 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
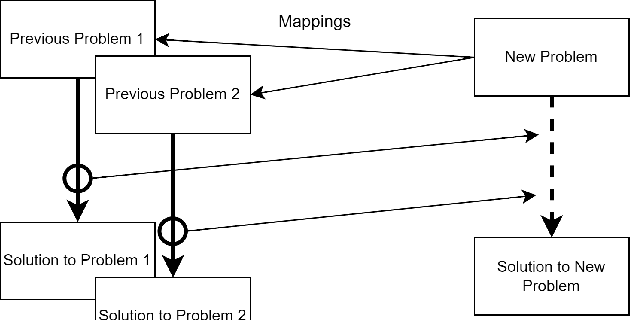
Add to EdgeLayer-of-Thoughts Prompting (LoT): Leveraging LLM-Based Retrieval with Constraint Hierarchies
Oct 16, 2024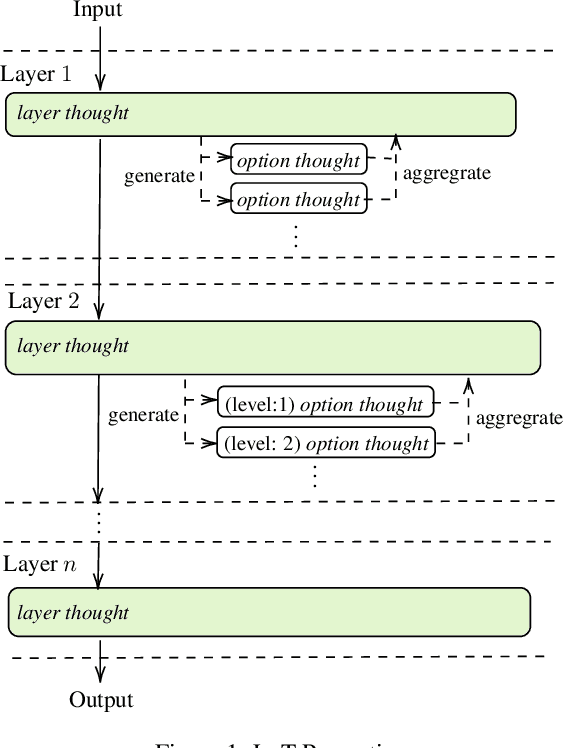
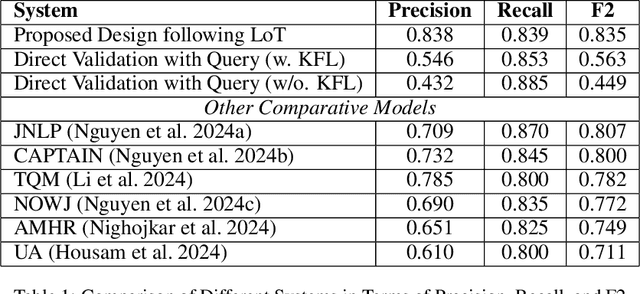
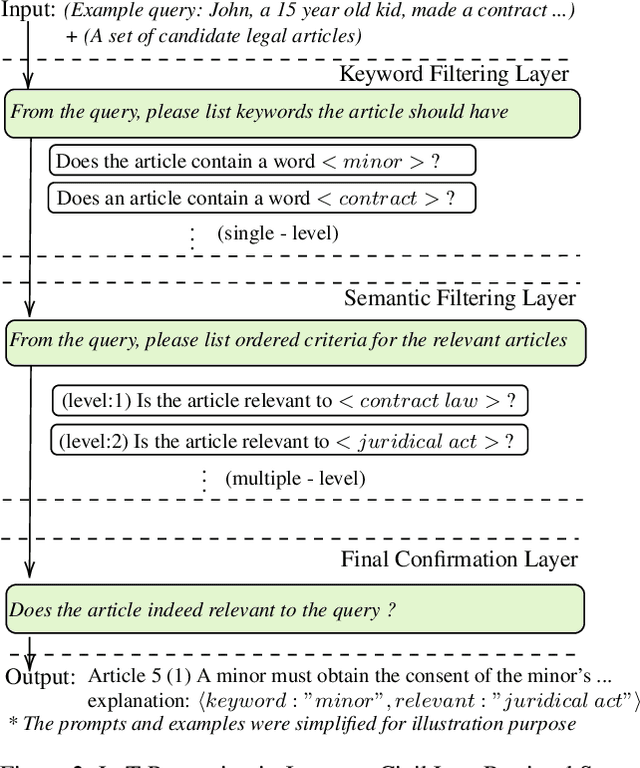
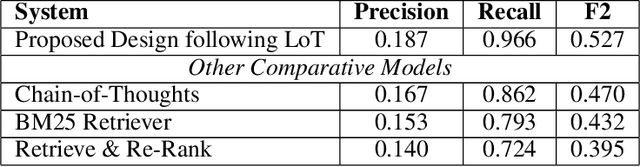
This paper presents a novel approach termed Layer-of-Thoughts Prompting (LoT), which utilizes constraint hierarchies to filter and refine candidate responses to a given query. By integrating these constraints, our method enables a structured retrieval process that enhances explainability and automation. Existing methods have explored various prompting techniques but often present overly generalized frameworks without delving into the nuances of prompts in multi-turn interactions. Our work addresses this gap by focusing on the hierarchical relationships among prompts. We demonstrate that the efficacy of thought hierarchy plays a critical role in developing efficient and interpretable retrieval algorithms. Leveraging Large Language Models (LLMs), LoT significantly improves the accuracy and comprehensibility of information retrieval tasks.
KRAG Framework for Enhancing LLMs in the Legal Domain
Oct 10, 2024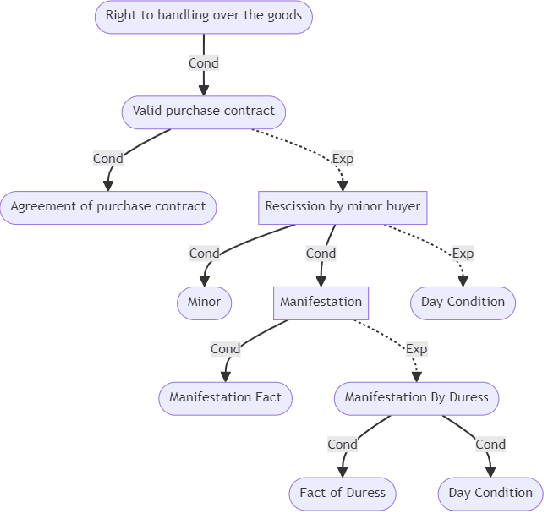
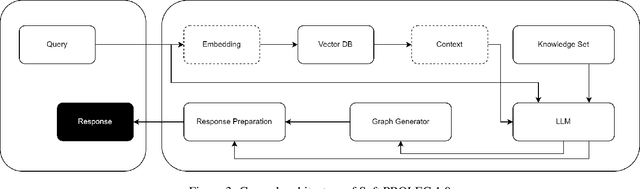

This paper introduces Knowledge Representation Augmented Generation (KRAG), a novel framework designed to enhance the capabilities of Large Language Models (LLMs) within domain-specific applications. KRAG points to the strategic inclusion of critical knowledge entities and relationships that are typically absent in standard data sets and which LLMs do not inherently learn. In the context of legal applications, we present Soft PROLEG, an implementation model under KRAG, which uses inference graphs to aid LLMs in delivering structured legal reasoning, argumentation, and explanations tailored to user inquiries. The integration of KRAG, either as a standalone framework or in tandem with retrieval augmented generation (RAG), markedly improves the ability of language models to navigate and solve the intricate challenges posed by legal texts and terminologies. This paper details KRAG's methodology, its implementation through Soft PROLEG, and potential broader applications, underscoring its significant role in advancing natural language understanding and processing in specialized knowledge domains.
Understanding Tieq Viet with Deep Learning Models
Jul 03, 2022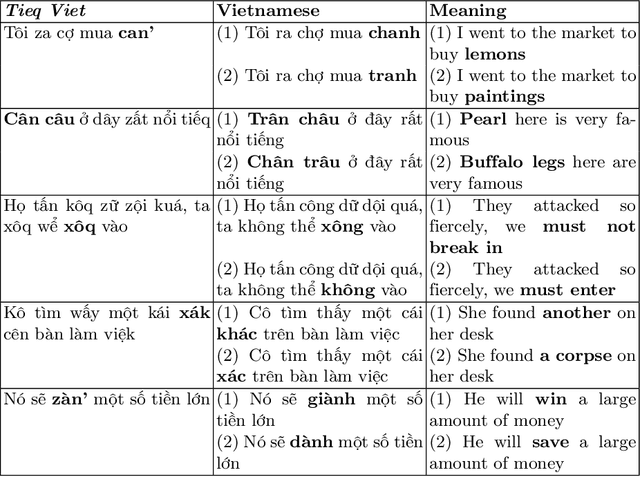
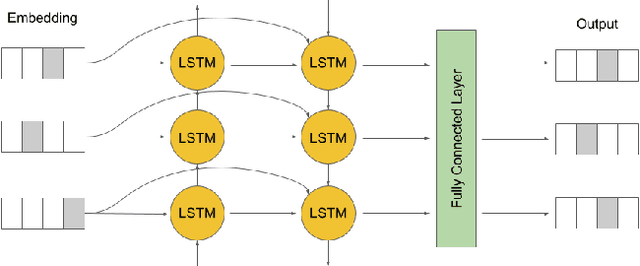

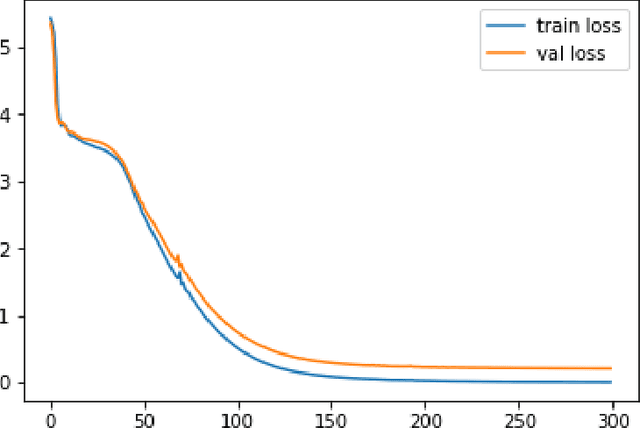
Deep learning is a powerful approach in recovering lost information as well as harder inverse function computation problems. When applied in natural language processing, this approach is essentially making use of context as a mean to recover information through likelihood maximization. Not long ago, a linguistic study called Tieq Viet was controversial among both researchers and society. We find this a great example to demonstrate the ability of deep learning models to recover lost information. In the proposal of Tieq Viet, some consonants in the standard Vietnamese are replaced. A sentence written in this proposal can be interpreted into multiple sentences in the standard version, with different meanings. The hypothesis that we want to test is whether a deep learning model can recover the lost information if we translate the text from Vietnamese to Tieq Viet.
A Summary of the ALQAC 2021 Competition
Apr 25, 2022


We summarize the evaluation of the first Automated Legal Question Answering Competition (ALQAC 2021). The competition this year contains three tasks, which aims at processing the statute law document, which are Legal Text Information Retrieval (Task 1), Legal Text Entailment Prediction (Task 2), and Legal Text Question Answering (Task 3). The final goal of these tasks is to build a system that can automatically determine whether a particular statement is lawful. There is no limit to the approaches of the participating teams. This year, there are 5 teams participating in Task 1, 6 teams participating in Task 2, and 5 teams participating in Task 3. There are in total 36 runs submitted to the organizer. In this paper, we summarize each team's approaches, official results, and some discussion about the competition. Only results of the teams who successfully submit their approach description paper are reported in this paper.