Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Dual Affine Differential Invariant for Skeleton-based Action Recognition
Paper and Code
Apr 21, 2020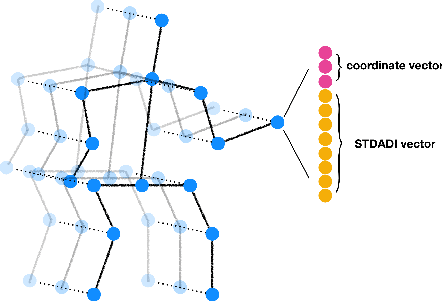
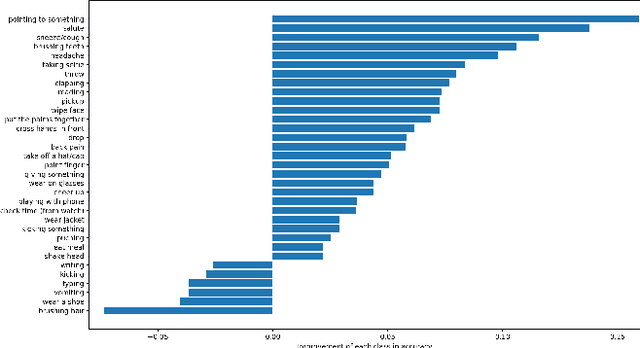
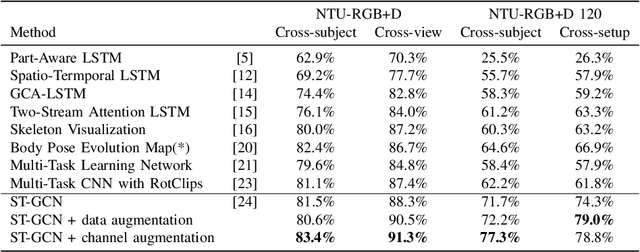
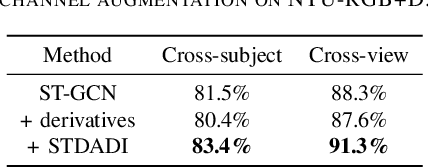
The dynamics of human skeletons have significant information for the task of action recognition. The similarity between trajectories of corresponding joints is an indicating feature of the same action, while this similarity may subject to some distortions that can be modeled as the combination of spatial and temporal affine transformations. In this work, we propose a novel feature called spatio-temporal dual affine differential invariant (STDADI). Furthermore, in order to improve the generalization ability of neural networks, a channel augmentation method is proposed. On the large scale action recognition dataset NTU-RGB+D, and its extended version NTU-RGB+D 120, it achieves remarkable improvements over previous state-of-the-art methods.
View paper on