 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoGra-Med: Long Context Multi-Graph Alignment for Medical Vision-Language Model
Oct 03, 2024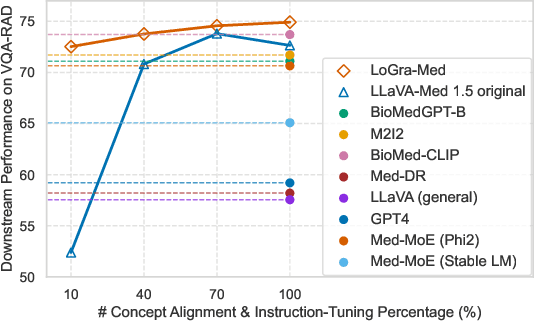
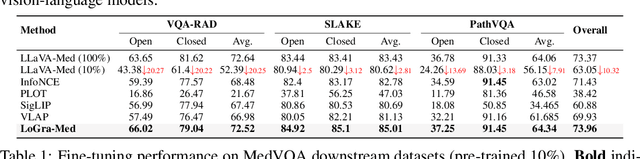
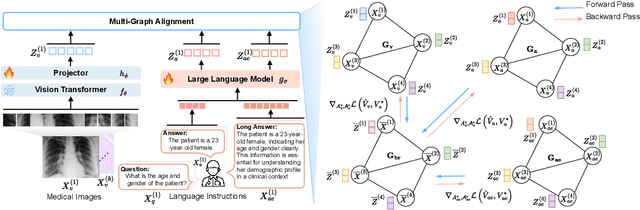
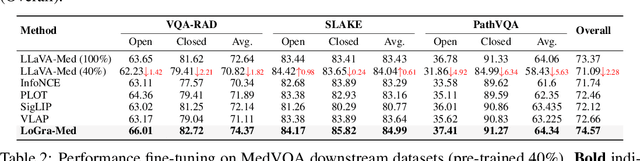
State-of-the-art medical multi-modal large language models (med-MLLM), like LLaVA-Med or BioMedGPT, leverage instruction-following data in pre-training. However, those models primarily focus on scaling the model size and data volume to boost performance while mainly relying on the autoregressive learning objectives. Surprisingly, we reveal that such learning schemes might result in a weak alignment between vision and language modalities, making these models highly reliant on extensive pre-training datasets - a significant challenge in medical domains due to the expensive and time-consuming nature of curating high-quality instruction-following instances. We address this with LoGra-Med, a new multi-graph alignment algorithm that enforces triplet correlations across image modalities, conversation-based descriptions, and extended captions. This helps the model capture contextual meaning, handle linguistic variability, and build cross-modal associations between visuals and text. To scale our approach, we designed an efficient end-to-end learning scheme using black-box gradient estimation, enabling faster LLaMa 7B training. Our results show LoGra-Med matches LLAVA-Med performance on 600K image-text pairs for Medical VQA and significantly outperforms it when trained on 10% of the data. For example, on VQA-RAD, we exceed LLAVA-Med by 20.13% and nearly match the 100% pre-training score (72.52% vs. 72.64%). We also surpass SOTA methods like BiomedGPT on visual chatbots and RadFM on zero-shot image classification with VQA, highlighting the effectiveness of multi-graph alignment.
Dude: Dual Distribution-Aware Context Prompt Learning For Large Vision-Language Model
Jul 05, 2024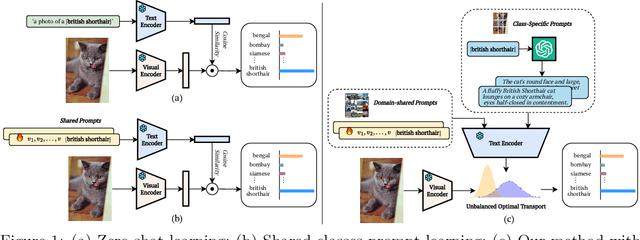
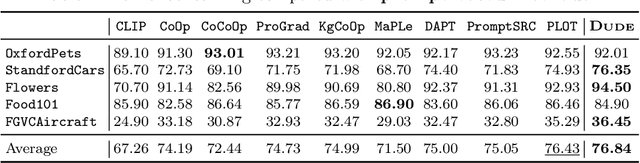
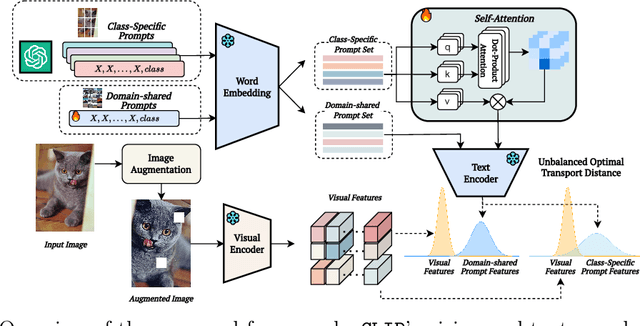
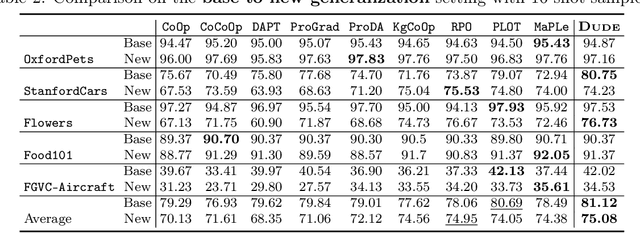
Prompt learning methods are gaining increasing attention due to their ability to customize large vision-language models to new domains using pre-trained contextual knowledge and minimal training data. However, existing works typically rely on optimizing unified prompt inputs, often struggling with fine-grained classification tasks due to insufficient discriminative attributes. To tackle this, we consider a new framework based on a dual context of both domain-shared and class-specific contexts, where the latter is generated by Large Language Models (LLMs) such as GPTs. Such dual prompt methods enhance the model's feature representation by joining implicit and explicit factors encoded in LLM knowledge. Moreover, we formulate the Unbalanced Optimal Transport (UOT) theory to quantify the relationships between constructed prompts and visual tokens. Through partial matching, UOT can properly align discrete sets of visual tokens and prompt embeddings under different mass distributions, which is particularly valuable for handling irrelevant or noisy elements, ensuring that the preservation of mass does not restrict transport solutions. Furthermore, UOT's characteristics integrate seamlessly with image augmentation, expanding the training sample pool while maintaining a reasonable distance between perturbed images and prompt inputs. Extensive experiments across few-shot classification and adapter settings substantiate the superiority of our model over current state-of-the-art baselines.