 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest It Before You Trust It: Applying Software Testing for Trustworthy In-context Learning
Apr 26, 2025



In-context learning (ICL) has emerged as a powerful capability of large language models (LLMs), enabling them to perform new tasks based on a few provided examples without explicit fine-tuning. Despite their impressive adaptability, these models remain vulnerable to subtle adversarial perturbations and exhibit unpredictable behavior when faced with linguistic variations. Inspired by software testing principles, we introduce a software testing-inspired framework, called MMT4NL, for evaluating the trustworthiness of in-context learning by utilizing adversarial perturbations and software testing techniques. It includes diverse evaluation aspects of linguistic capabilities for testing the ICL capabilities of LLMs. MMT4NL is built around the idea of crafting metamorphic adversarial examples from a test set in order to quantify and pinpoint bugs in the designed prompts of ICL. Our philosophy is to treat any LLM as software and validate its functionalities just like testing the software. Finally, we demonstrate applications of MMT4NL on the sentiment analysis and question-answering tasks. Our experiments could reveal various linguistic bugs in state-of-the-art LLMs.
A Decoupling and Aggregating Framework for Joint Extraction of Entities and Relations
May 14, 2024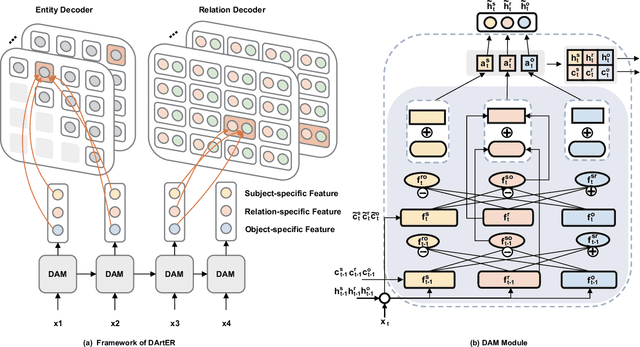
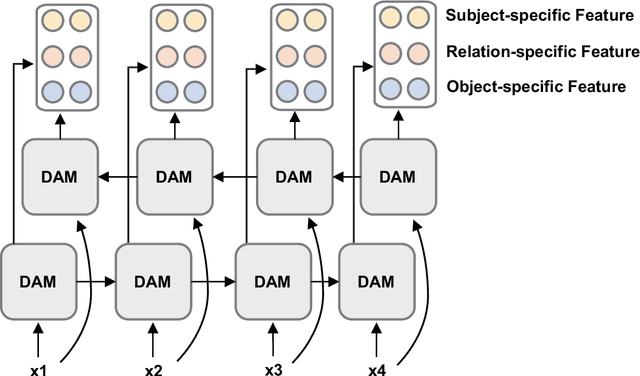
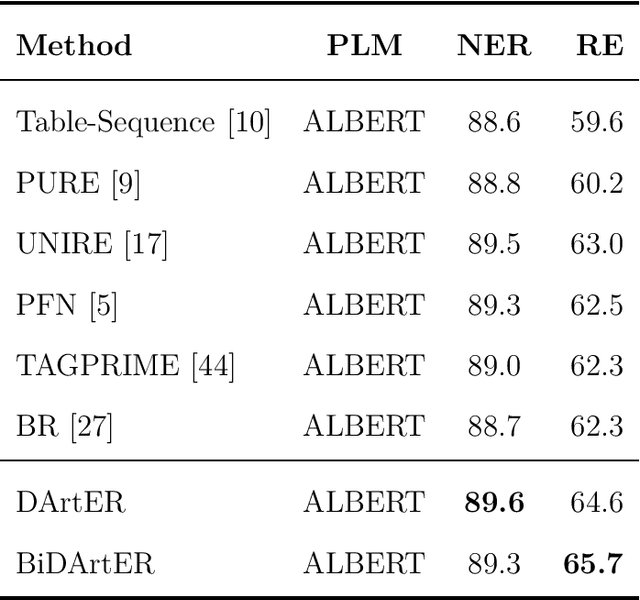
Named Entity Recognition and Relation Extraction are two crucial and challenging subtasks in the field of Information Extraction. Despite the successes achieved by the traditional approaches, fundamental research questions remain open. First, most recent studies use parameter sharing for a single subtask or shared features for both two subtasks, ignoring their semantic differences. Second, information interaction mainly focuses on the two subtasks, leaving the fine-grained informtion interaction among the subtask-specific features of encoding subjects, relations, and objects unexplored. Motivated by the aforementioned limitations, we propose a novel model to jointly extract entities and relations. The main novelties are as follows: (1) We propose to decouple the feature encoding process into three parts, namely encoding subjects, encoding objects, and encoding relations. Thanks to this, we are able to use fine-grained subtask-specific features. (2) We propose novel inter-aggregation and intra-aggregation strategies to enhance the information interaction and construct individual fine-grained subtask-specific features, respectively. The experimental results demonstrate that our model outperforms several previous state-of-the-art models. Extensive additional experiments further confirm the effectiveness of our model.
A Mutual Inclusion Mechanism for Precise Boundary Segmentation in Medical Images
Apr 12, 2024In medical imaging, accurate image segmentation is crucial for quantifying diseases, assessing prognosis, and evaluating treatment outcomes. However, existing methods lack an in-depth integration of global and local features, failing to pay special attention to abnormal regions and boundary details in medical images. To this end, we present a novel deep learning-based approach, MIPC-Net, for precise boundary segmentation in medical images. Our approach, inspired by radiologists' working patterns, features two distinct modules: (i) \textbf{Mutual Inclusion of Position and Channel Attention (MIPC) module}: To enhance the precision of boundary segmentation in medical images, we introduce the MIPC module, which enhances the focus on channel information when extracting position features and vice versa; (ii) \textbf{GL-MIPC-Residue}: To improve the restoration of medical images, we propose the GL-MIPC-Residue, a global residual connection that enhances the integration of the encoder and decoder by filtering out invalid information and restoring the most effective information lost during the feature extraction process. We evaluate the performance of the proposed model using metrics such as Dice coefficient (DSC) and Hausdorff Distance (HD) on three publicly accessible datasets: Synapse, ISIC2018-Task, and Segpc. Our ablation study shows that each module contributes to improving the quality of segmentation results. Furthermore, with the assistance of both modules, our approach outperforms state-of-the-art methods across all metrics on the benchmark datasets, notably achieving a 2.23mm reduction in HD on the Synapse dataset, strongly evidencing our model's enhanced capability for precise image boundary segmentation. Codes will be available at https://github.com/SUN-1024/MIPC-Net.
DA-TransUNet: Integrating Spatial and Channel Dual Attention with Transformer U-Net for Medical Image Segmentation
Oct 19, 2023Great progress has been made in automatic medical image segmentation due to powerful deep representation learning. The influence of transformer has led to research into its variants, and large-scale replacement of traditional CNN modules. However, such trend often overlooks the intrinsic feature extraction capabilities of the transformer and potential refinements to both the model and the transformer module through minor adjustments. This study proposes a novel deep medical image segmentation framework, called DA-TransUNet, aiming to introduce the Transformer and dual attention block into the encoder and decoder of the traditional U-shaped architecture. Unlike prior transformer-based solutions, our DA-TransUNet utilizes attention mechanism of transformer and multifaceted feature extraction of DA-Block, which can efficiently combine global, local, and multi-scale features to enhance medical image segmentation. Meanwhile, experimental results show that a dual attention block is added before the Transformer layer to facilitate feature extraction in the U-net structure. Furthermore, incorporating dual attention blocks in skip connections can enhance feature transfer to the decoder, thereby improving image segmentation performance. Experimental results across various benchmark of medical image segmentation reveal that DA-TransUNet significantly outperforms the state-of-the-art methods. The codes and parameters of our model will be publicly available at https://github.com/SUN-1024/DA-TransUnet.
A Summary of the ALQAC 2021 Competition
Apr 25, 2022


We summarize the evaluation of the first Automated Legal Question Answering Competition (ALQAC 2021). The competition this year contains three tasks, which aims at processing the statute law document, which are Legal Text Information Retrieval (Task 1), Legal Text Entailment Prediction (Task 2), and Legal Text Question Answering (Task 3). The final goal of these tasks is to build a system that can automatically determine whether a particular statement is lawful. There is no limit to the approaches of the participating teams. This year, there are 5 teams participating in Task 1, 6 teams participating in Task 2, and 5 teams participating in Task 3. There are in total 36 runs submitted to the organizer. In this paper, we summarize each team's approaches, official results, and some discussion about the competition. Only results of the teams who successfully submit their approach description paper are reported in this paper.