 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtRAG: Retrieval-Augmented Generation with Structured Context for Visual Art Understanding
May 09, 2025Understanding visual art requires reasoning across multiple perspectives -- cultural, historical, and stylistic -- beyond mere object recognition. While recent multimodal large language models (MLLMs) perform well on general image captioning, they often fail to capture the nuanced interpretations that fine art demands. We propose ArtRAG, a novel, training-free framework that combines structured knowledge with retrieval-augmented generation (RAG) for multi-perspective artwork explanation. ArtRAG automatically constructs an Art Context Knowledge Graph (ACKG) from domain-specific textual sources, organizing entities such as artists, movements, themes, and historical events into a rich, interpretable graph. At inference time, a multi-granular structured retriever selects semantically and topologically relevant subgraphs to guide generation. This enables MLLMs to produce contextually grounded, culturally informed art descriptions. Experiments on the SemArt and Artpedia datasets show that ArtRAG outperforms several heavily trained baselines. Human evaluations further confirm that ArtRAG generates coherent, insightful, and culturally enriched interpretations.
Set2Seq Transformer: Learning Permutation Aware Set Representations of Artistic Sequences
Aug 06, 2024
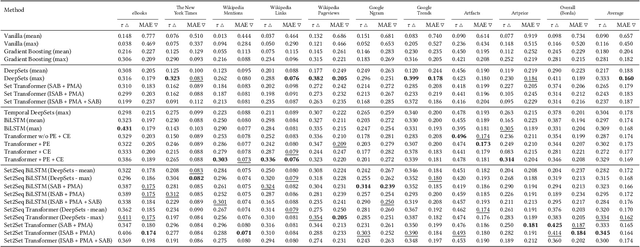
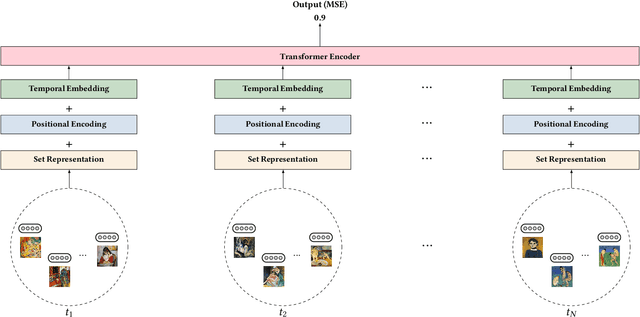
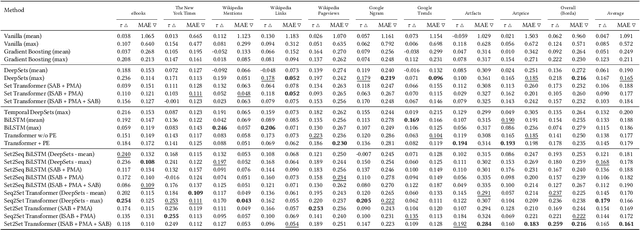
We propose Set2Seq Transformer, a novel sequential multiple instance architecture, that learns to rank permutation aware set representations of sequences. First, we illustrate that learning temporal position-aware representations of discrete timesteps can greatly improve static visual multiple instance learning methods that do not regard temporality and concentrate almost exclusively on visual content analysis. We further demonstrate the significant advantages of end-to-end sequential multiple instance learning, integrating visual content and temporal information in a multimodal manner. As application we focus on fine art analysis related tasks. To that end, we show that our Set2Seq Transformer can leverage visual set and temporal position-aware representations for modelling visual artists' oeuvres for predicting artistic success. Finally, through extensive quantitative and qualitative evaluation using a novel dataset, WikiArt-Seq2Rank, and a visual learning-to-rank downstream task, we show that our Set2Seq Transformer captures essential temporal information improving the performance of strong static and sequential multiple instance learning methods for predicting artistic success.
Ada-HGNN: Adaptive Sampling for Scalable Hypergraph Neural Networks
May 22, 2024Hypergraphs serve as an effective model for depicting complex connections in various real-world scenarios, from social to biological networks. The development of Hypergraph Neural Networks (HGNNs) has emerged as a valuable method to manage the intricate associations in data, though scalability is a notable challenge due to memory limitations. In this study, we introduce a new adaptive sampling strategy specifically designed for hypergraphs, which tackles their unique complexities in an efficient manner. We also present a Random Hyperedge Augmentation (RHA) technique and an additional Multilayer Perceptron (MLP) module to improve the robustness and generalization capabilities of our approach. Thorough experiments with real-world datasets have proven the effectiveness of our method, markedly reducing computational and memory demands while maintaining performance levels akin to conventional HGNNs and other baseline models. This research paves the way for improving both the scalability and efficacy of HGNNs in extensive applications. We will also make our codebase publicly accessible.
Prototype-Enhanced Hypergraph Learning for Heterogeneous Information Networks
Sep 22, 2023The variety and complexity of relations in multimedia data lead to Heterogeneous Information Networks (HINs). Capturing the semantics from such networks requires approaches capable of utilizing the full richness of the HINs. Existing methods for modeling HINs employ techniques originally designed for graph neural networks, and HINs decomposition analysis, like using manually predefined metapaths. In this paper, we introduce a novel prototype-enhanced hypergraph learning approach for node classification in HINs. Using hypergraphs instead of graphs, our method captures higher-order relationships among nodes and extracts semantic information without relying on metapaths. Our method leverages the power of prototypes to improve the robustness of the hypergraph learning process and creates the potential to provide human-interpretable insights into the underlying network structure. Extensive experiments on three real-world HINs demonstrate the effectiveness of our method.
Graph Neural Networks for Knowledge Enhanced Visual Representation of Paintings
May 17, 2021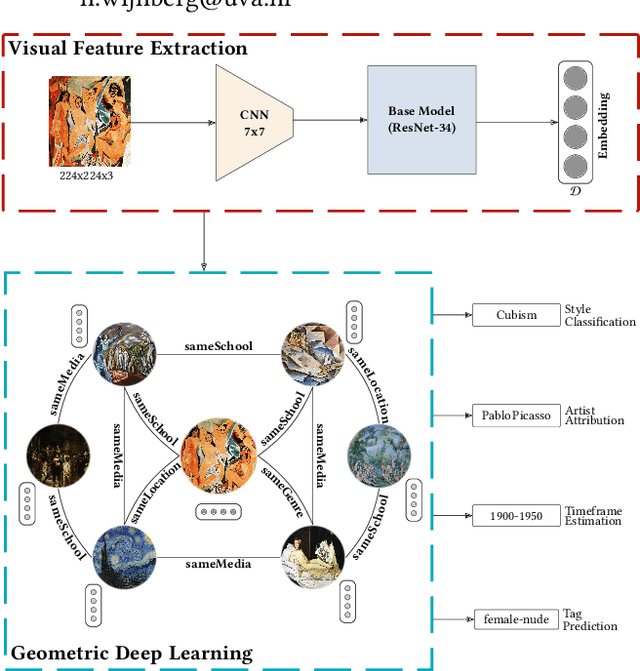
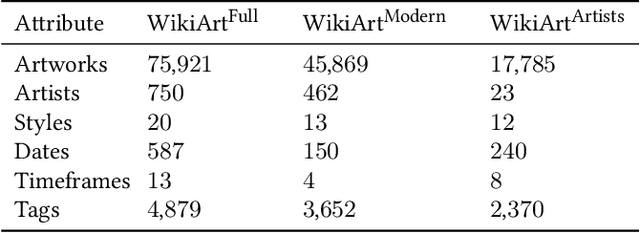
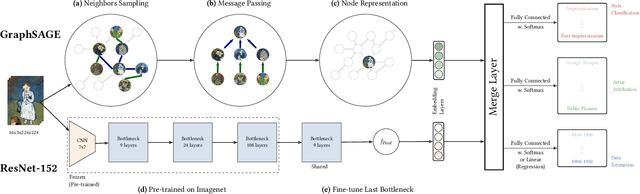
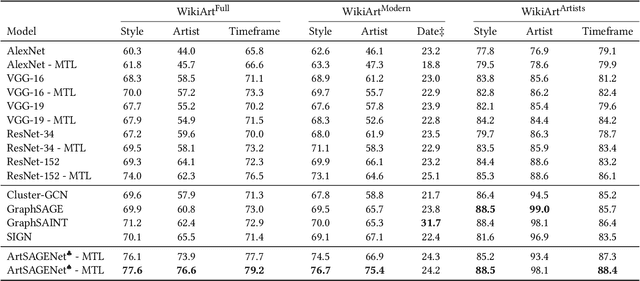
We propose ArtSAGENet, a novel multimodal architecture that integrates Graph Neural Networks (GNNs) and Convolutional Neural Networks (CNNs), to jointly learn visual and semantic-based artistic representations. First, we illustrate the significant advantages of multi-task learning for fine art analysis and argue that it is conceptually a much more appropriate setting in the fine art domain than the single-task alternatives. We further demonstrate that several GNN architectures can outperform strong CNN baselines in a range of fine art analysis tasks, such as style classification, artist attribution, creation period estimation, and tag prediction, while training them requires an order of magnitude less computational time and only a small amount of labeled data. Finally, through extensive experimentation we show that our proposed ArtSAGENet captures and encodes valuable relational dependencies between the artists and the artworks, surpassing the performance of traditional methods that rely solely on the analysis of visual content. Our findings underline a great potential of integrating visual content and semantics for fine art analysis and curation.