 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decoupling and Aggregating Framework for Joint Extraction of Entities and Relations
May 14, 2024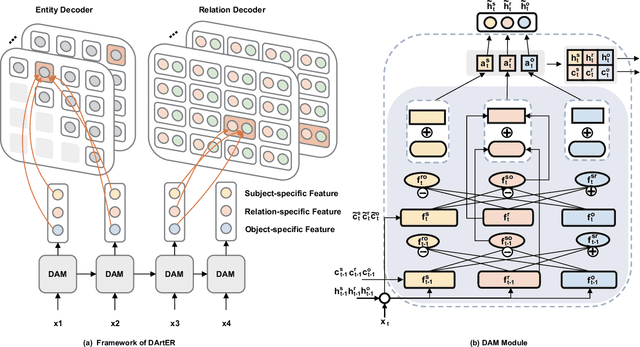
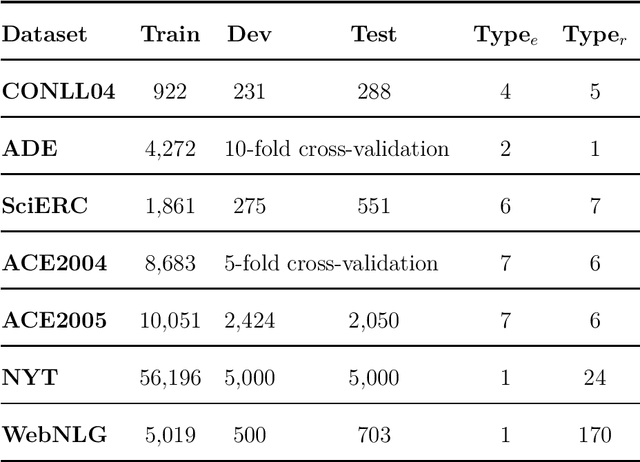
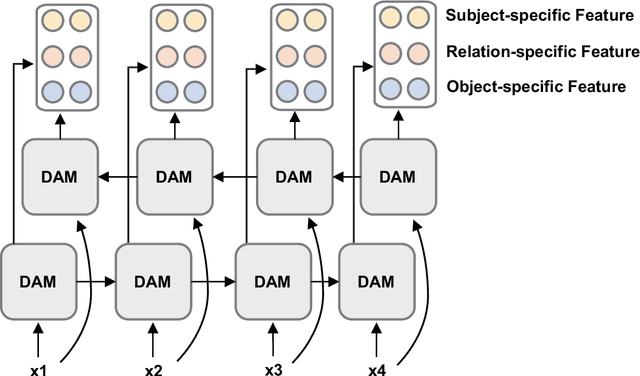
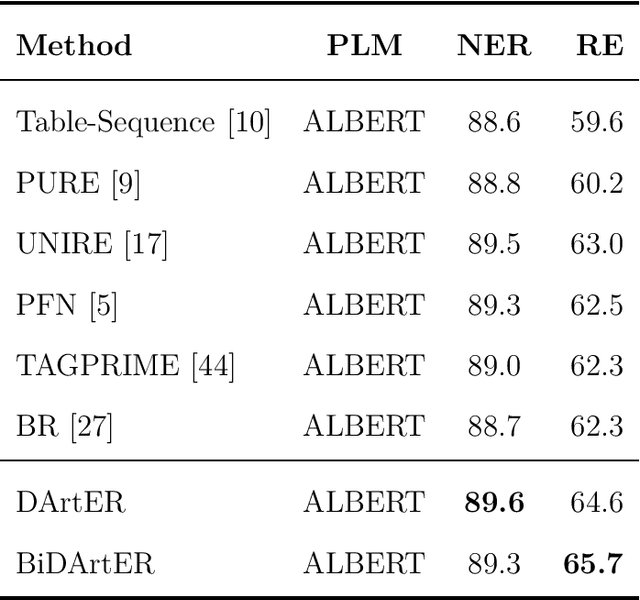
Named Entity Recognition and Relation Extraction are two crucial and challenging subtasks in the field of Information Extraction. Despite the successes achieved by the traditional approaches, fundamental research questions remain open. First, most recent studies use parameter sharing for a single subtask or shared features for both two subtasks, ignoring their semantic differences. Second, information interaction mainly focuses on the two subtasks, leaving the fine-grained informtion interaction among the subtask-specific features of encoding subjects, relations, and objects unexplored. Motivated by the aforementioned limitations, we propose a novel model to jointly extract entities and relations. The main novelties are as follows: (1) We propose to decouple the feature encoding process into three parts, namely encoding subjects, encoding objects, and encoding relations. Thanks to this, we are able to use fine-grained subtask-specific features. (2) We propose novel inter-aggregation and intra-aggregation strategies to enhance the information interaction and construct individual fine-grained subtask-specific features, respectively. The experimental results demonstrate that our model outperforms several previous state-of-the-art models. Extensive additional experiments further confirm the effectiveness of our model.
MM-Point: Multi-View Information-Enhanced Multi-Modal Self-Supervised 3D Point Cloud Understanding
Feb 25, 2024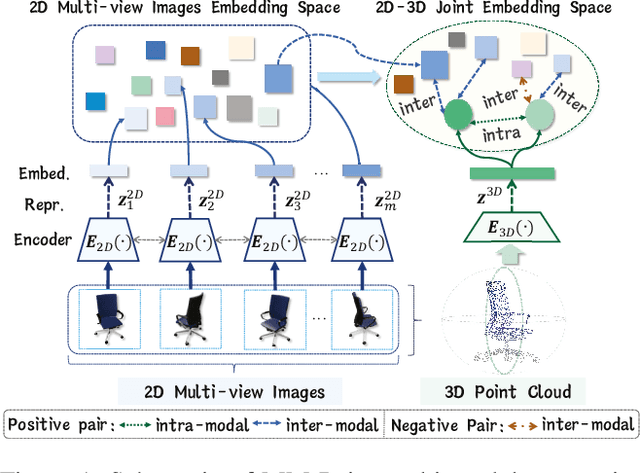
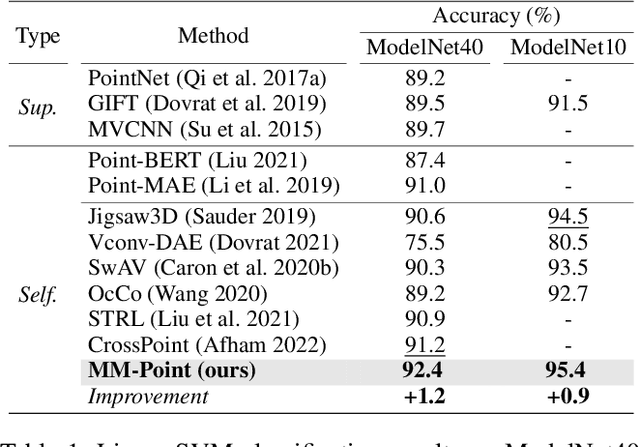
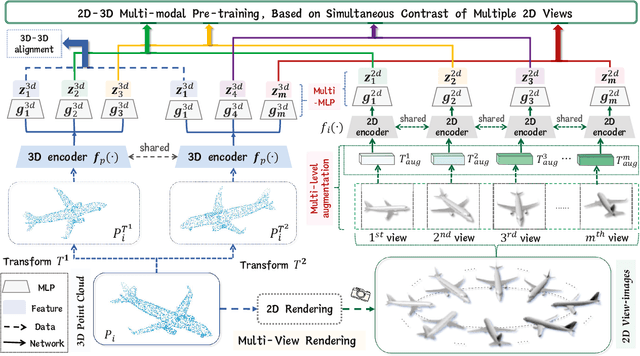
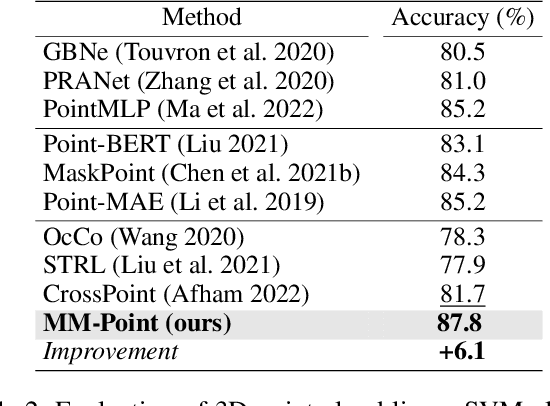
In perception, multiple sensory information is integrated to map visual information from 2D views onto 3D objects, which is beneficial for understanding in 3D environments. But in terms of a single 2D view rendered from different angles, only limited partial information can be provided.The richness and value of Multi-view 2D information can provide superior self-supervised signals for 3D objects. In this paper, we propose a novel self-supervised point cloud representation learning method, MM-Point, which is driven by intra-modal and inter-modal similarity objectives. The core of MM-Point lies in the Multi-modal interaction and transmission between 3D objects and multiple 2D views at the same time. In order to more effectively simultaneously perform the consistent cross-modal objective of 2D multi-view information based on contrastive learning, we further propose Multi-MLP and Multi-level Augmentation strategies. Through carefully designed transformation strategies, we further learn Multi-level invariance in 2D Multi-views. MM-Point demonstrates state-of-the-art (SOTA) performance in various downstream tasks. For instance, it achieves a peak accuracy of 92.4% on the synthetic dataset ModelNet40, and a top accuracy of 87.8% on the real-world dataset ScanObjectNN, comparable to fully supervised methods. Additionally, we demonstrate its effectiveness in tasks such as few-shot classification, 3D part segmentation and 3D semantic segmentation.
Combining Spiking Neural Network and Artificial Neural Network for Enhanced Image Classification
Feb 28, 2021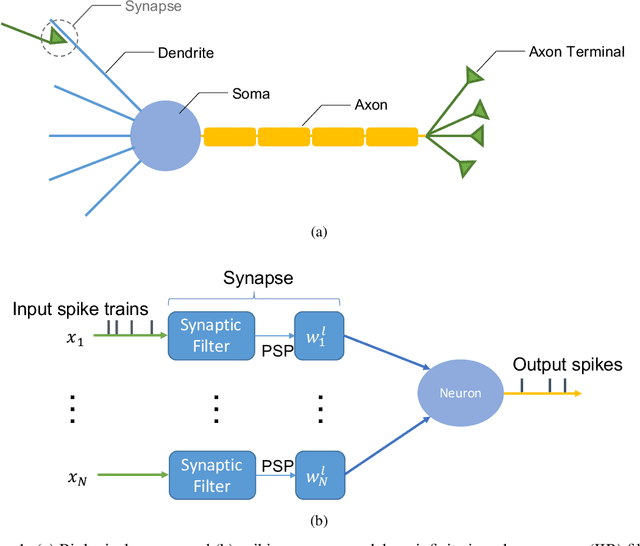
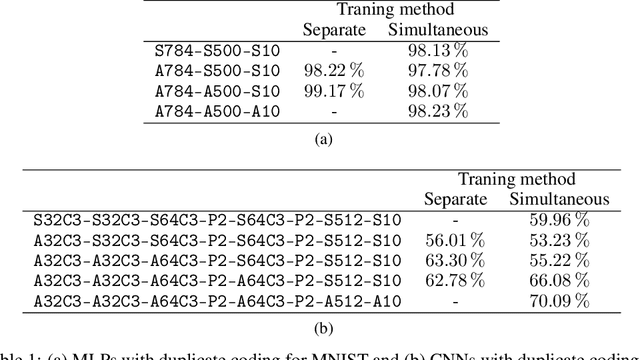
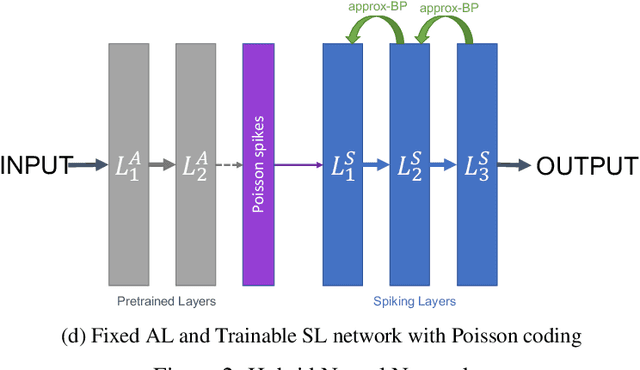

With the continued innovations of deep neural networks, spiking neural networks (SNNs) that more closely resemble biological brain synapses have attracted attention owing to their low power consumption.However, for continuous data values, they must employ a coding process to convert the values to spike trains.Thus, they have not yet exceeded the performance of artificial neural networks (ANNs), which handle such values directly.To this end, we combine an ANN and an SNN to build versatile hybrid neural networks (HNNs) that improve the concerned performance.To qualify this performance, MNIST and CIFAR-10 image datasets are used for various classification tasks in which the training and coding methods changes.In addition, we present simultaneous and separate methods to train the artificial and spiking layers, considering the coding methods of each.We find that increasing the number of artificial layers at the expense of spiking layers improves the HNN performance.For straightforward datasets such as MNIST, it is easy to achieve the same performance as ANNs by using duplicate coding and separate learning.However, for more complex tasks, the use of Gaussian coding and simultaneous learning is found to improve the accuracy of HNNs while utilizing a smaller number of artificial layers.