 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Federated Learning to Quantum Federated Learning for Space-Air-Ground Integrated Networks
Nov 02, 2024


6G wireless networks are expected to provide seamless and data-based connections that cover space-air-ground and underwater networks. As a core partition of future 6G networks, Space-Air-Ground Integrated Networks (SAGIN) have been envisioned to provide countless real-time intelligent applications. To realize this, promoting AI techniques into SAGIN is an inevitable trend. Due to the distributed and heterogeneous architecture of SAGIN, federated learning (FL) and then quantum FL are emerging AI model training techniques for enabling future privacy-enhanced and computation-efficient SAGINs. In this work, we explore the vision of using FL/QFL in SAGINs. We present a few representative applications enabled by the integration of FL and QFL in SAGINs. A case study of QFL over UAV networks is also given, showing the merit of quantum-enabled training approach over the conventional FL benchmark. Research challenges along with standardization for QFL adoption in future SAGINs are also highlighted.
LoGra-Med: Long Context Multi-Graph Alignment for Medical Vision-Language Model
Oct 03, 2024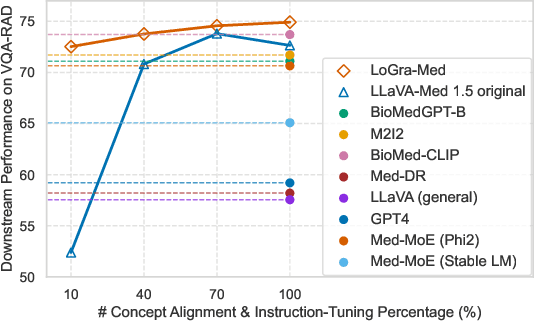
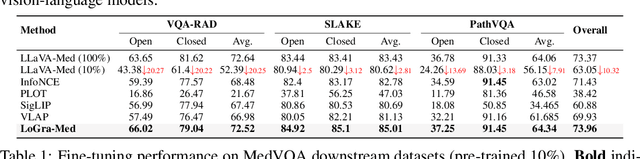
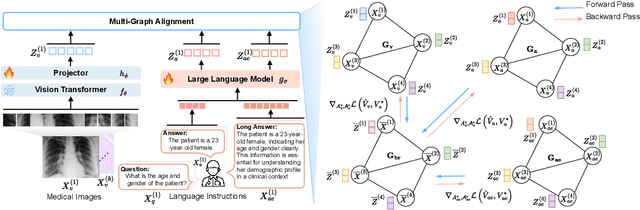
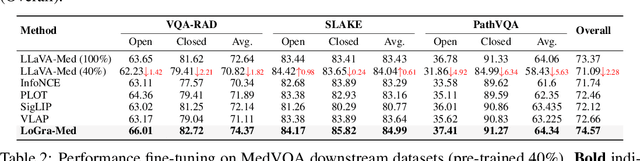
State-of-the-art medical multi-modal large language models (med-MLLM), like LLaVA-Med or BioMedGPT, leverage instruction-following data in pre-training. However, those models primarily focus on scaling the model size and data volume to boost performance while mainly relying on the autoregressive learning objectives. Surprisingly, we reveal that such learning schemes might result in a weak alignment between vision and language modalities, making these models highly reliant on extensive pre-training datasets - a significant challenge in medical domains due to the expensive and time-consuming nature of curating high-quality instruction-following instances. We address this with LoGra-Med, a new multi-graph alignment algorithm that enforces triplet correlations across image modalities, conversation-based descriptions, and extended captions. This helps the model capture contextual meaning, handle linguistic variability, and build cross-modal associations between visuals and text. To scale our approach, we designed an efficient end-to-end learning scheme using black-box gradient estimation, enabling faster LLaMa 7B training. Our results show LoGra-Med matches LLAVA-Med performance on 600K image-text pairs for Medical VQA and significantly outperforms it when trained on 10% of the data. For example, on VQA-RAD, we exceed LLAVA-Med by 20.13% and nearly match the 100% pre-training score (72.52% vs. 72.64%). We also surpass SOTA methods like BiomedGPT on visual chatbots and RadFM on zero-shot image classification with VQA, highlighting the effectiveness of multi-graph alignment.