Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou were saying? -- Spoken Language in the V3C Dataset
Paper and Code
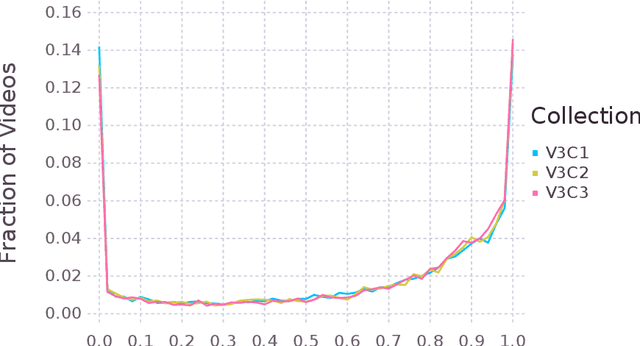


This paper presents an analysis of the distribution of spoken language in the V3C video retrieval benchmark dataset based on automatically generated transcripts. It finds that a large portion of the dataset is covered by spoken language. Since language transcripts can be quickly and accurately described, this has implications for retrieval tasks such as known-item search.
View paper on