while utilizing less than one third of the training data (200k images as compared to 720k). To assess the real-world applicability of our proposed models, we conduct a comprehensive evaluation across various scenarios. This involves rigorous testing on images sourced from 21 distinct datasets, including those generated by GANs-based, Diffusion-based and Commercial tools.
Online Multimedia Verification with Computational Tools and OSINT: Russia-Ukraine Conflict Case Studies
Oct 03, 2023This paper investigates the use of computational tools and Open-Source Intelligence (OSINT) techniques for verifying online multimedia content, with a specific focus on real-world cases from the Russia-Ukraine conflict. Over a nine-month period from April to December 2022, we examine verification workflows, tools, and case studies published by \faktiskbar. Our study showcases the effectiveness of diverse resources, including AI tools, geolocation tools, internet archives, and social media monitoring platforms, in enabling journalists and fact-checkers to efficiently process and corroborate evidence, ensuring the dissemination of accurate information. This research underscores the vital role of computational tools and OSINT techniques in promoting evidence-based reporting and combatting misinformation. We also touch on the current limitations of available tools and prospects for future developments in multimedia verification.
Detecting Out-of-Context Image-Caption Pairs in News: A Counter-Intuitive Method
Aug 31, 2023



The growth of misinformation and re-contextualized media in social media and news leads to an increasing need for fact-checking methods. Concurrently, the advancement in generative models makes cheapfakes and deepfakes both easier to make and harder to detect. In this paper, we present a novel approach using generative image models to our advantage for detecting Out-of-Context (OOC) use of images-caption pairs in news. We present two new datasets with a total of $6800$ images generated using two different generative models including (1) DALL-E 2, and (2) Stable-Diffusion. We are confident that the method proposed in this paper can further research on generative models in the field of cheapfake detection, and that the resulting datasets can be used to train and evaluate new models aimed at detecting cheapfakes. We run a preliminary qualitative and quantitative analysis to evaluate the performance of each image generation model for this task, and evaluate a handful of methods for computing image similarity.
Deepfake Detection: A Comparative Analysis
Aug 07, 2023This paper present a comprehensive comparative analysis of supervised and self-supervised models for deepfake detection. We evaluate eight supervised deep learning architectures and two transformer-based models pre-trained using self-supervised strategies (DINO, CLIP) on four benchmarks (FakeAVCeleb, CelebDF-V2, DFDC, and FaceForensics++). Our analysis includes intra-dataset and inter-dataset evaluations, examining the best performing models, generalisation capabilities, and impact of augmentations. We also investigate the trade-off between model size and performance. Our main goal is to provide insights into the effectiveness of different deep learning architectures (transformers, CNNs), training strategies (supervised, self-supervised), and deepfake detection benchmarks. These insights can help guide the development of more accurate and reliable deepfake detection systems, which are crucial in mitigating the harmful impact of deepfakes on individuals and society.
Grand Challenge On Detecting Cheapfakes
Apr 03, 2023Cheapfake is a recently coined term that encompasses non-AI ("cheap") manipulations of multimedia content. Cheapfakes are known to be more prevalent than deepfakes. Cheapfake media can be created using editing software for image/video manipulations, or even without using any software, by simply altering the context of an image/video by sharing the media alongside misleading claims. This alteration of context is referred to as out-of-context (OOC) misuse of media. OOC media is much harder to detect than fake media, since the images and videos are not tampered. In this challenge, we focus on detecting OOC images, and more specifically the misuse of real photographs with conflicting image captions in news items. The aim of this challenge is to develop and benchmark models that can be used to detect whether given samples (news image and associated captions) are OOC, based on the recently compiled COSMOS dataset.
Hybrid Transformer Network for Deepfake Detection
Aug 11, 2022

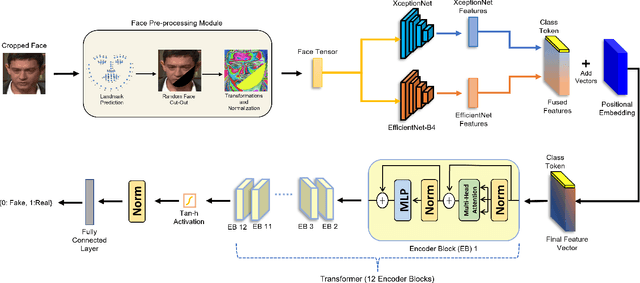

Deepfake media is becoming widespread nowadays because of the easily available tools and mobile apps which can generate realistic looking deepfake videos/images without requiring any technical knowledge. With further advances in this field of technology in the near future, the quantity and quality of deepfake media is also expected to flourish, while making deepfake media a likely new practical tool to spread mis/disinformation. Because of these concerns, the deepfake media detection tools are becoming a necessity. In this study, we propose a novel hybrid transformer network utilizing early feature fusion strategy for deepfake video detection. Our model employs two different CNN networks, i.e., (1) XceptionNet and (2) EfficientNet-B4 as feature extractors. We train both feature extractors along with the transformer in an end-to-end manner on FaceForensics++, DFDC benchmarks. Our model, while having relatively straightforward architecture, achieves comparable results to other more advanced state-of-the-art approaches when evaluated on FaceForensics++ and DFDC benchmarks. Besides this, we also propose novel face cut-out augmentations, as well as random cut-out augmentations. We show that the proposed augmentations improve the detection performance of our model and reduce overfitting. In addition to that, we show that our model is capable of learning from considerably small amount of data.