 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
ROCK: A variational formulation for occupation kernel methods in Reproducing Kernel Hilbert Spaces
Mar 18, 2025



We present a Representer Theorem result for a large class of weak formulation problems. We provide examples of applications of our formulation both in traditional machine learning and numerical methods as well as in new and emerging techniques. Finally we apply our formulation to generalize the multivariate occupation kernel (MOCK) method for learning dynamical systems from data proposing the more general Riesz Occupation Kernel (ROCK) method. Our generalized methods are both more computationally efficient and performant on most of the benchmarks we test against.
On Zero-Initialized Attention: Optimal Prompt and Gating Factor Estimation
Feb 05, 2025



The LLaMA-Adapter has recently emerged as an efficient fine-tuning technique for LLaMA models, leveraging zero-initialized attention to stabilize training and enhance performance. However, despite its empirical success, the theoretical foundations of zero-initialized attention remain largely unexplored. In this paper, we provide a rigorous theoretical analysis, establishing a connection between zero-initialized attention and mixture-of-expert models. We prove that both linear and non-linear prompts, along with gating functions, can be optimally estimated, with non-linear prompts offering greater flexibility for future applications. Empirically, we validate our findings on the open LLM benchmarks, demonstrating that non-linear prompts outperform linear ones. Notably, even with limited training data, both prompt types consistently surpass vanilla attention, highlighting the robustness and adaptability of zero-initialized attention.
RepLoRA: Reparameterizing Low-Rank Adaptation via the Perspective of Mixture of Experts
Feb 05, 2025Low-rank adaptation (LoRA) has emerged as a powerful method for fine-tuning large-scale foundation models. Despite its popularity, the theoretical understanding of LoRA has remained limited. This paper presents a theoretical analysis of LoRA by examining its connection to the Mixture of Experts models. Under this framework, we show that simple reparameterizations of the LoRA matrices can notably accelerate the low-rank matrix estimation process. In particular, we prove that reparameterization can reduce the data needed to achieve a desired estimation error from an exponential to a polynomial scale. Motivated by this insight, we propose Reparameterized Low-rank Adaptation (RepLoRA), which incorporates lightweight MLPs to reparameterize the LoRA matrices. Extensive experiments across multiple domains demonstrate that RepLoRA consistently outperforms vanilla LoRA. Notably, with limited data, RepLoRA surpasses LoRA by a margin of up to 40.0% and achieves LoRA's performance with only 30.0% of the training data, highlighting both the theoretical and empirical robustness of our PEFT method.
Adaptive Prompt: Unlocking the Power of Visual Prompt Tuning
Jan 31, 2025



Visual Prompt Tuning (VPT) has recently emerged as a powerful method for adapting pre-trained vision models to downstream tasks. By introducing learnable prompt tokens as task-specific instructions, VPT effectively guides pre-trained transformer models with minimal overhead. Despite its empirical success, a comprehensive theoretical understanding of VPT remains an active area of research. Building on recent insights into the connection between mixture of experts and prompt-based approaches, we identify a key limitation in VPT: the restricted functional expressiveness in prompt formulation. To address this limitation, we propose Visual Adaptive Prompt Tuning (VAPT), a new generation of prompts that redefines prompts as adaptive functions of the input. Our theoretical analysis shows that this simple yet intuitive approach achieves optimal sample efficiency. Empirical results on VTAB-1K and FGVC further demonstrate VAPT's effectiveness, with performance gains of 7.34% and 1.04% over fully fine-tuning baselines, respectively. Notably, VAPT also surpasses VPT by a substantial margin while using fewer parameters. These results highlight both the effectiveness and efficiency of our method and pave the way for future research to explore the potential of adaptive prompts.
Revisiting Prefix-tuning: Statistical Benefits of Reparameterization among Prompts
Oct 03, 2024



Prompt-based techniques, such as prompt-tuning and prefix-tuning, have gained prominence for their efficiency in fine-tuning large pre-trained models. Despite their widespread adoption, the theoretical foundations of these methods remain limited. For instance, in prefix-tuning, we observe that a key factor in achieving performance parity with full fine-tuning lies in the reparameterization strategy. However, the theoretical principles underpinning the effectiveness of this approach have yet to be thoroughly examined. Our study demonstrates that reparameterization is not merely an engineering trick but is grounded in deep theoretical foundations. Specifically, we show that the reparameterization strategy implicitly encodes a shared structure between prefix key and value vectors. Building on recent insights into the connection between prefix-tuning and mixture of experts models, we further illustrate that this shared structure significantly improves sample efficiency in parameter estimation compared to non-shared alternatives. The effectiveness of prefix-tuning across diverse tasks is empirically confirmed to be enhanced by the shared structure, through extensive experiments in both visual and language domains. Additionally, we uncover similar structural benefits in prompt-tuning, offering new perspectives on its success. Our findings provide theoretical and empirical contributions, advancing the understanding of prompt-based methods and their underlying mechanisms.
UlcerGPT: A Multimodal Approach Leveraging Large Language and Vision Models for Diabetic Foot Ulcer Image Transcription
Oct 02, 2024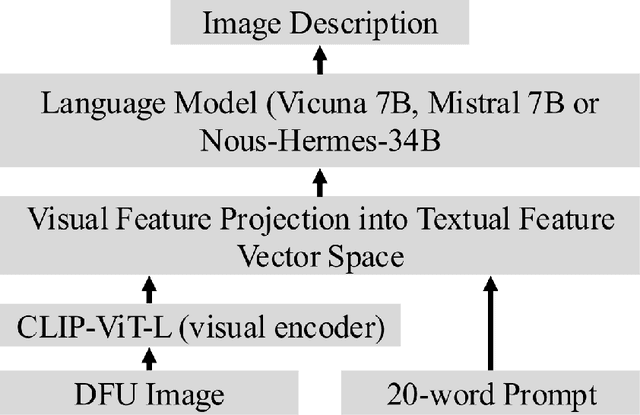

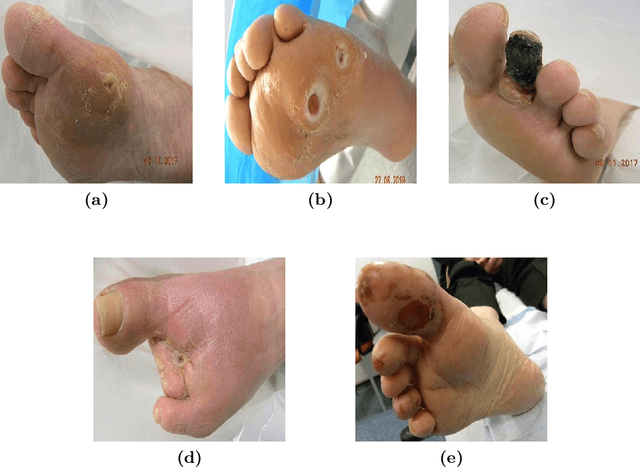
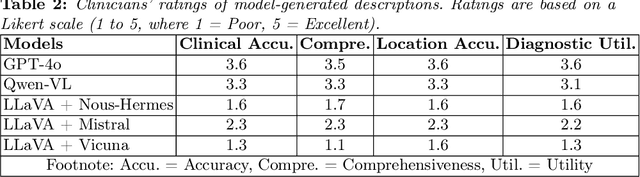
Diabetic foot ulcers (DFUs) are a leading cause of hospitalizations and lower limb amputations, placing a substantial burden on patients and healthcare systems. Early detection and accurate classification of DFUs are critical for preventing serious complications, yet many patients experience delays in receiving care due to limited access to specialized services. Telehealth has emerged as a promising solution, improving access to care and reducing the need for in-person visits. The integration of artificial intelligence and pattern recognition into telemedicine has further enhanced DFU management by enabling automatic detection, classification, and monitoring from images. Despite advancements in artificial intelligence-driven approaches for DFU image analysis, the application of large language models for DFU image transcription has not yet been explored. To address this gap, we introduce UlcerGPT, a novel multimodal approach leveraging large language and vision models for DFU image transcription. This framework combines advanced vision and language models, such as Large Language and Vision Assistant and Chat Generative Pre-trained Transformer, to transcribe DFU images by jointly detecting, classifying, and localizing regions of interest. Through detailed experiments on a public dataset, evaluated by expert clinicians, UlcerGPT demonstrates promising results in the accuracy and efficiency of DFU transcription, offering potential support for clinicians in delivering timely care via telemedicine.
Employing Label Models on ChatGPT Answers Improves Legal Text Entailment Performance
Jan 31, 2024The objective of legal text entailment is to ascertain whether the assertions in a legal query logically follow from the information provided in one or multiple legal articles. ChatGPT, a large language model, is robust in many natural language processing tasks, including legal text entailment: when we set the temperature = 0 (the ChatGPT answers are deterministic) and prompt the model, it achieves 70.64% accuracy on COLIEE 2022 dataset, which outperforms the previous SOTA of 67.89%. On the other hand, if the temperature is larger than zero, ChatGPT answers are not deterministic, leading to inconsistent answers and fluctuating results. We propose to leverage label models (a fundamental component of weak supervision techniques) to integrate the provisional answers by ChatGPT into consolidated labels. By that way, we treat ChatGPT provisional answers as noisy predictions which can be consolidated by label models. The experimental results demonstrate that this approach can attain an accuracy of 76.15%, marking a significant improvement of 8.26% over the prior state-of-the-art benchmark. Additionally, we perform an analysis of the instances where ChatGPT produces incorrect answers, then we classify the errors, offering insights that could guide potential enhancements for future research endeavors.
CAPTAIN at COLIEE 2023: Efficient Methods for Legal Information Retrieval and Entailment Tasks
Jan 07, 2024The Competition on Legal Information Extraction/Entailment (COLIEE) is held annually to encourage advancements in the automatic processing of legal texts. Processing legal documents is challenging due to the intricate structure and meaning of legal language. In this paper, we outline our strategies for tackling Task 2, Task 3, and Task 4 in the COLIEE 2023 competition. Our approach involved utilizing appropriate state-of-the-art deep learning methods, designing methods based on domain characteristics observation, and applying meticulous engineering practices and methodologies to the competition. As a result, our performance in these tasks has been outstanding, with first places in Task 2 and Task 3, and promising results in Task 4. Our source code is available at https://github.com/Nguyen2015/CAPTAIN-COLIEE2023/tree/coliee2023.
Real-Time Magnetic Tracking and Diagnosis of COVID-19 via Machine Learning
Nov 01, 2023



The COVID-19 pandemic underscored the importance of reliable, noninvasive diagnostic tools for robust public health interventions. In this work, we fused magnetic respiratory sensing technology (MRST) with machine learning (ML) to create a diagnostic platform for real-time tracking and diagnosis of COVID-19 and other respiratory diseases. The MRST precisely captures breathing patterns through three specific breath testing protocols: normal breath, holding breath, and deep breath. We collected breath data from both COVID-19 patients and healthy subjects in Vietnam using this platform, which then served to train and validate ML models. Our evaluation encompassed multiple ML algorithms, including support vector machines and deep learning models, assessing their ability to diagnose COVID-19. Our multi-model validation methodology ensures a thorough comparison and grants the adaptability to select the most optimal model, striking a balance between diagnostic precision with model interpretability. The findings highlight the exceptional potential of our diagnostic tool in pinpointing respiratory anomalies, achieving over 90% accuracy. This innovative sensor technology can be seamlessly integrated into healthcare settings for patient monitoring, marking a significant enhancement for the healthcare infrastructure.