 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025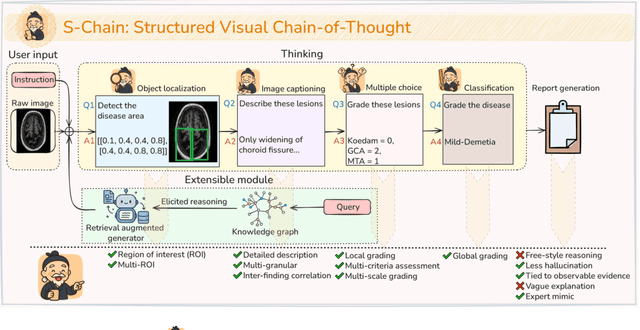
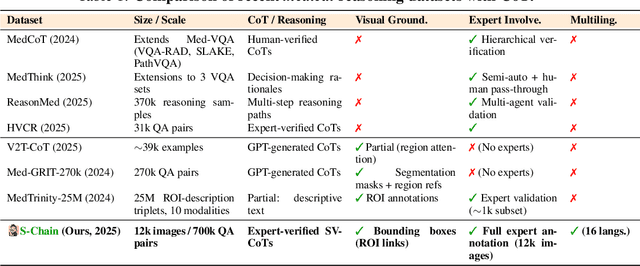
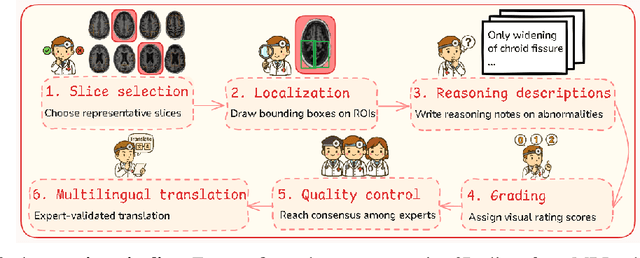
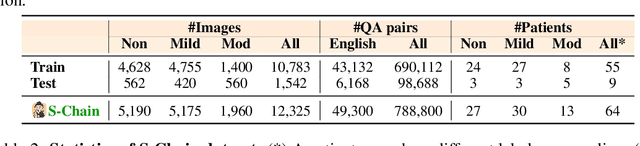
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
DoRAN: Stabilizing Weight-Decomposed Low-Rank Adaptation via Noise Injection and Auxiliary Networks
Oct 05, 2025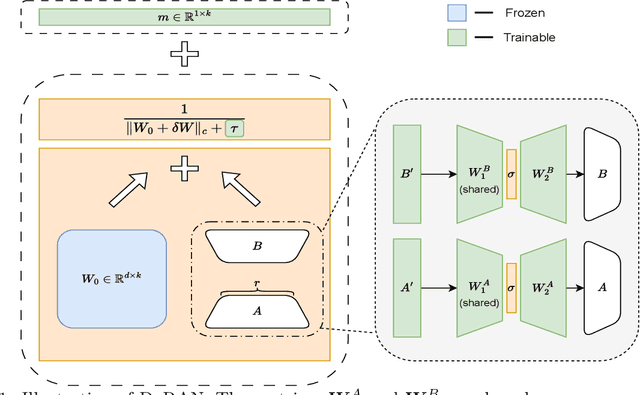

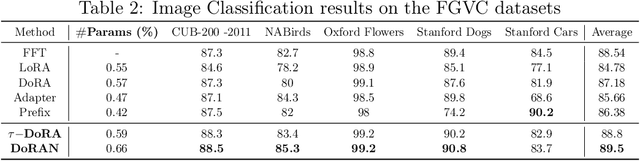
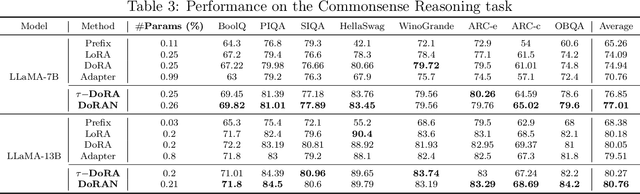
Parameter-efficient fine-tuning (PEFT) methods have become the standard paradigm for adapting large-scale models. Among these techniques, Weight-Decomposed Low-Rank Adaptation (DoRA) has been shown to improve both the learning capacity and training stability of the vanilla Low-Rank Adaptation (LoRA) method by explicitly decomposing pre-trained weights into magnitude and directional components. In this work, we propose DoRAN, a new variant of DoRA designed to further stabilize training and boost the sample efficiency of DoRA. Our approach includes two key stages: (i) injecting noise into the denominator of DoRA's weight decomposition, which serves as an adaptive regularizer to mitigate instabilities; and (ii) replacing static low-rank matrices with auxiliary networks that generate them dynamically, enabling parameter coupling across layers and yielding better sample efficiency in both theory and practice. Comprehensive experiments on vision and language benchmarks show that DoRAN consistently outperforms LoRA, DoRA, and other PEFT baselines. These results underscore the effectiveness of combining stabilization through noise-based regularization with network-based parameter generation, offering a promising direction for robust and efficient fine-tuning of foundation models.
HoRA: Cross-Head Low-Rank Adaptation with Joint Hypernetworks
Oct 05, 2025Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) technique that adapts large pre-trained models by adding low-rank matrices to their weight updates. However, in the context of fine-tuning multi-head self-attention (MHA), LoRA has been employed to adapt each attention head separately, thereby overlooking potential synergies across different heads. To mitigate this issue, we propose a novel Hyper-shared Low-Rank Adaptation (HoRA) method, which utilizes joint hypernetworks to generate low-rank matrices across attention heads. By coupling their adaptation through a shared generator, HoRA encourages cross-head information sharing, and thus directly addresses the aforementioned limitation of LoRA. By comparing LoRA and HoRA through the lens of hierarchical mixture of experts, our theoretical findings reveal that the latter achieves superior sample efficiency to the former. Furthermore, through extensive experiments across diverse language and vision benchmarks, we demonstrate that HoRA outperforms LoRA and other PEFT methods while requiring only a marginal increase in the number of trainable parameters.
On Zero-Initialized Attention: Optimal Prompt and Gating Factor Estimation
Feb 05, 2025



The LLaMA-Adapter has recently emerged as an efficient fine-tuning technique for LLaMA models, leveraging zero-initialized attention to stabilize training and enhance performance. However, despite its empirical success, the theoretical foundations of zero-initialized attention remain largely unexplored. In this paper, we provide a rigorous theoretical analysis, establishing a connection between zero-initialized attention and mixture-of-expert models. We prove that both linear and non-linear prompts, along with gating functions, can be optimally estimated, with non-linear prompts offering greater flexibility for future applications. Empirically, we validate our findings on the open LLM benchmarks, demonstrating that non-linear prompts outperform linear ones. Notably, even with limited training data, both prompt types consistently surpass vanilla attention, highlighting the robustness and adaptability of zero-initialized attention.
LoGra-Med: Long Context Multi-Graph Alignment for Medical Vision-Language Model
Oct 03, 2024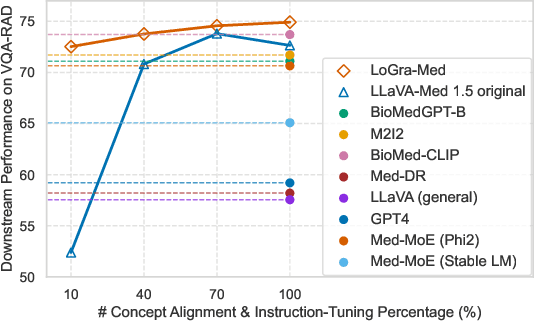
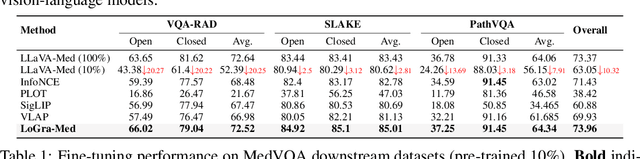
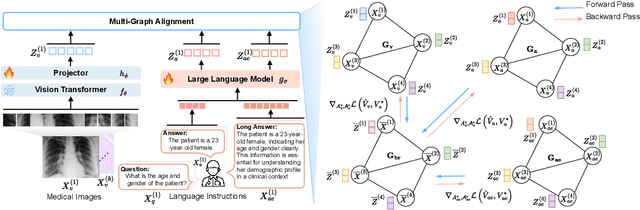
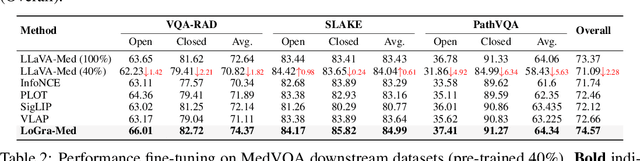
State-of-the-art medical multi-modal large language models (med-MLLM), like LLaVA-Med or BioMedGPT, leverage instruction-following data in pre-training. However, those models primarily focus on scaling the model size and data volume to boost performance while mainly relying on the autoregressive learning objectives. Surprisingly, we reveal that such learning schemes might result in a weak alignment between vision and language modalities, making these models highly reliant on extensive pre-training datasets - a significant challenge in medical domains due to the expensive and time-consuming nature of curating high-quality instruction-following instances. We address this with LoGra-Med, a new multi-graph alignment algorithm that enforces triplet correlations across image modalities, conversation-based descriptions, and extended captions. This helps the model capture contextual meaning, handle linguistic variability, and build cross-modal associations between visuals and text. To scale our approach, we designed an efficient end-to-end learning scheme using black-box gradient estimation, enabling faster LLaMa 7B training. Our results show LoGra-Med matches LLAVA-Med performance on 600K image-text pairs for Medical VQA and significantly outperforms it when trained on 10% of the data. For example, on VQA-RAD, we exceed LLAVA-Med by 20.13% and nearly match the 100% pre-training score (72.52% vs. 72.64%). We also surpass SOTA methods like BiomedGPT on visual chatbots and RadFM on zero-shot image classification with VQA, highlighting the effectiveness of multi-graph alignment.
Dude: Dual Distribution-Aware Context Prompt Learning For Large Vision-Language Model
Jul 05, 2024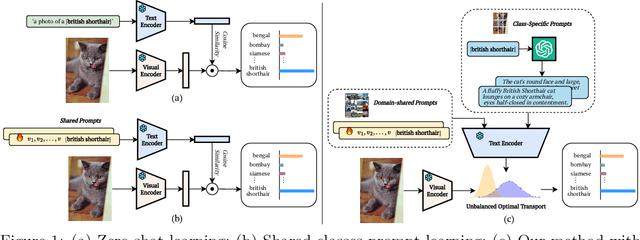
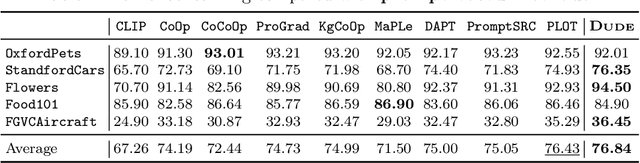
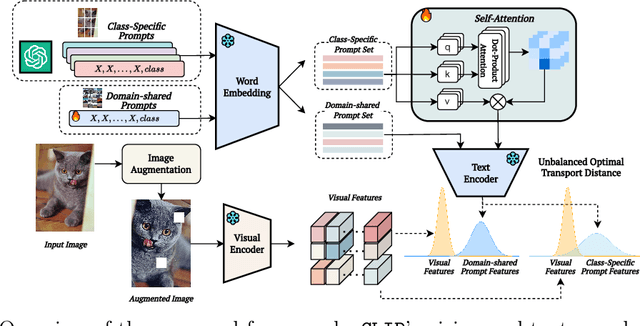
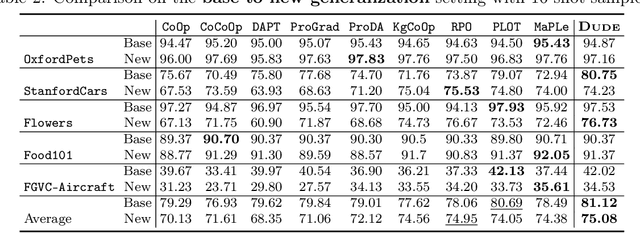
Prompt learning methods are gaining increasing attention due to their ability to customize large vision-language models to new domains using pre-trained contextual knowledge and minimal training data. However, existing works typically rely on optimizing unified prompt inputs, often struggling with fine-grained classification tasks due to insufficient discriminative attributes. To tackle this, we consider a new framework based on a dual context of both domain-shared and class-specific contexts, where the latter is generated by Large Language Models (LLMs) such as GPTs. Such dual prompt methods enhance the model's feature representation by joining implicit and explicit factors encoded in LLM knowledge. Moreover, we formulate the Unbalanced Optimal Transport (UOT) theory to quantify the relationships between constructed prompts and visual tokens. Through partial matching, UOT can properly align discrete sets of visual tokens and prompt embeddings under different mass distributions, which is particularly valuable for handling irrelevant or noisy elements, ensuring that the preservation of mass does not restrict transport solutions. Furthermore, UOT's characteristics integrate seamlessly with image augmentation, expanding the training sample pool while maintaining a reasonable distance between perturbed images and prompt inputs. Extensive experiments across few-shot classification and adapter settings substantiate the superiority of our model over current state-of-the-art baselines.
LVM-Med: Learning Large-Scale Self-Supervised Vision Models for Medical Imaging via Second-order Graph Matching
Jul 09, 2023



Obtaining large pre-trained models that can be fine-tuned to new tasks with limited annotated samples has remained an open challenge for medical imaging data. While pre-trained deep networks on ImageNet and vision-language foundation models trained on web-scale data are prevailing approaches, their effectiveness on medical tasks is limited due to the significant domain shift between natural and medical images. To bridge this gap, we introduce LVM-Med, the first family of deep networks trained on large-scale medical datasets. We have collected approximately 1.3 million medical images from 55 publicly available datasets, covering a large number of organs and modalities such as CT, MRI, X-ray, and Ultrasound. We benchmark several state-of-the-art self-supervised algorithms on this dataset and propose a novel self-supervised contrastive learning algorithm using a graph-matching formulation. The proposed approach makes three contributions: (i) it integrates prior pair-wise image similarity metrics based on local and global information; (ii) it captures the structural constraints of feature embeddings through a loss function constructed via a combinatorial graph-matching objective; and (iii) it can be trained efficiently end-to-end using modern gradient-estimation techniques for black-box solvers. We thoroughly evaluate the proposed LVM-Med on 15 downstream medical tasks ranging from segmentation and classification to object detection, and both for the in and out-of-distribution settings. LVM-Med empirically outperforms a number of state-of-the-art supervised, self-supervised, and foundation models. For challenging tasks such as Brain Tumor Classification or Diabetic Retinopathy Grading, LVM-Med improves previous vision-language models trained on 1 billion masks by 6-7% while using only a ResNet-50.