 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
Image Moment Invariants to Rotational Motion Blur
Mar 25, 2023
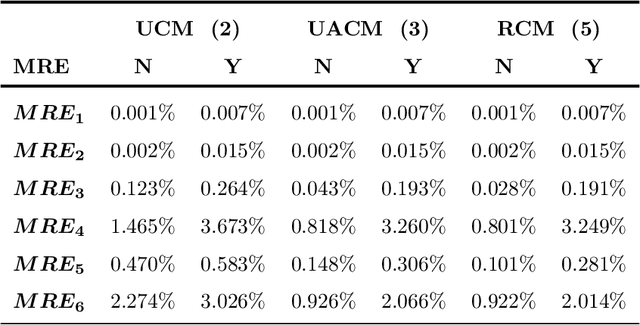
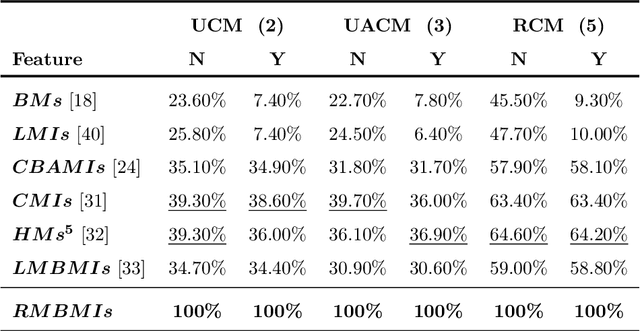

Rotational motion blur caused by the circular motion of the camera or/and object is common in life. Identifying objects from images affected by rotational motion blur is challenging because this image degradation severely impacts image quality. Therefore, it is meaningful to develop image invariant features under rotational motion blur and then use them in practical tasks, such as object classification and template matching. This paper proposes a novel method to generate image moment invariants under general rotational motion blur and provides some instances. Further, we achieve their invariance to similarity transform. To the best of our knowledge, this is the first time that moment invariants for rotational motion blur have been proposed in the literature. We conduct extensive experiments on various image datasets disturbed by similarity transform and rotational motion blur to test these invariants' numerical stability and robustness to image noise. We also demonstrate their performance in image classification and handwritten digit recognition. Current state-of-the-art blur moment invariants and deep neural networks are chosen for comparison. Our results show that the moment invariants proposed in this paper significantly outperform other features in various tasks.
SE-MoE: A Scalable and Efficient Mixture-of-Experts Distributed Training and Inference System
May 20, 2022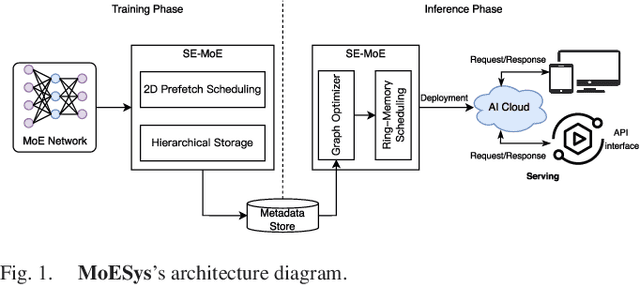
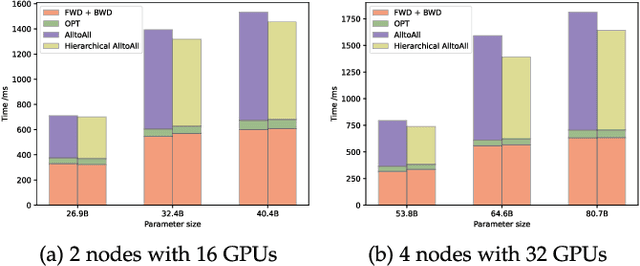
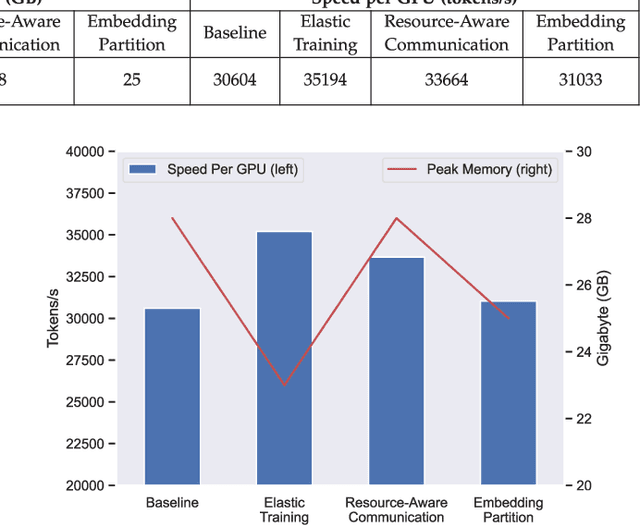
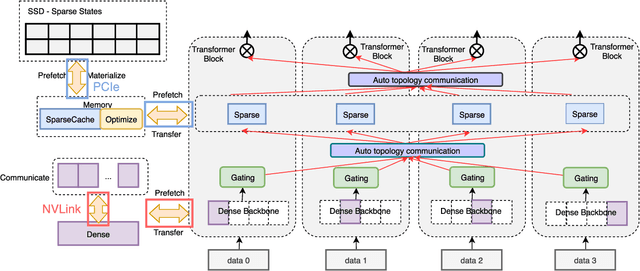
With the increasing diversity of ML infrastructures nowadays, distributed training over heterogeneous computing systems is desired to facilitate the production of big models. Mixture-of-Experts (MoE) models have been proposed to lower the cost of training subject to the overall size of models/data through gating and parallelism in a divide-and-conquer fashion. While DeepSpeed has made efforts in carrying out large-scale MoE training over heterogeneous infrastructures, the efficiency of training and inference could be further improved from several system aspects, including load balancing, communication/computation efficiency, and memory footprint limits. In this work, we present SE-MoE that proposes Elastic MoE training with 2D prefetch and Fusion communication over Hierarchical storage, so as to enjoy efficient parallelisms in various types. For scalable inference in a single node, especially when the model size is larger than GPU memory, SE-MoE forms the CPU-GPU memory jointly into a ring of sections to load the model, and executes the computation tasks across the memory sections in a round-robin manner for efficient inference. We carried out extensive experiments to evaluate SE-MoE, where SE-MoE successfully trains a Unified Feature Optimization (UFO) model with a Sparsely-Gated Mixture-of-Experts model of 12B parameters in 8 days on 48 A100 GPU cards. The comparison against the state-of-the-art shows that SE-MoE outperformed DeepSpeed with 33% higher throughput (tokens per second) in training and 13% higher throughput in inference in general. Particularly, under unbalanced MoE Tasks, e.g., UFO, SE-MoE achieved 64% higher throughput with 18% lower memory footprints. The code of the framework will be released on: https://github.com/PaddlePaddle/Paddle.
Spatio-Temporal Dual Affine Differential Invariant for Skeleton-based Action Recognition
Apr 21, 2020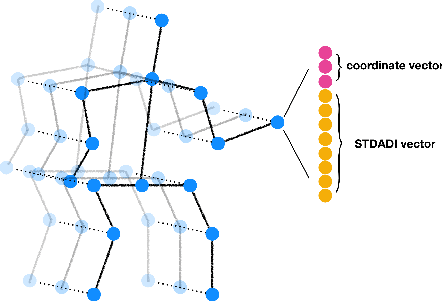
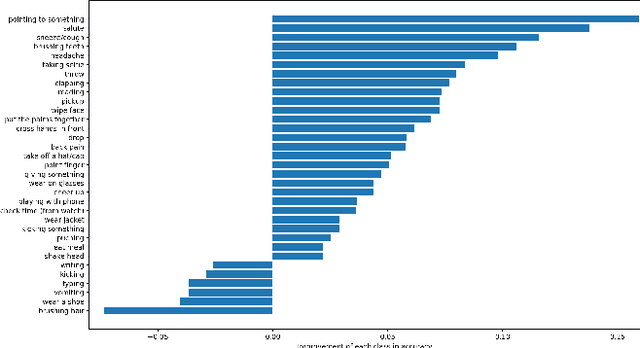
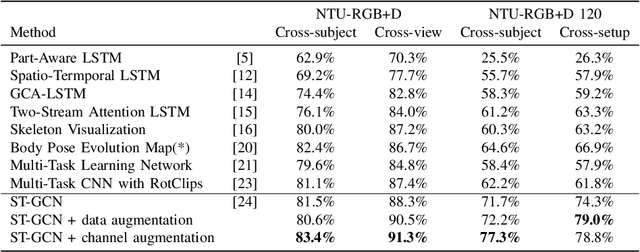
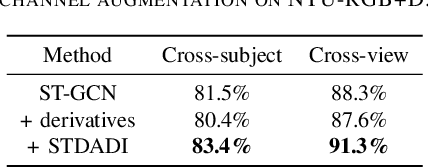
The dynamics of human skeletons have significant information for the task of action recognition. The similarity between trajectories of corresponding joints is an indicating feature of the same action, while this similarity may subject to some distortions that can be modeled as the combination of spatial and temporal affine transformations. In this work, we propose a novel feature called spatio-temporal dual affine differential invariant (STDADI). Furthermore, in order to improve the generalization ability of neural networks, a channel augmentation method is proposed. On the large scale action recognition dataset NTU-RGB+D, and its extended version NTU-RGB+D 120, it achieves remarkable improvements over previous state-of-the-art methods.