 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPR Auto-Formalization with AI Agents and Human Verification
Apr 16, 2026We study the overall process of automatic formalization of GDPR provisions using large language models, within a human-in-the-loop verification framework. Rather than aiming for full autonomy, we adopt a role-specialized workflow in which LLM-based AI components, operating in a multi-agent setting with iterative feedback, generate legal scenarios, formal rules, and atomic facts. This is coupled with independent verification modules which include human reviewers' assessment of representational, logical, and legal correctness. Using this approach, we construct a high-quality dataset to be used for GDPR auto-formalization, and analyze both successful and problematic cases. Our results show that structured verification and targeted human oversight are essential for reliable legal formalization, especially in the presence of legal nuance and context-sensitive reasoning.
Can Legislation Be Made Machine-Readable in PROLEG?
Jan 04, 2026The anticipated positive social impact of regulatory processes requires both the accuracy and efficiency of their application. Modern artificial intelligence technologies, including natural language processing and machine-assisted reasoning, hold great promise for addressing this challenge. We present a framework to address the challenge of tools for regulatory application, based on current state-of-the-art (SOTA) methods for natural language processing (large language models or LLMs) and formalization of legal reasoning (the legal representation system PROLEG). As an example, we focus on Article 6 of the European General Data Protection Regulation (GDPR). In our framework, a single LLM prompt simultaneously transforms legal text into if-then rules and a corresponding PROLEG encoding, which are then validated and refined by legal domain experts. The final output is an executable PROLEG program that can produce human-readable explanations for instances of GDPR decisions. We describe processes to support the end-to-end transformation of a segment of a regulatory document (Article 6 from GDPR), including the prompting frame to guide an LLM to "compile" natural language text to if-then rules, then to further "compile" the vetted if-then rules to PROLEG. Finally, we produce an instance that shows the PROLEG execution. We conclude by summarizing the value of this approach and note observed limitations with suggestions to further develop such technologies for capturing and deploying regulatory frameworks.
FC-CONAN: An Exhaustively Paired Dataset for Robust Evaluation of Retrieval Systems
Jan 04, 2026Hate speech (HS) is a critical issue in online discourse, and one promising strategy to counter it is through the use of counter-narratives (CNs). Datasets linking HS with CNs are essential for advancing counterspeech research. However, even flagship resources like CONAN (Chung et al., 2019) annotate only a sparse subset of all possible HS-CN pairs, limiting evaluation. We introduce FC-CONAN (Fully Connected CONAN), the first dataset created by exhaustively considering all combinations of 45 English HS messages and 129 CNs. A two-stage annotation process involving nine annotators and four validators produces four partitions-Diamond, Gold, Silver, and Bronze-that balance reliability and scale. None of the labeled pairs overlap with CONAN, uncovering hundreds of previously unlabelled positives. FC-CONAN enables more faithful evaluation of counterspeech retrieval systems and facilitates detailed error analysis. The dataset is publicly available.
Multi-Agent Legal Verifier Systems for Data Transfer Planning
Nov 14, 2025Legal compliance in AI-driven data transfer planning is becoming increasingly critical under stringent privacy regulations such as the Japanese Act on the Protection of Personal Information (APPI). We propose a multi-agent legal verifier that decomposes compliance checking into specialized agents for statutory interpretation, business context evaluation, and risk assessment, coordinated through a structured synthesis protocol. Evaluated on a stratified dataset of 200 Amended APPI Article 16 cases with clearly defined ground truth labels and multiple performance metrics, the system achieves 72% accuracy, which is 21 percentage points higher than a single-agent baseline, including 90% accuracy on clear compliance cases (vs. 16% for the baseline) while maintaining perfect detection of clear violations. While challenges remain in ambiguous scenarios, these results show that domain specialization and coordinated reasoning can meaningfully improve legal AI performance, providing a scalable and regulation-aware framework for trustworthy and interpretable automated compliance verification.
An Argumentative Explanation Framework for Generalized Reason Model with Inconsistent Precedents
Oct 22, 2025Precedential constraint is one foundation of case-based reasoning in AI and Law. It generally assumes that the underlying set of precedents must be consistent. To relax this assumption, a generalized notion of the reason model has been introduced. While several argumentative explanation approaches exist for reasoning with precedents based on the traditional consistent reason model, there has been no corresponding argumentative explanation method developed for this generalized reasoning framework accommodating inconsistent precedents. To address this question, this paper examines an extension of the derivation state argumentation framework (DSA-framework) to explain the reasoning according to the generalized notion of the reason model.
Layer-of-Thoughts Prompting (LoT): Leveraging LLM-Based Retrieval with Constraint Hierarchies
Oct 16, 2024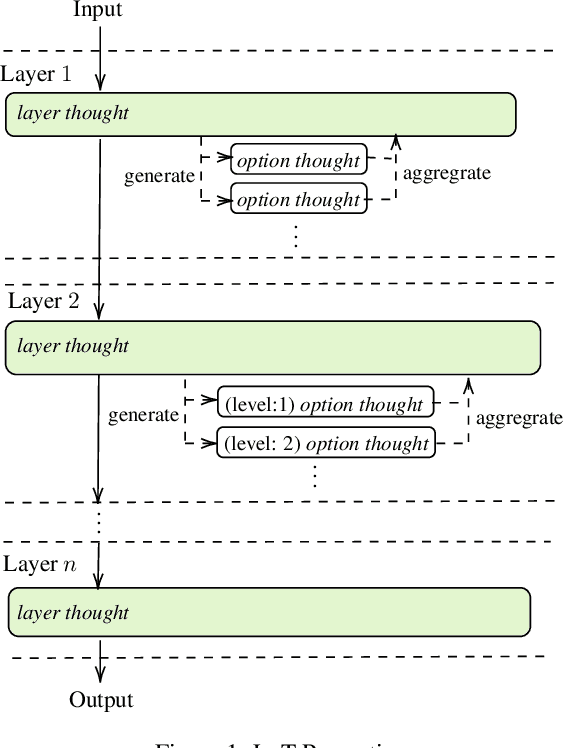
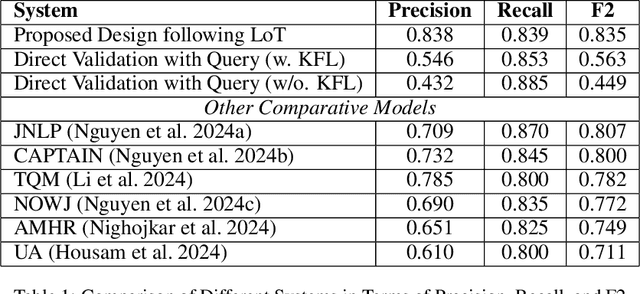
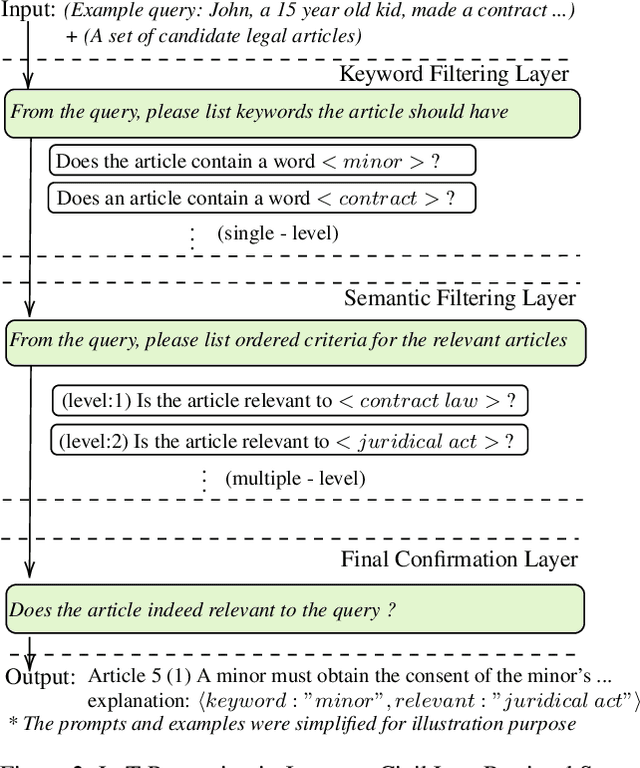
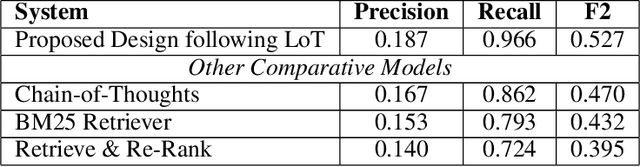
This paper presents a novel approach termed Layer-of-Thoughts Prompting (LoT), which utilizes constraint hierarchies to filter and refine candidate responses to a given query. By integrating these constraints, our method enables a structured retrieval process that enhances explainability and automation. Existing methods have explored various prompting techniques but often present overly generalized frameworks without delving into the nuances of prompts in multi-turn interactions. Our work addresses this gap by focusing on the hierarchical relationships among prompts. We demonstrate that the efficacy of thought hierarchy plays a critical role in developing efficient and interpretable retrieval algorithms. Leveraging Large Language Models (LLMs), LoT significantly improves the accuracy and comprehensibility of information retrieval tasks.
An Argumentative Approach for Explaining Preemption in Soft-Constraint Based Norms
Sep 06, 2024



Although various aspects of soft-constraint based norms have been explored, it is still challenging to understand preemption. Preemption is a situation where higher-level norms override lower-level norms when new information emerges. To address this, we propose a derivation state argumentation framework (DSA-framework). DSA-framework incorporates derivation states to explain how preemption arises based on evolving situational knowledge. Based on DSA-framework, we present an argumentative approach for explaining preemption. We formally prove that, under local optimality, DSA-framework can provide explanations why one consequence is obligatory or forbidden by soft-constraint based norms represented as logical constraint hierarchies.
Enhancing Logical Reasoning in Large Language Models to Facilitate Legal Applications
Nov 22, 2023Language serves as a vehicle for conveying thought, enabling communication among individuals. The ability to distinguish between diverse concepts, identify fairness and injustice, and comprehend a range of legal notions fundamentally relies on logical reasoning. Large Language Models (LLMs) attempt to emulate human language understanding and generation, but their competency in logical reasoning remains limited. This paper seeks to address the philosophical question: How can we effectively teach logical reasoning to LLMs while maintaining a deep understanding of the intricate relationship between language and logic? By focusing on bolstering LLMs' capabilities in logical reasoning, we aim to expand their applicability in law and other logic-intensive disciplines. To this end, we propose a Reinforcement Learning from Logical Feedback (RLLF) approach, which serves as a potential framework for refining LLMs' reasoning capacities. Through RLLF and a revised evaluation methodology, we explore new avenues for research in this domain and contribute to the development of LLMs capable of handling complex legal reasoning tasks while acknowledging the fundamental connection between language and logic.