 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating LLMs in Clinical Triage: Promising Capabilities, Persistent Intersectional Biases
Apr 22, 2025Large Language Models (LLMs) have shown promise in clinical decision support, yet their application to triage remains underexplored. We systematically investigate the capabilities of LLMs in emergency department triage through two key dimensions: (1) robustness to distribution shifts and missing data, and (2) counterfactual analysis of intersectional biases across sex and race. We assess multiple LLM-based approaches, ranging from continued pre-training to in-context learning, as well as machine learning approaches. Our results indicate that LLMs exhibit superior robustness, and we investigate the key factors contributing to the promising LLM-based approaches. Furthermore, in this setting, we identify gaps in LLM preferences that emerge in particular intersections of sex and race. LLMs generally exhibit sex-based differences, but they are most pronounced in certain racial groups. These findings suggest that LLMs encode demographic preferences that may emerge in specific clinical contexts or particular combinations of characteristics.
Knowledge-Driven Feature Selection and Engineering for Genotype Data with Large Language Models
Oct 02, 2024



Predicting phenotypes with complex genetic bases based on a small, interpretable set of variant features remains a challenging task. Conventionally, data-driven approaches are utilized for this task, yet the high dimensional nature of genotype data makes the analysis and prediction difficult. Motivated by the extensive knowledge encoded in pre-trained LLMs and their success in processing complex biomedical concepts, we set to examine the ability of LLMs in feature selection and engineering for tabular genotype data, with a novel knowledge-driven framework. We develop FREEFORM, Free-flow Reasoning and Ensembling for Enhanced Feature Output and Robust Modeling, designed with chain-of-thought and ensembling principles, to select and engineer features with the intrinsic knowledge of LLMs. Evaluated on two distinct genotype-phenotype datasets, genetic ancestry and hereditary hearing loss, we find this framework outperforms several data-driven methods, particularly on low-shot regimes. FREEFORM is available as open-source framework at GitHub: https://github.com/PennShenLab/FREEFORM.
Causality-based Subject and Task Fingerprints using fMRI Time-series Data
Sep 26, 2024Recently, there has been a revived interest in system neuroscience causation models due to their unique capability to unravel complex relationships in multi-scale brain networks. In this paper, our goal is to verify the feasibility and effectiveness of using a causality-based approach for fMRI fingerprinting. Specifically, we propose an innovative method that utilizes the causal dynamics activities of the brain to identify the unique cognitive patterns of individuals (e.g., subject fingerprint) and fMRI tasks (e.g., task fingerprint). The key novelty of our approach stems from the development of a two-timescale linear state-space model to extract 'spatio-temporal' (aka causal) signatures from an individual's fMRI time series data. To the best of our knowledge, we pioneer and subsequently quantify, in this paper, the concept of 'causal fingerprint.' Our method is well-separated from other fingerprint studies as we quantify fingerprints from a cause-and-effect perspective, which are then incorporated with a modal decomposition and projection method to perform subject identification and a GNN-based (Graph Neural Network) model to perform task identification. Finally, we show that the experimental results and comparisons with non-causality-based methods demonstrate the effectiveness of the proposed methods. We visualize the obtained causal signatures and discuss their biological relevance in light of the existing understanding of brain functionalities. Collectively, our work paves the way for further studies on causal fingerprints with potential applications in both healthy controls and neurodegenerative diseases.
Dude: Dual Distribution-Aware Context Prompt Learning For Large Vision-Language Model
Jul 05, 2024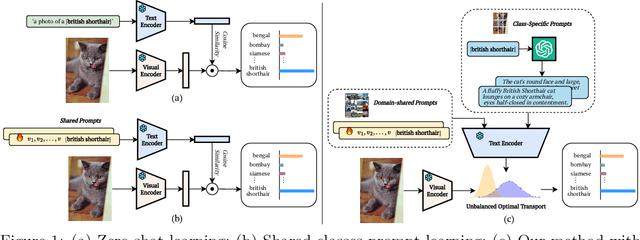
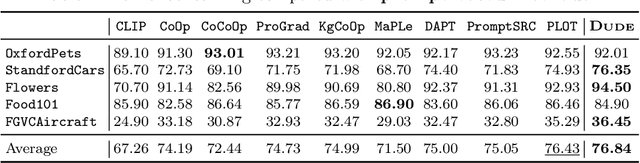
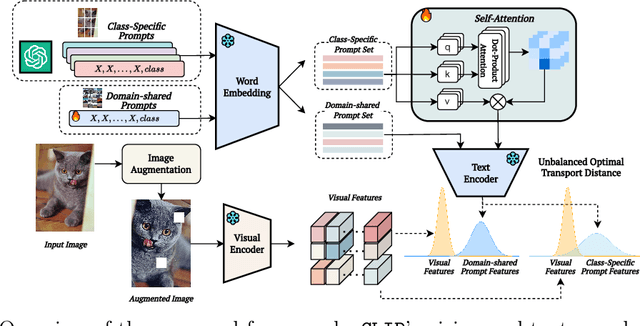
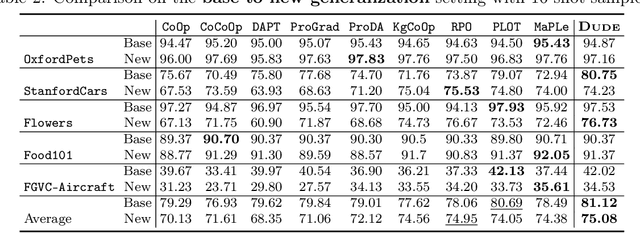
Prompt learning methods are gaining increasing attention due to their ability to customize large vision-language models to new domains using pre-trained contextual knowledge and minimal training data. However, existing works typically rely on optimizing unified prompt inputs, often struggling with fine-grained classification tasks due to insufficient discriminative attributes. To tackle this, we consider a new framework based on a dual context of both domain-shared and class-specific contexts, where the latter is generated by Large Language Models (LLMs) such as GPTs. Such dual prompt methods enhance the model's feature representation by joining implicit and explicit factors encoded in LLM knowledge. Moreover, we formulate the Unbalanced Optimal Transport (UOT) theory to quantify the relationships between constructed prompts and visual tokens. Through partial matching, UOT can properly align discrete sets of visual tokens and prompt embeddings under different mass distributions, which is particularly valuable for handling irrelevant or noisy elements, ensuring that the preservation of mass does not restrict transport solutions. Furthermore, UOT's characteristics integrate seamlessly with image augmentation, expanding the training sample pool while maintaining a reasonable distance between perturbed images and prompt inputs. Extensive experiments across few-shot classification and adapter settings substantiate the superiority of our model over current state-of-the-art baselines.
DALK: Dynamic Co-Augmentation of LLMs and KG to answer Alzheimer's Disease Questions with Scientific Literature
May 08, 2024



Recent advancements in large language models (LLMs) have achieved promising performances across various applications. Nonetheless, the ongoing challenge of integrating long-tail knowledge continues to impede the seamless adoption of LLMs in specialized domains. In this work, we introduce DALK, a.k.a. Dynamic Co-Augmentation of LLMs and KG, to address this limitation and demonstrate its ability on studying Alzheimer's Disease (AD), a specialized sub-field in biomedicine and a global health priority. With a synergized framework of LLM and KG mutually enhancing each other, we first leverage LLM to construct an evolving AD-specific knowledge graph (KG) sourced from AD-related scientific literature, and then we utilize a coarse-to-fine sampling method with a novel self-aware knowledge retrieval approach to select appropriate knowledge from the KG to augment LLM inference capabilities. The experimental results, conducted on our constructed AD question answering (ADQA) benchmark, underscore the efficacy of DALK. Additionally, we perform a series of detailed analyses that can offer valuable insights and guidelines for the emerging topic of mutually enhancing KG and LLM. We will release the code and data at https://github.com/David-Li0406/DALK.